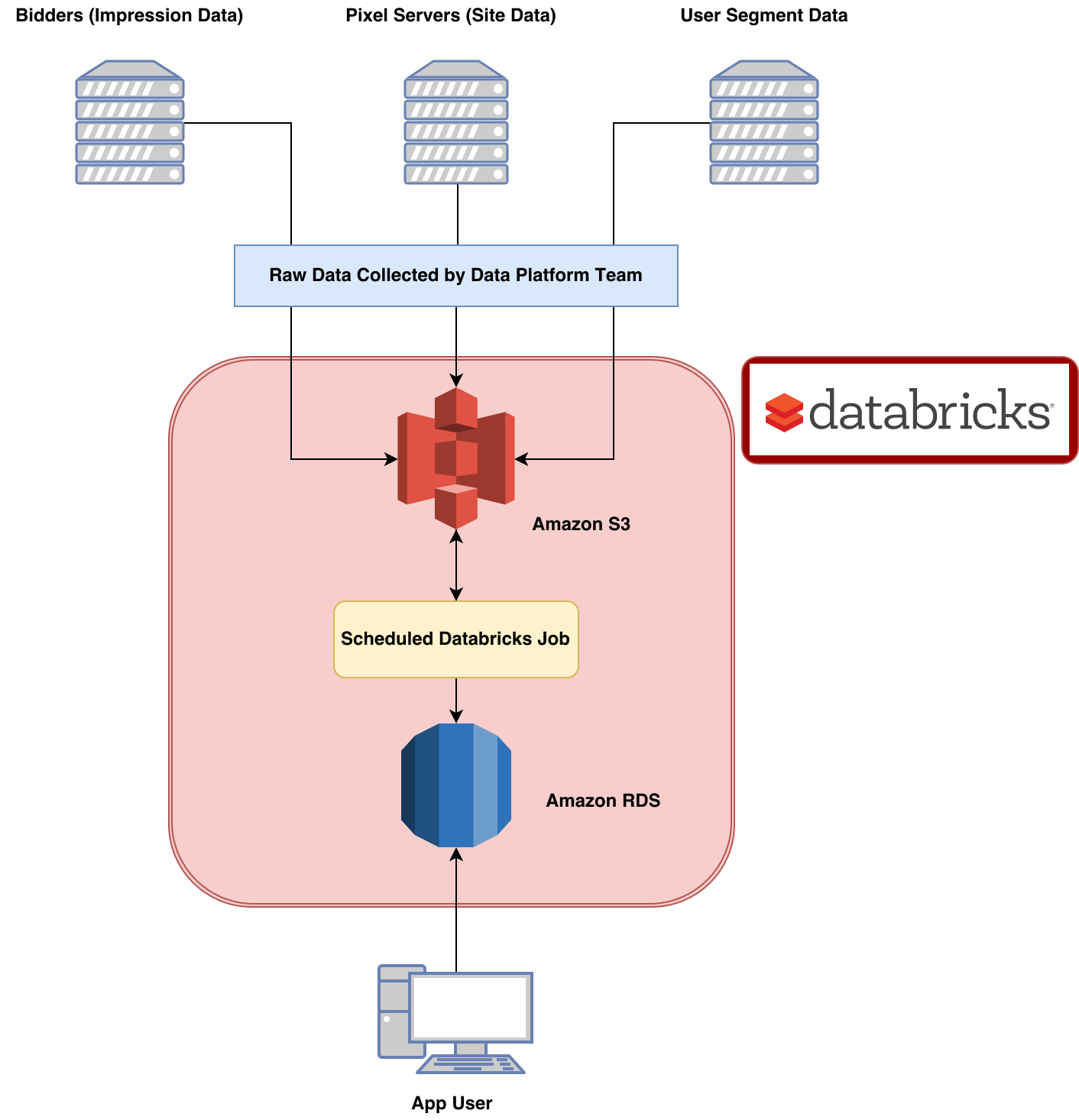
Databricks Partition Over . Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Implement liquid clustering to simplify data layout decisions and optimize query performance. The over clause of the window function must include an order by clause. Unlike the function dense_rank , rank will produce gaps in the ranking. The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. In snowflake i get the following results. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables.
from laptrinhx.com
Unlike the function dense_rank , rank will produce gaps in the ranking. This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. Implement liquid clustering to simplify data layout decisions and optimize query performance. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. The over clause of the window function must include an order by clause. In snowflake i get the following results. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates.
