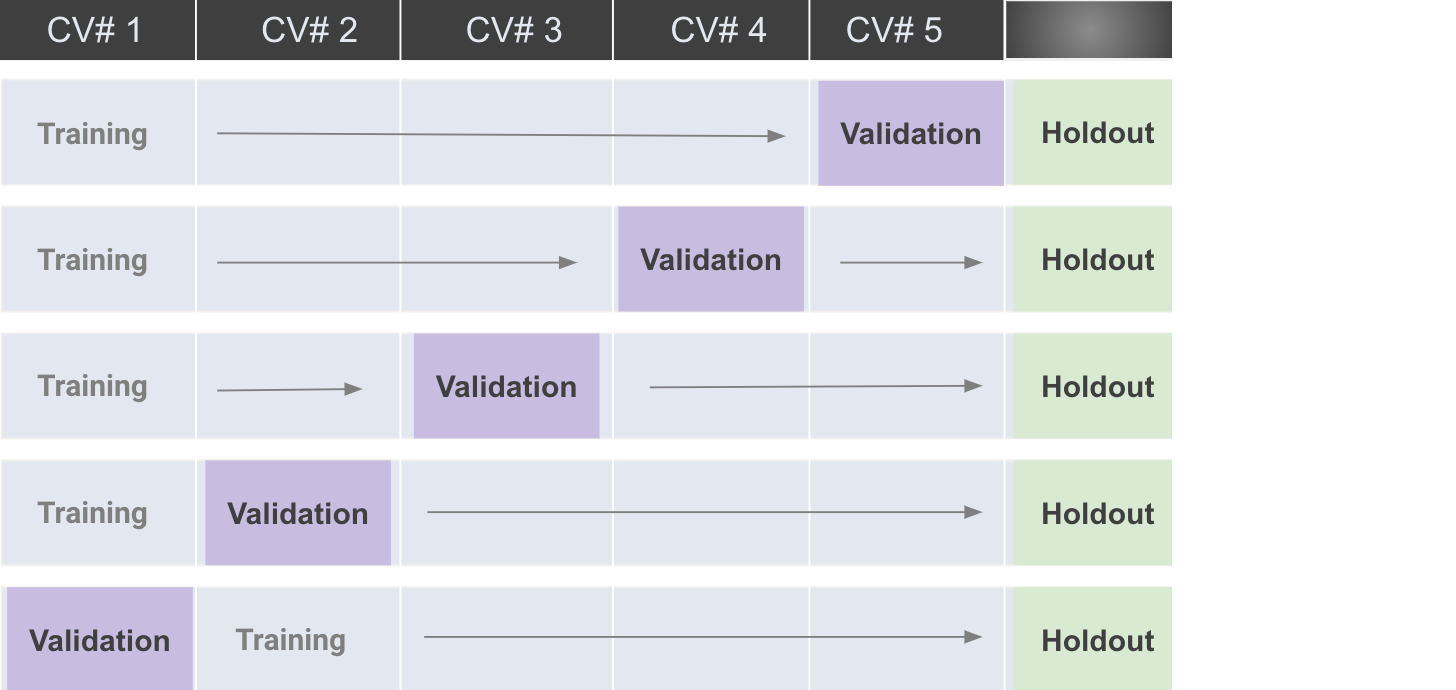
Data Partition Validation . Photo by scott webb on unsplash. Cvpartition defines a random partition on a data set. The train test validation split is a technique for partitioning data into training, validation, and test sets. Use the validation set to evaluate results from the training set. The results demonstrate that the approach has a higher. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. After repeated use of the validation set suggests that your model is. Learn how to do it, and what the benefits are.
from docs.datarobot.com
Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. After repeated use of the validation set suggests that your model is. The results demonstrate that the approach has a higher. The train test validation split is a technique for partitioning data into training, validation, and test sets. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Use the validation set to evaluate results from the training set. Photo by scott webb on unsplash. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Cvpartition defines a random partition on a data set. Learn how to do it, and what the benefits are.
Data partitioning and validation DataRobot docs
Data Partition Validation Photo by scott webb on unsplash. After repeated use of the validation set suggests that your model is. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Photo by scott webb on unsplash. The results demonstrate that the approach has a higher. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Use the validation set to evaluate results from the training set. Cvpartition defines a random partition on a data set. Learn how to do it, and what the benefits are. The train test validation split is a technique for partitioning data into training, validation, and test sets.
From docs.datarobot.com
Data partitioning and validation DataRobot docs Data Partition Validation After repeated use of the validation set suggests that your model is. The results demonstrate that the approach has a higher. Photo by scott webb on unsplash. Learn how to do it, and what the benefits are. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. If you want to split the data set. Data Partition Validation.
