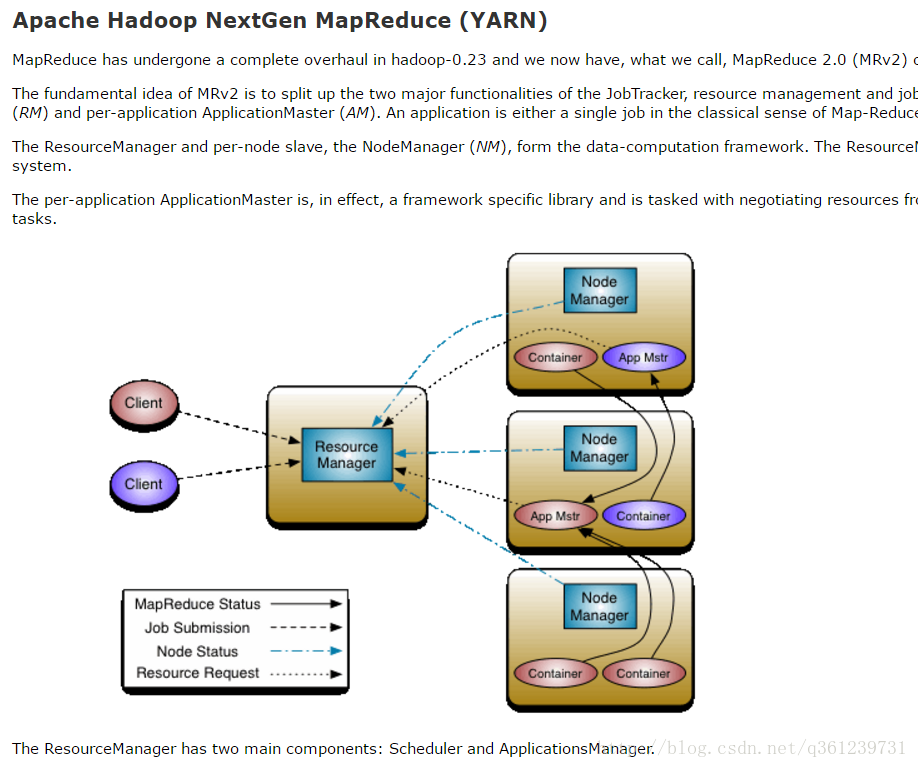
Yarn.app.mapreduce.am.job.reduce.preemption.limit . Mapreduce is just one choice. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. I tried to run simple word count as mapreduce job. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. The default number of reduce tasks per job. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Also referred to as mapreduce2.0, nextgen. Physical memory for your yarn map and reduce processes. But, when i try to run it on a cluster using yarn (adding. Everything works fine when run locally (all work done on name node). The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and.
from blog.csdn.net
Everything works fine when run locally (all work done on name node). Mapreduce is just one choice. Physical memory for your yarn map and reduce processes. Also referred to as mapreduce2.0, nextgen. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. The default number of reduce tasks per job. But, when i try to run it on a cluster using yarn (adding. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the.
MapReduce和Yarn的理解_移动计算和yarn有啥关系CSDN博客
Yarn.app.mapreduce.am.job.reduce.preemption.limit Everything works fine when run locally (all work done on name node). Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Everything works fine when run locally (all work done on name node). This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. The default number of reduce tasks per job. Also referred to as mapreduce2.0, nextgen. I tried to run simple word count as mapreduce job. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. But, when i try to run it on a cluster using yarn (adding. Mapreduce is just one choice. Physical memory for your yarn map and reduce processes.
