Q Learning Rl . We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. In rl, we have an environment that we want to learn. The q table helps us to find the best action for each state. Our goal is to maximize the value function q. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. This is the fourth article in my series on reinforcement learning (rl). You might find it helpful to read the original.
from bairblog.github.io
We can now bring these together to learn about complete solutions used by the most popular rl algorithms. Our goal is to maximize the value function q. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. In rl, we have an environment that we want to learn. This is the fourth article in my series on reinforcement learning (rl). The q table helps us to find the best action for each state. You might find it helpful to read the original.
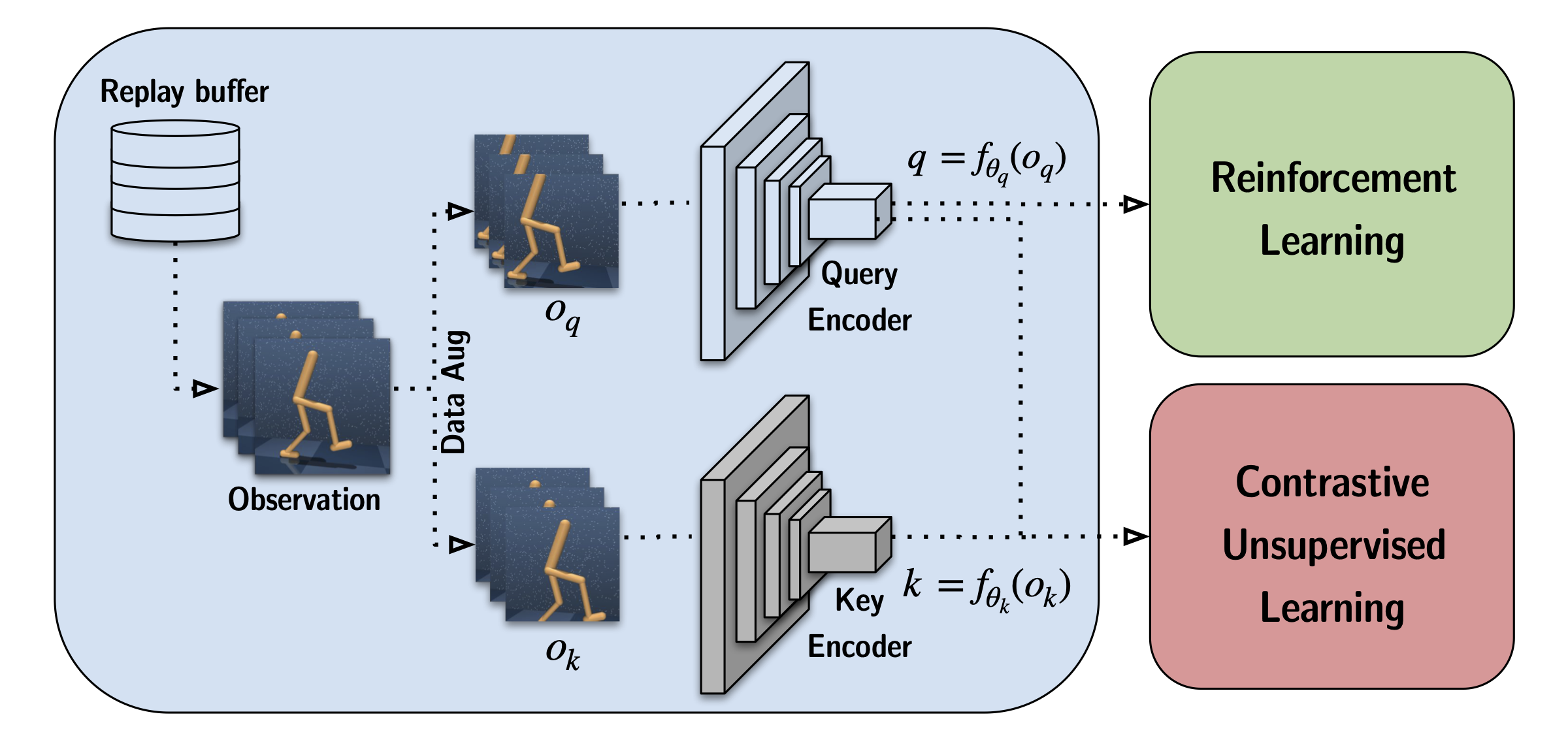
Can RL From Pixels be as Efficient as RL From State? The Berkeley
Q Learning Rl You might find it helpful to read the original. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. This is the fourth article in my series on reinforcement learning (rl). The q table helps us to find the best action for each state. You might find it helpful to read the original. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. In rl, we have an environment that we want to learn. Our goal is to maximize the value function q.
