Graph Transformers Github . Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Towards a general theory for scalable. They have achieved inital success on many practical. Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. Recently, researchers turns to explore the application of transformer in graph learning.
from blog.csdn.net
They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:.
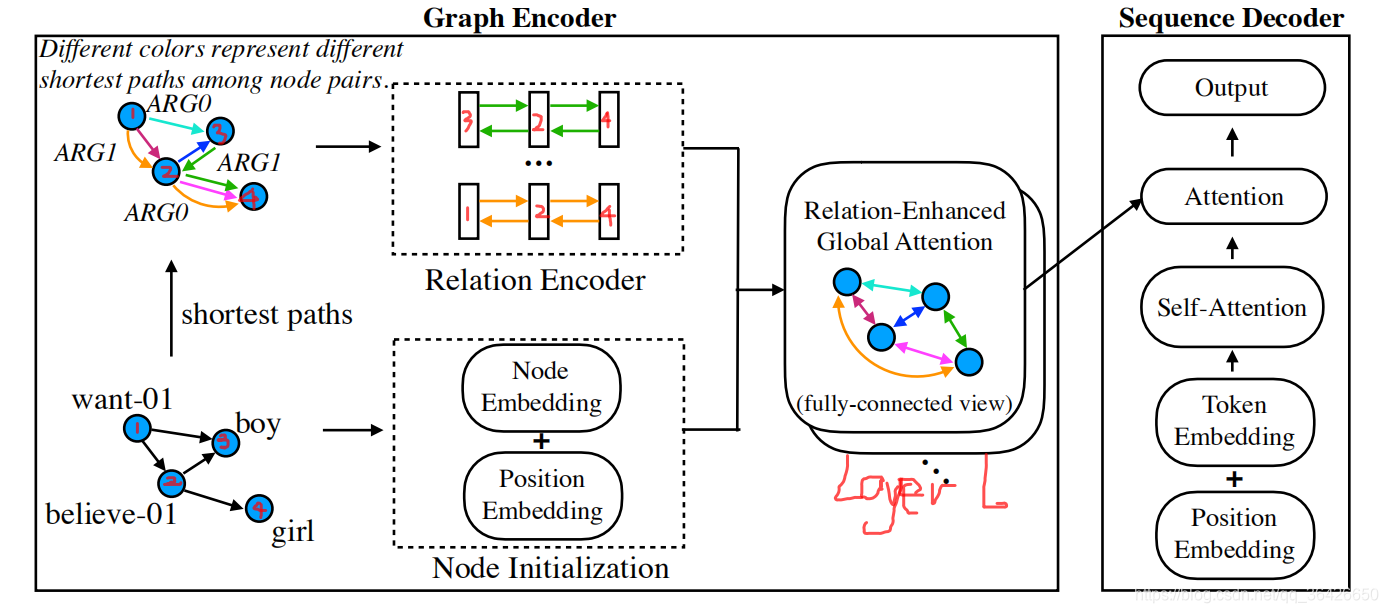
论文解读:Graph Transformer for GraphtoSequence Learning_graph transformer模型CSDN博客
Graph Transformers Github Our gps recipe consists of choosing 3 main ingredients:. Recently, researchers turns to explore the application of transformer in graph learning. They have achieved inital success on many practical. Towards a general theory for scalable. Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Our gps recipe consists of choosing 3 main ingredients:.
From github.com
at main · · GitHub Graph Transformers Github Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Less than 1 minute read. They have achieved inital success on many practical. Our gps recipe consists of choosing 3 main ingredients:. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From graphdeeplearning.github.io
Transformers are Graph Neural Networks NTU Graph Deep Learning Lab Graph Transformers Github Less than 1 minute read. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Graph Transformers Github.
From github.com
GitHub lilianweng/transformertensorflow Implementation of Transformer Model in Tensorflow Graph Transformers Github Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Less than 1 minute read. They have achieved inital success on many practical. Our gps recipe consists of choosing 3 main ingredients:. Graph Transformers Github.
From joshuamitton.github.io
Josh Mitton Graph Transformers Github Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From graphdeeplearning.github.io
Transformers are Graph Neural Networks NTU Graph Deep Learning Lab Graph Transformers Github Towards a general theory for scalable. Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Graph Transformers Github.
From github.com
GitHub Communityaware Graph Transformer (CGT) is Graph Transformers Github Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Less than 1 minute read. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Graph Transformers Github.
From blog.csdn.net
论文解读:Graph Transformer for GraphtoSequence Learning_graph transformer模型CSDN博客 Graph Transformers Github Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
GitHub yinboc/transinr Transformers as MetaLearners for Implicit Neural Representations, in Graph Transformers Github Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Graph Transformers Github.
From github.com
GitHub Redcof/vitgpt2imagecaptioning A Image to Text Captioning deep learning model with Graph Transformers Github Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From www.vrogue.co
Github Daiquocnguyengraph Transformer Transformer For vrogue.co Graph Transformers Github Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
· GitHub Topics · GitHub Graph Transformers Github Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Graph Transformers Github.