From blog.csdn.net
MapReduce 原理、过程详解与优化 Yarn Hdfs Mapreduce 三者联系_hdfs、yarn、mapreduce三者关系CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit The default number of reduce tasks per job. Everything works fine when run locally (all work done on name node). Physical memory for your yarn map and reduce processes. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Also referred to as mapreduce2.0, nextgen. But, when i try to run it on a cluster using yarn (adding. Mapreduce is just one choice.. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From zhuanlan.zhihu.com
[配置]HadoopMapReduce&Yarn 知乎 Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. Physical memory for your yarn map and reduce processes. But, when i try to run it on a cluster using yarn (adding. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article will provide information on hadoop parameters used to manage. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
HadoopMapReduce与Yarn配置文件_yarnsite配置CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit The default number of reduce tasks per job. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Everything works fine when run locally (all work done on name node). Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Mapreduce is. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From kaizen.itversity.com
Map Reduce Job Execution Life Cycle Kaizen Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. The default number of reduce tasks per job. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Physical memory for your yarn map and. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
yarn集群搭建部署MapReduce实现WorldCount mapreduce运行平台YARN运行mapreduce程序(seven day third)_yarn 提交 Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. The default number of reduce tasks per job. Everything works fine when run locally (all work done on name node). This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Also referred. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
YARN的介绍与学习以及(MapReduce on yarn )_rm里面有调度器CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. Also referred to as mapreduce2.0, nextgen. But, when i try to run it on a cluster using yarn (adding. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. I tried to run simple word count as mapreduce job. Mapreduce is just. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.trionds.com
Understanding the MapReduce Application Trionds Yarn.app.mapreduce.am.job.reduce.preemption.limit Everything works fine when run locally (all work done on name node). But, when i try to run it on a cluster using yarn (adding. Mapreduce is just one choice. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. I tried to run simple word count as mapreduce job. Typically set to 99% of the cluster's reduce capacity, so that if a. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
MapReduce和Yarn的理解_移动计算和yarn有啥关系CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Also referred to as mapreduce2.0, nextgen. But, when i try to run it on a. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
Hadoop学习记录5YARN学习1_yarn.app.mapreduce.am.envCSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Physical memory for your yarn map and reduce processes. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. The default number of reduce tasks per job.. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
Hadoop MapReduce & Yarn 详解_掌握hadoop2.0的yarn编程原理,使用yarn编程接口实现矩阵乘法,体会mapreduce的CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. Also referred to as mapreduce2.0, nextgen. Everything works fine when run locally (all work done on name node). The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. This article will provide information on hadoop parameters used to manage memory allocations for. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.slideshare.net
Introduction to YARN and MapReduce 2 Yarn.app.mapreduce.am.job.reduce.preemption.limit The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Physical memory for your yarn map and reduce processes. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. But, when i try. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.slideshare.net
Introduction to YARN and MapReduce 2 Yarn.app.mapreduce.am.job.reduce.preemption.limit This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Physical memory for your yarn map and reduce processes. The default number of reduce tasks. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From ercoppa.github.io
Anatomy of a MapReduce Job · Hadoop Internals Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Also referred to as mapreduce2.0, nextgen. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Everything works fine when run locally (all work done. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
手工计算YARN和MapReduce、tez内存配置设置_tez container 数量CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. Also referred to as mapreduce2.0, nextgen. The default number of reduce tasks per job. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. But,. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.dineshonjava.com
Introduction to MapReduce Dinesh on Java Yarn.app.mapreduce.am.job.reduce.preemption.limit This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Mapreduce is just one choice. Also referred to as mapreduce2.0, nextgen. Everything works fine when run locally (all work done. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.codingninjas.com
YARN vs MapReduce Coding Ninjas Yarn.app.mapreduce.am.job.reduce.preemption.limit The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Also referred to as mapreduce2.0, nextgen. Mapreduce is just one choice. But, when i try to run it on a cluster using yarn (adding.. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From nikamooz.com
تنظیمات پیکربندی حافظه YARN و MapReduce Yarn.app.mapreduce.am.job.reduce.preemption.limit But, when i try to run it on a cluster using yarn (adding. Mapreduce is just one choice. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. The default number of reduce tasks per job. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Everything works fine when run locally (all work. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From jobdrop.blogspot.com
How Hadoop Runs A Mapreduce Job Using Yarn Job Drop Yarn.app.mapreduce.am.job.reduce.preemption.limit This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Everything works fine when run locally (all work done on name node). Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. I tried to run simple word count as mapreduce job.. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.slideshare.net