From www.assemblyai.com
Reinforcement Learning With (Deep) QLearning Explained Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. Our goal is to maximize the value function q. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we. Q Learning Rl.
From www.anyscale.com
Reinforcement learning with Deep Q Networks Anyscale Q Learning Rl Our goal is to maximize the value function q. You might find it helpful to read the original. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve. Q Learning Rl.
From www.researchgate.net
Comparison of proposed technique (GP+RL) with Qlearning (RL+RL Q Learning Rl In rl, we have an environment that we want to learn. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. You might find it helpful to read the original. Our goal is to maximize the value function q. The q table helps us to find the best action for each state.. Q Learning Rl.
From bairblog.github.io
Can RL From Pixels be as Efficient as RL From State? The Berkeley Q Learning Rl The q table helps us to find the best action for each state. Our goal is to maximize the value function q. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. You might find it helpful to read the original. In rl, we have an environment that we want to learn.. Q Learning Rl.
From blog.flyingwhales.io
RL Deep Qlearning Flying Whales Q Learning Rl The q table helps us to find the best action for each state. You might find it helpful to read the original. Our goal is to maximize the value function q. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. We now have a good understanding of the concepts that form. Q Learning Rl.
From github.com
GitHub ylcodeit/Q_Learning_RL_Robotic_Path_Planning_2D_Gridworld Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. The q table helps us to find the best action for each state. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. You might find it. Q Learning Rl.
From huggingface.co
Introducing QLearning Hugging Face Deep RL Course Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. This is the fourth article in my series on reinforcement learning (rl). Our goal is to maximize the value function q. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques. Q Learning Rl.
From keon.github.io
Deep QLearning with Keras and Gym · Keon's Blog Q Learning Rl This is the fourth article in my series on reinforcement learning (rl). We can now bring these together to learn about complete solutions used by the most popular rl algorithms. You might find it helpful to read the original. The q table helps us to find the best action for each state. Our goal is to maximize the value function. Q Learning Rl.
From www.youtube.com
RL 9 Q Learning explained Reinforcement learning algorithms YouTube Q Learning Rl Our goal is to maximize the value function q. In rl, we have an environment that we want to learn. The q table helps us to find the best action for each state. This is the fourth article in my series on reinforcement learning (rl). You might find it helpful to read the original. We can now bring these together. Q Learning Rl.
From www.researchgate.net
Pseudocode of Qlearning based RL method on WSO Download Scientific Q Learning Rl Our goal is to maximize the value function q. The q table helps us to find the best action for each state. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the. Q Learning Rl.
From www.analyticsvidhya.com
Introduction to Deep QLearning for Reinforcement Learning (in Python) Q Learning Rl Our goal is to maximize the value function q. The q table helps us to find the best action for each state. You might find it helpful to read the original. This is the fourth article in my series on reinforcement learning (rl). We can now bring these together to learn about complete solutions used by the most popular rl. Q Learning Rl.
From www.datacamp.com
An Introduction to QLearning A Tutorial For Beginners DataCamp Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we want to learn. You might find it helpful to read the original. This is the fourth article in my series on reinforcement learning (rl). We now have a good understanding of the concepts that. Q Learning Rl.
From www.turing.com
A Comprehensive Guide to Neural Networks in Deep Qlearning Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. You might find it helpful to read the original. In rl, we have an environment that we want to learn. Our goal is to maximize the value function q. This is the fourth article in. Q Learning Rl.
From wikidocs.net
12. QTable Deep Learning Bible 5. Reinforcement Learning 한글 Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the best action for each state. In rl, we have an environment that we want to learn. We can now bring these together to learn about complete solutions. Q Learning Rl.
From www.youtube.com
Implementing QLearning (RL) algorithm in lane following diffdrive Q Learning Rl This is the fourth article in my series on reinforcement learning (rl). We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we want to learn. Our goal is to maximize the value function q. We now have a good understanding of the concepts that. Q Learning Rl.
From www.researchgate.net
The Qlearning RL agent. Download Scientific Diagram Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we want to learn. Our goal is to maximize the value function q. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used. Q Learning Rl.
From databasecamp.de
QLearning einfach erklärt Data Basecamp Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. The q table helps us to find the best action for each state. Our goal is to. Q Learning Rl.
From zhuanlan.zhihu.com
【Typical RL 02】Double Qlearning 知乎 Q Learning Rl Our goal is to maximize the value function q. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the best action for each state. In rl, we have an environment that we want to learn. We can. Q Learning Rl.