Take Reports From Concept to Production with PySpark and Databricks
Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. Unlike the function dense_rank , rank will produce gaps in the ranking. In snowflake i get the following results. This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Implement liquid clustering to simplify data layout decisions and optimize query performance. The over clause of the window function must include an order by clause.
From amandeep-singh-johar.medium.com
Maximizing Performance and Efficiency with Databricks ZOrdering Databricks Partition Over Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. The window frame clause specifies a sliding subset of rows within the partition on which. Databricks Partition Over.
From hevodata.com
A QuickStart Guide to Databricks Kafka Integration 5 Comprehensive Databricks Partition Over In snowflake i get the following results. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Unlike the function dense_rank , rank will produce. Databricks Partition Over.
From subscription.packtpub.com
Vertical partitioning MySQL 8 for Big Data Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. The over clause of the window function must include an order by clause. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Unlike the function dense_rank , rank will produce gaps in the ranking. The window frame clause specifies. Databricks Partition Over.
From www.databricks.com
Cost Effective and Secure Data Sharing The Advantages of Leveraging Databricks Partition Over Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. In snowflake i get the following results. Implement liquid clustering to simplify data layout decisions and optimize query performance. The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. Unlike the. Databricks Partition Over.
From www.databricks.com
Cost Effective and Secure Data Sharing The Advantages of Leveraging Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Implement liquid clustering to simplify data layout decisions and optimize query performance. Unlike the function dense_rank , rank will produce gaps in. Databricks Partition Over.
From www.youtube.com
Dynamic Partition Pruning in Apache Spark Bogdan Ghit Databricks Databricks Partition Over The over clause of the window function must include an order by clause. Implement liquid clustering to simplify data layout decisions and optimize query performance. Unlike the function dense_rank , rank will produce gaps in the ranking. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20),. Databricks Partition Over.
From www.linkedin.com
How to orchestrate MLOps by using Azure Databricks? Databricks Partition Over The over clause of the window function must include an order by clause. This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. A partition is composed of a. Databricks Partition Over.
From www.graphable.ai
Databricks Architecture A Concise Explanation Databricks Partition Over Unlike the function dense_rank , rank will produce gaps in the ranking. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Implement liquid clustering. Databricks Partition Over.
From www.databricks.com
Serverless Continuous Delivery with Databricks and AWS CodePipeline Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. The over clause of the window function must include an order by clause. In snowflake i get the following results. Select col1,. Databricks Partition Over.
From docs.microsoft.com
Stream processing with Databricks Azure Reference Architectures Databricks Partition Over Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); The over clause of the window function must include an order by clause. Unlike the function dense_rank , rank will produce gaps in the ranking. Learn how to use replacewhere and dynamic partition. Databricks Partition Over.
From exoxwqtpl.blob.core.windows.net
Partition Table Databricks at Jamie Purington blog Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. The over clause of the window function must include an order by clause. This article provides an overview of how you can partition tables on azure databricks and specific recommendations. Databricks Partition Over.
From www.confluent.io
Databricks Databricks Partition Over The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. In snowflake i get the following results. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Select col1, col2, last_value(col2) over (partition. Databricks Partition Over.
From www.databricks.com
Orchestrate Databricks on AWS with Airflow Databricks Blog Databricks Partition Over In snowflake i get the following results. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22);. Databricks Partition Over.
From www.databricks.com
Cost Effective and Secure Data Sharing The Advantages of Leveraging Databricks Partition Over A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. The over clause of the window function must include an order by clause. Unlike the function dense_rank , rank will produce gaps in the ranking. Select col1, col2, last_value(col2) over (partition by col1 order. Databricks Partition Over.
From www.youtube.com
Partitions in Data bricks YouTube Databricks Partition Over Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Unlike the function dense_rank , rank will. Databricks Partition Over.
From www.cockroachlabs.com
What is data partitioning, and how to do it right Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of. Databricks Partition Over.
From docs.gathr.one
Databricks Clusters Gathr Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Select col1, col2, last_value(col2). Databricks Partition Over.
From www.databricks.com
Introducing Databricks Workflows The Databricks Blog Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); Implement liquid clustering to simplify data layout decisions and optimize query performance. Learn. Databricks Partition Over.
From www.youtube.com
Visualizations in Databricks YouTube Databricks Partition Over A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. In snowflake i get the following results. Implement liquid clustering to simplify data layout decisions and optimize query performance. The window frame clause specifies a sliding subset of rows within the partition on which. Databricks Partition Over.