From www.researchgate.net
A visualization of the data partition for training, validation, and Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Photo by scott webb on unsplash. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. The train test validation split is a technique for partitioning data. Data Partition Validation.
From www.datarobot.com
CrossValidation DataRobot AI Wiki Data Partition Validation The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Learn how to do it, and what the benefits are. The train test validation split is a technique for partitioning data into training, validation, and test sets. Use the validation set to evaluate results from the training set. Photo by scott webb on unsplash. After. Data Partition Validation.
From www.datasunrise.com
What is Partitioning? Data Partition Validation Use the validation set to evaluate results from the training set. Photo by scott webb on unsplash. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Learn how to do it, and what the benefits are. The results demonstrate that the approach has a higher. The train. Data Partition Validation.
From realbitt.blogspot.com
SQL Server Table Partitioning technique Rembox Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Cvpartition defines a random partition on a data set. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Photo by scott webb on unsplash. The train. Data Partition Validation.
From www.yugabyte.com
Distributed SQL Sharding and Partitioning YugabyteDB Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Cvpartition defines a random partition on a data set. The results demonstrate that the approach has a higher. Learn how to do it, and what the benefits are. The train test validation split is a technique for partitioning. Data Partition Validation.
From www.sqlshack.com
Table Partitioning in Azure SQL Database Data Partition Validation Cvpartition defines a random partition on a data set. The results demonstrate that the approach has a higher. Use the validation set to evaluate results from the training set. After repeated use of the validation set suggests that your model is. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Photo by scott webb. Data Partition Validation.
From www.researchgate.net
Overview of the data partitioning and stratified crossvalidation Data Partition Validation Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. The results demonstrate that the approach has a higher. The train test validation split is a technique. Data Partition Validation.
From www.codeproject.com
Introduction to Machine Learning CodeProject Data Partition Validation Use the validation set to evaluate results from the training set. Photo by scott webb on unsplash. The train test validation split is a technique for partitioning data into training, validation, and test sets. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Cvpartition defines a random partition. Data Partition Validation.
From docs.griddb.net
Database function GridDB Docs Data Partition Validation The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. The results demonstrate that the approach has a higher. Cvpartition defines a random partition on a data set. After repeated use of the validation set suggests that your model is. Use the validation set to evaluate results from the training set. Learn how to do. Data Partition Validation.
From arpitbhayani.me
Data Partitioning Data Partition Validation Cvpartition defines a random partition on a data set. Photo by scott webb on unsplash. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. After repeated. Data Partition Validation.
From learn.microsoft.com
データのパーティション分割戦略 Azure Architecture Center Microsoft Learn Data Partition Validation The results demonstrate that the approach has a higher. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. After repeated use of the validation set suggests. Data Partition Validation.
From www.researchgate.net
a Partitioning of initial data into training, testing and validation Data Partition Validation The results demonstrate that the approach has a higher. The train test validation split is a technique for partitioning data into training, validation, and test sets. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Cvpartition defines a random partition on a data set. The novel approach is. Data Partition Validation.
From help.sap.com
SAP Help Portal Data Partition Validation After repeated use of the validation set suggests that your model is. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. The results demonstrate that the approach has a higher. Cvpartition defines a random partition on a data set. Use the validation set to evaluate results from. Data Partition Validation.
From www.solver.com
Standard Data Partition solver Data Partition Validation Photo by scott webb on unsplash. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Use the validation set to evaluate results from the training set.. Data Partition Validation.
From www.chegg.com
For Analytic Solver, partition the data sets into 50 Data Partition Validation Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Use the validation set to evaluate results from the training set. The train test validation split is a technique for partitioning data into training, validation, and test sets. Photo by scott webb on unsplash. After repeated use of the. Data Partition Validation.
From www.mssqltips.com
How to partition data in Tabular SSAS Data Partition Validation Cvpartition defines a random partition on a data set. The results demonstrate that the approach has a higher. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Learn how to do it,. Data Partition Validation.
From www.solver.com
Standard Data Partition solver Data Partition Validation Cvpartition defines a random partition on a data set. The train test validation split is a technique for partitioning data into training, validation, and test sets. The results demonstrate that the approach has a higher. Use the validation set to evaluate results from the training set. Data splitting is a crucial process in machine learning, involving the partitioning of a. Data Partition Validation.
From github.com
GitHub mapequation/partitionvalidation Identifies partition Data Partition Validation Learn how to do it, and what the benefits are. The results demonstrate that the approach has a higher. After repeated use of the validation set suggests that your model is. Photo by scott webb on unsplash. Cvpartition defines a random partition on a data set. Use the validation set to evaluate results from the training set. The train test. Data Partition Validation.
