Block Site Robots.txt . If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. How to disallow all using robots.txt. If the file isn’t there, you can create it manually. First, you have to enter the file manager in the files section of the panel. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Disallow all search engines but one: If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: Testing a robots.txt file in google search console. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Then, open the file from the public_html directory. Now you can start adding commands to.
from rankmath.com
Disallow all search engines but one: If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: If the file isn’t there, you can create it manually. Testing a robots.txt file in google search console. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Now you can start adding commands to. How to disallow all using robots.txt.
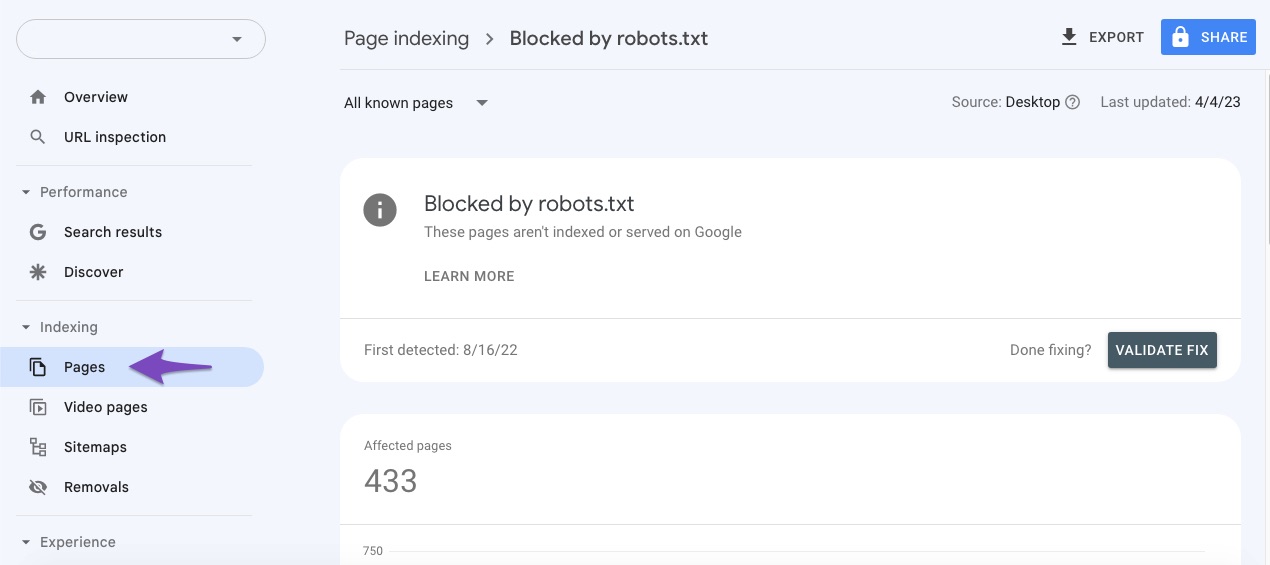
How to Fix 'Blocked by robots.txt’ Error in Google Search Console
Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: Disallow all search engines but one: If the file isn’t there, you can create it manually. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Then, open the file from the public_html directory. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. First, you have to enter the file manager in the files section of the panel. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Now you can start adding commands to. Testing a robots.txt file in google search console. How to disallow all using robots.txt.
From supporthost.com
Robots.txt file all you need to know SupportHost Block Site Robots.txt If the file isn’t there, you can create it manually. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. To prevent search engines from. Block Site Robots.txt.
From www.keycdn.com
How to Fix Sitemap Contains URLs Which Are Blocked by Robots.txt Block Site Robots.txt Disallow all search engines but one: Testing a robots.txt file in google search console. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Then, open the file from the public_html. Block Site Robots.txt.
From backlinko.com
Robots.txt and SEO Complete Guide Block Site Robots.txt To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. First, you have to enter the file manager in the files section of the panel. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Now you can start adding commands to. Just click the new file button. Block Site Robots.txt.
From www.onely.com
“Blocked by robots.txt” vs. “Indexed, though blocked by robots.txt” Onely Block Site Robots.txt Disallow all search engines but one: Then, open the file from the public_html directory. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. If the file isn’t there, you can create it manually. How to disallow all using robots.txt. First, you have to enter the file manager in the files section of the. Block Site Robots.txt.