From khanrc.github.io
RL Deep Qlearning Khanrc's blog Q Learning Rl In rl, we have an environment that we want to learn. The q table helps us to find the best action for each state. This is the fourth article in my series on reinforcement learning (rl). We can now bring these together to learn about complete solutions used by the most popular rl algorithms. We now have a good understanding. Q Learning Rl.
From huggingface.co
The Deep QLearning Algorithm Hugging Face Deep RL Course Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the best action for each state. You might find it helpful to read the original. Our goal is to maximize the value function q. We can now bring. Q Learning Rl.
From ketanhdoshi.github.io
Reinforcement Learning Explained Visually Q Learning, stepbystep Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the best action for each state. You might find it helpful to read the original. Our goal is to maximize the value function q. We can now bring. Q Learning Rl.
From huggingface.co
An Introduction to QLearning Part 1 Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the best action for each state. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. This is the fourth. Q Learning Rl.
From sefidian.com
Understand QLearning in Reinforcement Learning with a numerical Q Learning Rl In rl, we have an environment that we want to learn. This is the fourth article in my series on reinforcement learning (rl). We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. Our goal is to maximize the value function q. We can now. Q Learning Rl.
From www.researchgate.net
RL framework with Qlearning method. Download Scientific Diagram Q Learning Rl This is the fourth article in my series on reinforcement learning (rl). You might find it helpful to read the original. Our goal is to maximize the value function q. The q table helps us to find the best action for each state. In rl, we have an environment that we want to learn. We now have a good understanding. Q Learning Rl.
From www.researchgate.net
The Qlearning RL agent. Download Scientific Diagram Q Learning Rl You might find it helpful to read the original. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. This is the fourth article in my series on reinforcement learning (rl). The q table helps us to find the best action for each state. Our. Q Learning Rl.
From huggingface.co
Deep QLearning with Space Invaders Q Learning Rl Our goal is to maximize the value function q. This is the fourth article in my series on reinforcement learning (rl). We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. We can now bring these together to learn about complete solutions used by the. Q Learning Rl.
From www.tensorflow.org
Introduction to RL and Deep Q Networks TensorFlow Agents Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we want to learn. Our goal is to maximize the value function q. This is the fourth article in my series on reinforcement learning (rl). You might find it helpful to read the original. The. Q Learning Rl.
From www.researchgate.net
Pseudocode of Qlearning based RL method on WSO Download Scientific Q Learning Rl You might find it helpful to read the original. Our goal is to maximize the value function q. The q table helps us to find the best action for each state. In rl, we have an environment that we want to learn. This is the fourth article in my series on reinforcement learning (rl). We can now bring these together. Q Learning Rl.
From morioh.com
Q Learning In Reinforcement Learning Q Learning Example Machine Q Learning Rl In rl, we have an environment that we want to learn. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. The q table helps us to find the best action for each state. This is the fourth article in my series on reinforcement learning (rl). You might find it helpful to. Q Learning Rl.
From huggingface.co
From QLearning to Deep QLearning Hugging Face Deep RL Course Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. Our goal is to maximize the value function q. In rl, we have an environment that we want to learn. The q table helps us to find the best action for each state. This is. Q Learning Rl.
From huggingface.co
From QLearning to Deep QLearning Hugging Face Deep RL Course Q Learning Rl You might find it helpful to read the original. We can now bring these together to learn about complete solutions used by the most popular rl algorithms. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. The q table helps us to find the. Q Learning Rl.
From zitaoshen.rbind.io
3 mins of Reinforcement Learning QLearning Zitao's Q Learning Rl This is the fourth article in my series on reinforcement learning (rl). In rl, we have an environment that we want to learn. Our goal is to maximize the value function q. The q table helps us to find the best action for each state. We now have a good understanding of the concepts that form the building blocks of. Q Learning Rl.
From huggingface.co
QLearning Recap Hugging Face Deep RL Course Q Learning Rl We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. In rl, we have an environment that we want to learn. You might find it helpful to read the original. We can now bring these together to learn about complete solutions used by the most. Q Learning Rl.
From github.com
RLNashQlearning/Nash QLearning for GeneralSum Stochastic Games.pdf Q Learning Rl You might find it helpful to read the original. This is the fourth article in my series on reinforcement learning (rl). The q table helps us to find the best action for each state. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. Our. Q Learning Rl.
From huggingface.co
Introducing QLearning Hugging Face Deep RL Course Q Learning Rl We can now bring these together to learn about complete solutions used by the most popular rl algorithms. In rl, we have an environment that we want to learn. We now have a good understanding of the concepts that form the building blocks of an rl problem, and the techniques used to solve them. You might find it helpful to. Q Learning Rl.