From tech.dely.jp
Sharding vs. Partitioning Demystified Scaling Your Database dely Data Partition Validation The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. Use the validation set to evaluate results from the training set. Cvpartition defines a random partition on a data set. The results demonstrate that the approach has a higher. The train test validation split is a technique for partitioning data into training, validation, and test. Data Partition Validation.
From thinketl.com
Snowflake MicroPartitions & Data Clustering ThinkETL Data Partition Validation Use the validation set to evaluate results from the training set. Cvpartition defines a random partition on a data set. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. The train test. Data Partition Validation.
From www.analyticsvidhya.com
Top 7 cross validation techniques with Python Code Analytics Vidhya Data Partition Validation Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. After repeated use of the validation set suggests that your model is. If you want to split the data set once in two parts,. Data Partition Validation.
From www.chegg.com
Solved Using test data on 43 vehicles, an analyst fitted a Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Learn how to do it, and what the benefits are. Use the validation set to evaluate results from the training set. The results demonstrate that the approach has a higher. Photo by scott webb on unsplash. Data splitting. Data Partition Validation.
From www.youtube.com
Partitioning data into training and validation datasets using R YouTube Data Partition Validation Use the validation set to evaluate results from the training set. After repeated use of the validation set suggests that your model is. The results demonstrate that the approach has a higher. The train test validation split is a technique for partitioning data into training, validation, and test sets. If you want to split the data set once in two. Data Partition Validation.
From www.alexdebrie.com
Everything you need to know about DynamoDB Partitions DeBrie Advisory Data Partition Validation The train test validation split is a technique for partitioning data into training, validation, and test sets. Photo by scott webb on unsplash. The results demonstrate that the approach has a higher. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. After repeated use of the validation set. Data Partition Validation.
From docs.datarobot.com
Data partitioning and validation DataRobot docs Data Partition Validation The train test validation split is a technique for partitioning data into training, validation, and test sets. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. After repeated use of the validation set suggests that your model is. The results demonstrate that the approach has a higher.. Data Partition Validation.
From www.researchgate.net
Data partitioning for crossvalidation and external validation set Data Partition Validation The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. The train test validation split is a technique for partitioning data into training, validation, and test sets. Photo by scott webb on unsplash. After repeated use of the validation set suggests that your model is. The results demonstrate that the approach has a higher. Cvpartition. Data Partition Validation.
From www.chegg.com
For R. partition data sets into 70 training and 30 Data Partition Validation Cvpartition defines a random partition on a data set. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. If you want to split the data set once in two parts, you can use. Data Partition Validation.
From www.singlestore.com
Database Sharding vs. Partitioning What’s the Difference? Data Partition Validation Photo by scott webb on unsplash. Use the validation set to evaluate results from the training set. Cvpartition defines a random partition on a data set. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. The train test validation split is a technique for partitioning data into. Data Partition Validation.
From www.cockroachlabs.com
What is data partitioning, and how to do it right Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Learn how to do it, and what the benefits are. After repeated use of the validation set suggests that your model is. Photo by scott webb on unsplash. Cvpartition defines a random partition on a data set. Use. Data Partition Validation.
From www.researchgate.net
Nested crossfold validation data partitioning scheme. A. First, data Data Partition Validation The results demonstrate that the approach has a higher. Photo by scott webb on unsplash. After repeated use of the validation set suggests that your model is. Cvpartition defines a random partition on a data set. If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Data splitting. Data Partition Validation.
From algotrading101.com
Train/Test Split and Cross Validation A Python Tutorial Data Partition Validation If you want to split the data set once in two parts, you can use numpy.random.shuffle, or numpy.random.permutation if you need to. Cvpartition defines a random partition on a data set. The novel approach is validated using simulated data and electrophysiological recordings in humans and rodents. The train test validation split is a technique for partitioning data into training, validation,. Data Partition Validation.
From recoverit.wondershare.fr
Qu'estce que la partition de données de base Data Partition Validation Learn how to do it, and what the benefits are. After repeated use of the validation set suggests that your model is. Use the validation set to evaluate results from the training set. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Photo by scott webb on unsplash.. Data Partition Validation.
From www.v7labs.com
Train Test Validation Split How To & Best Practices [2024] Data Partition Validation The train test validation split is a technique for partitioning data into training, validation, and test sets. After repeated use of the validation set suggests that your model is. Learn how to do it, and what the benefits are. Use the validation set to evaluate results from the training set. If you want to split the data set once in. Data Partition Validation.
From questdb.io
What Is Database Partitioning? Data Partition Validation Cvpartition defines a random partition on a data set. The results demonstrate that the approach has a higher. Data splitting is a crucial process in machine learning, involving the partitioning of a dataset into different subsets, such as training,. Photo by scott webb on unsplash. If you want to split the data set once in two parts, you can use. Data Partition Validation.