From www.semrush.com
A Complete Guide to Robots.txt & Why It Matters Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: If the file isn’t there, you can create it manually. Just click the new file button at the. Block Site Robots.txt.
From www.onely.com
“Blocked by robots.txt” vs. “Indexed, though blocked by robots.txt” Onely Block Site Robots.txt Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: Testing a robots.txt file in google search console. First, you have. Block Site Robots.txt.
From www.seobility.net
What is a Robots.txt File and how do you create it? Seobility Wiki Block Site Robots.txt A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Then, open the file from the public_html directory. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. If the file isn’t there, you can create it manually. Testing a robots.txt file in google search console. If you. Block Site Robots.txt.
From www.stanventures.com
Blocking Robots.txt for SEO Optimization A Complete Guide Block Site Robots.txt Disallow all search engines but one: If the file isn’t there, you can create it manually. Now you can start adding commands to. Testing a robots.txt file in google search console. How to disallow all using robots.txt. Then, open the file from the public_html directory. First, you have to enter the file manager in the files section of the panel.. Block Site Robots.txt.
From ahrefs.com
"Indexed, though blocked by robots.txt" Can Be More Than A Robots.txt Block Block Site Robots.txt A robots.txt file tells search engine crawlers which urls the crawler can access on your site. If the file isn’t there, you can create it manually. Then, open the file from the public_html directory. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. To prevent search. Block Site Robots.txt.
From www.semrush.com
Robots.Txt What Is Robots.Txt & Why It Matters for SEO Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. If the file isn’t there, you can create it manually. If you want to instruct all robots to stay away from your site, then this is the code you. Block Site Robots.txt.
From www.onely.com
“Blocked by robots.txt” vs. “Indexed, though blocked by robots.txt” Onely Block Site Robots.txt Now you can start adding commands to. Testing a robots.txt file in google search console. If the file isn’t there, you can create it manually. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. Then, open the file from the public_html directory. How to disallow all using. Block Site Robots.txt.
From rankmath.com
How to Fix 'Blocked by robots.txt’ Error in Google Search Console Block Site Robots.txt If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Then, open the file from the public_html directory. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. First, you have to enter the file manager in the files section of the panel. Just click the new file. Block Site Robots.txt.
From ignitevisibility.com
The Newbies Guide to Block URLs in a Robots.txt File Block Site Robots.txt A robots.txt file tells search engine crawlers which urls the crawler can access on your site. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: How to disallow all using robots.txt. Testing a robots.txt file in google search console. Disallow all search. Block Site Robots.txt.
From kinsta.com
How To Fix the Indexed Though Blocked by robots.txt Error (2 Methods) Block Site Robots.txt Disallow all search engines but one: If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. If the file isn’t there,. Block Site Robots.txt.
From rankmath.com
How to Add Sitemaps to Robots.txt » Rank Math Block Site Robots.txt Testing a robots.txt file in google search console. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. How to disallow all using robots.txt. Now you can start adding commands to. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Just. Block Site Robots.txt.
From www.bigtechies.com
Robots.txt Optimizer Plugin Big Techies Block Site Robots.txt Testing a robots.txt file in google search console. If the file isn’t there, you can create it manually. How to disallow all using robots.txt. Now you can start adding commands to. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. Disallow all search engines but one: To. Block Site Robots.txt.
From rdochhane.blogspot.com
Robots.txt Block Site Robots.txt A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Then, open the file from the public_html directory. If the file isn’t there, you can create it manually. First, you have to enter the file manager in the files section of the panel. Just click the new file button at the top right corner. Block Site Robots.txt.
From digitizengrow.com
The Ultimate Guide To Robots.txt 2023 Block Site Robots.txt If the file isn’t there, you can create it manually. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. Then, open the file from. Block Site Robots.txt.
From ignitevisibility.com
Robots.txt Disallow 2025 Guide for Marketers Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. How to disallow all using robots.txt. If the file isn’t there, you can create it manually. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Testing a robots.txt file in google search console. A robots.txt file tells search. Block Site Robots.txt.