From github.com
GitHub PengBoXiangShang/multigraph_transformer IEEE TNNLS 2021, transformer, multigraph Graph Transformers Github Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. They have achieved inital success on many practical. Less than 1 minute read. Graph Transformers Github.
From github.com
GitHub Hongjie97/GraphTransformer_BrainAge Graph Transformers Github Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. Less than 1 minute read. They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From lyusungwon.github.io
Text Generation from Knowledge Graphs with Graph Transformers · Deep learning travels Graph Transformers Github Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Less than 1 minute read. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Graph Transformers Github.
From github.com
Graph_Transformer/preprocess_data.py at main · zaixizhang/Graph_Transformer · GitHub Graph Transformers Github They have achieved inital success on many practical. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From www.vrogue.co
Github Daiquocnguyengraph Transformer Transformer For vrogue.co Graph Transformers Github They have achieved inital success on many practical. Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Graph Transformers Github.
From lyusungwon.github.io
Text Generation from Knowledge Graphs with Graph Transformers · Deep learning travels Graph Transformers Github Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
GraphTransformer/UGformerV1_Sup.py at master · daiquocnguyen/GraphTransformer · GitHub Graph Transformers Github Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Our gps recipe consists of choosing 3 main ingredients:. Recently, researchers turns to explore the application of transformer in graph learning. They have achieved inital success on many practical. Towards a general theory for scalable. Graph Transformers Github.
From github.com
transformermodels/dropout.m at master · matlabdeeplearning/transformermodels · GitHub Graph Transformers Github Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Graph Transformers Github.
From davide-belli.github.io
Generative Graph Transformer Graph Transformers Github Towards a general theory for scalable. Less than 1 minute read. They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From zzyzeyuan.github.io
Edgeaugmented Graph Transformers Global Selfattention is Enough for Graphs(EGT) Zeyuan Zhao Graph Transformers Github Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. Graph Transformers Github.
From www.vrogue.co
Github Daiquocnguyengraph Transformer Transformer For vrogue.co Graph Transformers Github Our gps recipe consists of choosing 3 main ingredients:. Towards a general theory for scalable. Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From github.com
TF remove graph mode distinction when processing boolean options by gante · Pull Request 18102 Graph Transformers Github Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Less than 1 minute read. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Graph Transformers Github.
From github.com
at main Graph Transformers Github Towards a general theory for scalable. Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
GitHub CYVincent/SceneGraphTransformerCogTree Graph Transformers Github Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. They have achieved inital success on many practical. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From chriszhangcx.github.io
[KDD'22] Mask and Reason PreTraining Knowledge Graph Transformers for Complex Logical Queries Graph Transformers Github Less than 1 minute read. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From www.ai2news.com
RealFormer Transformer Likes Residual Attention AI牛丝 Graph Transformers Github Recently, researchers turns to explore the application of transformer in graph learning. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Less than 1 minute read. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Graph Transformers Github.
From github.com
GitHub AIHUBDeepLearningFundamental/unlimiformerLongRangeTransformerswithUnlimited Graph Transformers Github They have achieved inital success on many practical. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From chriszhangcx.github.io
[KDD'22] Mask and Reason PreTraining Knowledge Graph Transformers for Complex Logical Queries Graph Transformers Github Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Less than 1 minute read. Graph Transformers Github.
From graphdeeplearning.github.io
Transformers are Graph Neural Networks NTU Graph Deep Learning Lab Graph Transformers Github Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Our gps recipe consists of choosing 3 main ingredients:. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Less than 1 minute read. Graph Transformers Github.
From www.vrogue.co
Github Daiquocnguyengraph Transformer Transformer For vrogue.co Graph Transformers Github Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. They have achieved inital success on many practical. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Graph Transformers Github.
From chriszhangcx.github.io
[KDD'22] Mask and Reason PreTraining Knowledge Graph Transformers for Complex Logical Queries Graph Transformers Github Less than 1 minute read. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Towards a general theory for scalable. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
transformers/src/transformers/models/gpt_bigcode/inference_runner.py at main · bigcodeproject Graph Transformers Github They have achieved inital success on many practical. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Towards a general theory for scalable. Our gps recipe consists of choosing 3 main ingredients:. Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Graph Transformers Github.
From github.com
GitHub njmarko/graphtransformerpsiml Transformer implemented with graph attention network Graph Transformers Github Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Graph Transformers Github.
From github.com
GitHub mylu/transformers Graph Transformers Github Less than 1 minute read. Recently, researchers turns to explore the application of transformer in graph learning. Towards a general theory for scalable. Here, we present the spectral attention network (san), which uses a learned positional encoding (lpe) that can take. Our gps recipe consists of choosing 3 main ingredients:. They have achieved inital success on many practical. Graph Transformers Github.