From exoxwqtpl.blob.core.windows.net
Partition Table Databricks at Jamie Purington blog Databricks Partition Over Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. The over clause of the window function must include an order by clause. A partition is composed of a subset of rows. Databricks Partition Over.
From www.cloudiqtech.com
Partition, Optimize and ZORDER Delta Tables in Azure Databricks Databricks Partition Over Unlike the function dense_rank , rank will produce gaps in the ranking. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates.. Databricks Partition Over.
From hackolade.com
Databricks Data Modeling Tool Hackolade Studio Databricks Partition Over A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. In snowflake i get the following results. Select col1, col2, last_value(col2) over (partition by col1 order. Databricks Partition Over.
From exolwjxvu.blob.core.windows.net
Partition Key Databricks at Cathy Dalzell blog Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); In snowflake i get the following results. This article provides an overview of how you can partition tables on azure databricks. Databricks Partition Over.
From docs.databricks.com
Partition discovery for external tables Databricks on AWS Databricks Partition Over Implement liquid clustering to simplify data layout decisions and optimize query performance. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. The over clause of the window function must include an order by clause. In snowflake i get the following results. Learn how. Databricks Partition Over.
From exolwjxvu.blob.core.windows.net
Partition Key Databricks at Cathy Dalzell blog Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); The over clause of the window function must include an order by clause.. Databricks Partition Over.
From www.linkedin.com
Databricks SQL How (not) to partition your way out of performance Databricks Partition Over Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Unlike the function dense_rank , rank will produce gaps in the ranking. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22); The over clause. Databricks Partition Over.
From laptrinhx.com
Take Reports From Concept to Production with PySpark and Databricks Databricks Partition Over In snowflake i get the following results. The over clause of the window function must include an order by clause. Implement liquid clustering to simplify data layout decisions and optimize query performance. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Select col1, col2, last_value(col2) over (partition by col1 order by. Databricks Partition Over.
From stackoverflow.com
How to parallelly merge data into partitions of databricks delta table Databricks Partition Over A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. The over clause of the window function must include an order by clause. In snowflake i get the following results. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from. Databricks Partition Over.
From azurelib.com
How to partition records in PySpark Azure Databricks? Databricks Partition Over Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Unlike the function dense_rank , rank will produce gaps in the ranking. Implement liquid clustering to simplify data layout decisions and optimize query performance. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1,. Databricks Partition Over.
From docs.sisense.com
Connecting to Databricks Databricks Partition Over Unlike the function dense_rank , rank will produce gaps in the ranking. In snowflake i get the following results. Implement liquid clustering to simplify data layout decisions and optimize query performance. The over clause of the window function must include an order by clause. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta. Databricks Partition Over.
From www.youtube.com
100. Databricks Pyspark Spark Architecture Internals of Partition Databricks Partition Over The over clause of the window function must include an order by clause. In snowflake i get the following results. Unlike the function dense_rank , rank will produce gaps in the ranking. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. A partition is composed of a subset of rows in. Databricks Partition Over.
From exoxwqtpl.blob.core.windows.net
Partition Table Databricks at Jamie Purington blog Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from. Databricks Partition Over.
From www.databricks.com
Cost Effective and Secure Data Sharing The Advantages of Leveraging Databricks Partition Over In snowflake i get the following results. Learn how to use replacewhere and dynamic partition overwrite modes to selectively overwrite data in delta lake tables. Unlike the function dense_rank , rank will produce gaps in the ranking. Implement liquid clustering to simplify data layout decisions and optimize query performance. This article provides an overview of how you can partition tables. Databricks Partition Over.
From www.databricks.com
What’s New with Databricks Notebooks Databricks Blog Databricks Partition Over This article provides an overview of how you can partition tables on azure databricks and specific recommendations around when you. A partition is composed of a subset of rows in a table that share the same value for a predefined subset of columns called the partitioning. Implement liquid clustering to simplify data layout decisions and optimize query performance. The window. Databricks Partition Over.
From www.youtube.com
Databricks and the Data Lakehouse YouTube Databricks Partition Over The window frame clause specifies a sliding subset of rows within the partition on which the aggregate or analytics function operates. Implement liquid clustering to simplify data layout decisions and optimize query performance. Select col1, col2, last_value(col2) over (partition by col1 order by col2) as column2_last from values (1, 10), (1, 11), (1, 12), (2, 20), (2, 21), (2, 22);. Databricks Partition Over.