From www.youtube.com
How to Fix Blocked by robots.txt Errors YouTube Block Site Robots.txt If the file isn’t there, you can create it manually. Testing a robots.txt file in google search console. Then, open the file from the public_html directory. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. How to disallow all using robots.txt. If you want to instruct. Block Site Robots.txt.
From kinsta.com
How To Fix the Indexed Though Blocked by robots.txt Error (2 Methods) Block Site Robots.txt How to disallow all using robots.txt. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Testing a robots.txt file in google search console. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: First, you have. Block Site Robots.txt.
From thecustomizewindows.com
Let's Block the AI Crawlers Using robots.txt File Block Site Robots.txt Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: First, you have to enter the file manager in the. Block Site Robots.txt.
From www.youtube.com
How To Fix Blocked by robots.txt Errors in Google Search Console YouTube Block Site Robots.txt If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: If we only wanted to allow googlebot access to our /private/ directory and disallow all other. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Testing. Block Site Robots.txt.
From www.onely.com
“Blocked by robots.txt” vs. “Indexed, though blocked by robots.txt” Onely Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. Testing a robots.txt file in google search console. Disallow all search engines but one: How to disallow all using robots.txt. If the file isn’t there, you can create it manually. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by. Block Site Robots.txt.
From www.youtube.com
How To Fix the Indexed Though Blocked by robots.txt Error YouTube Block Site Robots.txt A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Disallow all search engines but one: Now you can start adding commands to. First, you have to enter the file manager in the files section of the panel. How to disallow all using robots.txt. If you want to instruct all robots to stay away. Block Site Robots.txt.
From stackoverflow.com
.htaccess Google Not Indexing Site Says 'Blocked by Robots.txt Block Site Robots.txt Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. Now you can start adding commands to. Then, open the file from the public_html directory. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers.. Block Site Robots.txt.
From www.webmatriks.com
What is a robots.txt File and How to Create it? Block Site Robots.txt If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. Testing a robots.txt file in google search console. How to. Block Site Robots.txt.
From rankmath.com
How to Fix 'Blocked by robots.txt’ Error in Google Search Console Block Site Robots.txt Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web. Block Site Robots.txt.
From cognitiveseo.com
Critical Mistakes in Your Robots.txt Will Break Your Rankings and You Block Site Robots.txt First, you have to enter the file manager in the files section of the panel. How to disallow all using robots.txt. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Robots.txt is the filename used for implementing. Block Site Robots.txt.
From neilpatel.com
How to Create the Perfect Robots.txt File for SEO Block Site Robots.txt If the file isn’t there, you can create it manually. Testing a robots.txt file in google search console. Then, open the file from the public_html directory. To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. Disallow all search engines but one: How to disallow all using robots.txt. Now you can start adding commands. Block Site Robots.txt.
From www.reliablesoft.net
Robots.txt And SEO Easy Guide For Beginners Block Site Robots.txt Disallow all search engines but one: Then, open the file from the public_html directory. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Now you can start adding commands to. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html.. Block Site Robots.txt.
From play-media.org
Blocked by robots.txt Play Media Academy Block Site Robots.txt To prevent search engines from crawling specific pages, you can use the disallow command in robots.txt. A robots.txt file tells search engine crawlers which urls the crawler can access on your site. Then, open the file from the public_html directory. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting. Block Site Robots.txt.
From seohub.net.au
A Complete Guide to Robots.txt & Why It Matters Block Site Robots.txt Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate to visiting web crawlers. Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. First, you have to enter the file manager in the files section of the panel.. Block Site Robots.txt.
From www.onely.com
How To Fix “Blocked by robots.txt” in Google Search Console Block Site Robots.txt If you want to instruct all robots to stay away from your site, then this is the code you should put in your robots.txt to disallow all: First, you have to enter the file manager in the files section of the panel. Robots.txt is the filename used for implementing the robots exclusion protocol, a standard used by websites to indicate. Block Site Robots.txt.
From rankmath.com
Common robots.txt Issues & How to Fix Them » Rank Math Block Site Robots.txt Just click the new file button at the top right corner of the file manager, name it robots.txt and place it in public_html. If we only wanted to allow googlebot access to our /private/ directory and disallow all other. Disallow all search engines but one: Now you can start adding commands to. If the file isn’t there, you can create. Block Site Robots.txt.