Default Partitions In Spark . It works by applying a hash function to the keys and then dividing the hash. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. Hash partitioning is the default partitioning strategy in spark. By default, spark provides four. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value.
from medium.com
The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. It works by applying a hash function to the keys and then dividing the hash. Hash partitioning is the default partitioning strategy in spark. By default, spark provides four. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties.
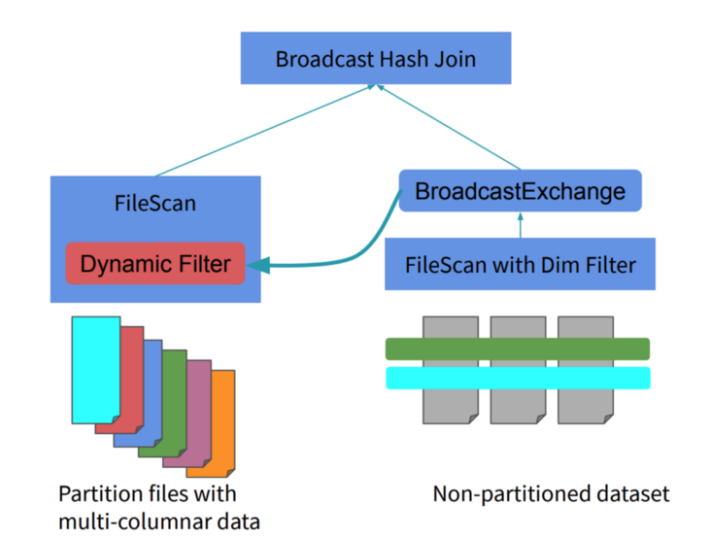
Dynamic Partition Pruning. Query performance optimization in Spark
Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark provides four. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. It works by applying a hash function to the keys and then dividing the hash. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. Hash partitioning is the default partitioning strategy in spark. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Default Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. Coalesce hints allow spark. Default Partitions In Spark.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Default Partitions In Spark The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then dividing the hash. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and. Default Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. By default, spark creates. Default Partitions In Spark.
From medium.com
Dynamic Partition Pruning. Query performance optimization in Spark Default Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. The default value of 200 for spark.sql.shuffle.partitions is a. Default Partitions In Spark.
From dzone.com
Dynamic Partition Pruning in Spark 3.0 DZone Default Partitions In Spark Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Hash partitioning is the default partitioning strategy in spark. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide. Default Partitions In Spark.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. By default, spark provides. Default Partitions In Spark.
From www.youtube.com
Why should we partition the data in spark? YouTube Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark provides four. Spark automatically. Default Partitions In Spark.
From www.youtube.com
Spark [Custom Partition] Implementation YouTube Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark provides four. Coalesce hints allow spark sql users to control the number of output files just like coalesce,. Default Partitions In Spark.
From discover.qubole.com
Introducing Dynamic Partition Pruning Optimization for Spark Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Hash partitioning is the default partitioning strategy in spark. It works by applying a hash function to the keys and then dividing the hash. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in. Default Partitions In Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Coalesce. Default Partitions In Spark.
From izhangzhihao.github.io
Spark The Definitive Guide In Short — MyNotes Default Partitions In Spark The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. The codec used. Default Partitions In Spark.
From blog.csdn.net
spark.sql.shuffle.partitions和spark.default.parallelism的深入理解_spark Default Partitions In Spark The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. The codec used to compress. Default Partitions In Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. By default, spark provides four. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark creates one partition. Default Partitions In Spark.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Default Partitions In Spark By default, spark provides four. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. It works by applying a hash function to the keys and then dividing the hash. By default, spark creates one. Default Partitions In Spark.
From sparkbyexamples.com
Difference between spark.sql.shuffle.partitions vs spark.default Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. Hash partitioning is. Default Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Default Partitions In Spark Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Spark. Default Partitions In Spark.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. It works by applying a hash function to the keys and then dividing the hash. Hash partitioning is the default partitioning strategy in spark. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in. Default Partitions In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. The codec used to. Default Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Default Partitions In Spark Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. By default, spark creates. Default Partitions In Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. Hash partitioning is the default partitioning strategy in spark. By default, spark provides four. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The default value of. Default Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Default Partitions In Spark By default, spark provides four. Hash partitioning is the default partitioning strategy in spark. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. It works by applying a. Default Partitions In Spark.
From blog.csdn.net
spark.sql.shuffle.partitions和spark.default.parallelism的深入理解_spark Default Partitions In Spark The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Hash partitioning is the default partitioning strategy in spark. Spark automatically triggers the shuffle when we perform aggregation and join operations on. Default Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark provides four. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. By default, spark creates one partition for each block of the file (blocks being. Default Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Partitions In Spark Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark provides four. Hash partitioning is the default partitioning strategy in spark. Spark automatically triggers the shuffle when we. Default Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Default Partitions In Spark Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. It works by applying a hash function to the keys and then dividing the hash. The default value of 200 for. Default Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark creates one partition for. Default Partitions In Spark.
From 0x0fff.com
Spark Architecture Shuffle Distributed Systems Architecture Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. Coalesce hints allow spark sql users to control the number of output files just like coalesce, repartition and repartitionbyrange in the. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The default. Default Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Partitions In Spark The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. Hash partitioning is the default partitioning strategy in spark. By default, spark creates one partition for each block of the file (blocks. Default Partitions In Spark.
From www.youtube.com
How to find Data skewness in spark / How to get count of rows from each Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark provides four. The codec used to compress internal data such as rdd partitions, event log, broadcast variables and shuffle outputs. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you. Default Partitions In Spark.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable parallelism without overwhelming the cluster. By default, spark. Default Partitions In Spark.
From medium.com
Managing Spark Partitions. How data is partitioned and when do you Default Partitions In Spark By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. It works by applying a hash function to the keys and then dividing the hash. Hash partitioning is the default partitioning strategy in spark. The default value of 200 for spark.sql.shuffle.partitions is a middle ground intended to provide reasonable. Default Partitions In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. By default, spark provides four. By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs),. Default Partitions In Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark Default Partitions In Spark By default, spark creates one partition for each block of the file (blocks being 128mb by default in hdfs), but you can also ask for a higher number of partitions by passing a larger value. It works by applying a hash function to the keys and then dividing the hash. The codec used to compress internal data such as rdd. Default Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Default Partitions In Spark It works by applying a hash function to the keys and then dividing the hash. Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. The codec used to compress internal data such. Default Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Default Partitions In Spark Spark automatically triggers the shuffle when we perform aggregation and join operations on rdd and dataframe. By default, spark creates one partition for each block of a file and can be configured with spark.default.parallelism and spark.sql.shuffle.partitions properties. It works by applying a hash function to the keys and then dividing the hash. By default, spark provides four. The codec used. Default Partitions In Spark.