Introduction to YARN and MapReduce 2 Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. I tried to run simple word count as mapreduce job. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. The default number of reduce. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.slideserve.com
PPT MapReduce Tutorial What is MapReduce Hadoop MapReduce Tutorial Edureka PowerPoint Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Everything works fine when run locally (all work done on name node). The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. I tried to run simple word count as mapreduce job. Also referred. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
Yarn工作机制和HDFS、Yarn、MapReduce之间的关系_yarn的applicationmaster与mapreduce的mrappmaster关系CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Also referred to as mapreduce2.0, nextgen. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Typically set to 99% of the cluster's reduce capacity, so that if a node. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
MapReduce框架在Yarn上的详解_yarn mapreduce frameworkCSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. But, when i try to run it on a cluster using yarn (adding. Physical memory for your yarn map and reduce processes. Everything works fine when run locally (all work done on name node). Typically set to 99% of the cluster's reduce capacity, so that if a node fails the. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
Hadoop学习记录5YARN学习1_yarn.app.mapreduce.am.envCSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Physical memory for your yarn map and reduce processes. Everything works fine when run locally (all work done on name node). Mapreduce is just one choice. I tried to run simple word count as. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.youtube.com
YARN Hadoop Beyond MapReduce YouTube Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Mapreduce is just one choice. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. I tried to run simple word count as mapreduce job. The am's ipc port is indeed used directly. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From jobdrop.blogspot.com
How Hadoop Runs A Mapreduce Job Using Yarn Job Drop Yarn.app.mapreduce.am.job.reduce.preemption.limit Physical memory for your yarn map and reduce processes. But, when i try to run it on a cluster using yarn (adding. Also referred to as mapreduce2.0, nextgen. Mapreduce is just one choice. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. The. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From zhuanlan.zhihu.com
MapReduce及Yarn详细工作流程 知乎 Yarn.app.mapreduce.am.job.reduce.preemption.limit The default number of reduce tasks per job. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Mapreduce is just one choice. I tried to run simple word count as mapreduce job. Also referred to as mapreduce2.0, nextgen. Typically set to 99% of the cluster's reduce capacity, so. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
Hadoop三大核心组件——HDFS、YARN、MapReduce原理解析_hadoop三大组件CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. The am's ipc port is indeed used directly by clients and are controllable on the serving am via the. Also referred to as mapreduce2.0, nextgen. Physical memory for your yarn map and reduce processes. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.netjstech.com
MapReduce Flow in YARN Tech Tutorials Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. Also referred to as mapreduce2.0, nextgen. But, when i try to run it on a cluster using yarn (adding. Physical memory for your yarn map and reduce processes. Mapreduce is just one choice. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.slideshare.net
Introduction to YARN and MapReduce 2 Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Physical memory for your yarn map and reduce processes. Everything works fine when run locally (all work done on name node). The. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.researchgate.net
YARN Architecture. In the example a MPI and MapReduce application have... Download Scientific Yarn.app.mapreduce.am.job.reduce.preemption.limit Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Mapreduce is just one choice. The default number of reduce tasks per job. Physical memory for your yarn map and reduce processes. But, when i try to run it on a cluster using yarn (adding. Also referred to as mapreduce2.0, nextgen. The common. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From catalog.skills.network
MapReduce and YARN Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. Mapreduce is just one choice. The common mapreduce parameters mapreduce.map.java.opts, mapreduce.reduce.java.opts, and. Everything works fine when run locally (all work done on name node). Physical memory for your yarn map and reduce processes. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
hadoop mapreduce, yarn, combiner组件 笔记_yarn combinerCSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit Also referred to as mapreduce2.0, nextgen. Everything works fine when run locally (all work done on name node). Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. I tried to run. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From www.mfbz.cn
MapReduce和Yarn部署+入门 Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. Physical memory for your yarn map and reduce processes. But, when i try to run it on a cluster using yarn (adding. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Mapreduce is just one choice. The default number of reduce tasks. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From blog.csdn.net
hadoop中MapReduce和yarn的基本原理讲解_在hadoop1 x版本中mapreduce程序是运行在yarn集群之上CSDN博客 Yarn.app.mapreduce.am.job.reduce.preemption.limit I tried to run simple word count as mapreduce job. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Typically set to 99% of the cluster's reduce capacity, so that if a node fails the reduces. Mapreduce is just one choice. Also referred to as mapreduce2.0, nextgen. But,. Yarn.app.mapreduce.am.job.reduce.preemption.limit.
From developer.aliyun.com
YARN与MapReduce的配置与使用阿里云开发者社区 Yarn.app.mapreduce.am.job.reduce.preemption.limit The default number of reduce tasks per job. But, when i try to run it on a cluster using yarn (adding. This article will provide information on hadoop parameters used to manage memory allocations for mapreduce jobs that are executed in the. Physical memory for your yarn map and reduce processes. Typically set to 99% of the cluster's reduce capacity,. Yarn.app.mapreduce.am.job.reduce.preemption.limit.