Reduce In Rdd . Reduce is a spark action that aggregates a data set (rdd) element using a function. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. That function takes two arguments and returns one. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples.
from sparkbyexamples.com
To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. That function takes two arguments and returns one. Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary.
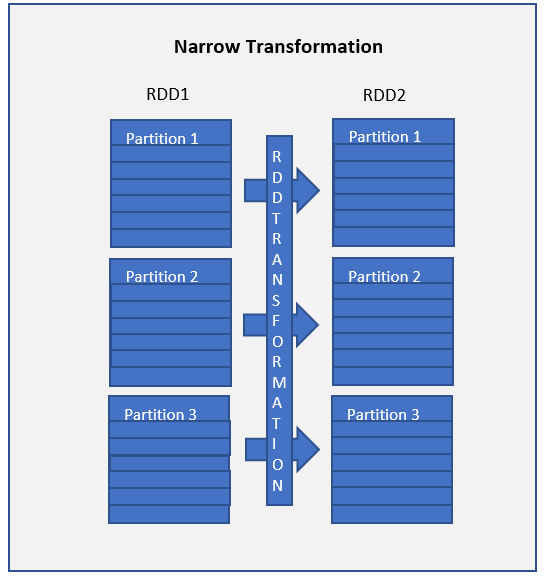
Spark RDD Transformations with examples Spark By {Examples}
Reduce In Rdd Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Learn to use reduce () with java, python examples. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Reduce is a spark action that aggregates a data set (rdd) element using a function. That function takes two arguments and returns one. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive.
From www.analyticsvidhya.com
Create RDD in Apache Spark using Pyspark Analytics Vidhya Reduce In Rdd That function takes two arguments and returns one. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Reduce is a spark action that aggregates a data set (rdd) element using a function. In this pyspark rdd tutorial section, i will explain how to use persist () and cache. Reduce In Rdd.
From data-flair.training
Spark RDD OperationsTransformation & Action with Example DataFlair Reduce In Rdd Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Spark rdd reduce () aggregate action function is used to calculate min, max,. Reduce In Rdd.
From www.javaprogramto.com
Java Spark RDD reduce() Examples sum, min and max opeartions Reduce In Rdd In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Reduce is a spark action that aggregates a data set (rdd) element using a function. That function takes two arguments and returns one. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using. Reduce In Rdd.
From www.youtube.com
What is RDD partitioning YouTube Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the. Reduce In Rdd.
From www.cloudduggu.com
Apache Spark RDD Introduction Tutorial CloudDuggu Reduce In Rdd Learn to use reduce () with java, python examples. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. To summarize reduce,. Reduce In Rdd.
From bigdataworld.ir
معرفی و آشنایی با آپاچی اسپارک مدرسه علوم داده و بیگ دیتا Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Spark rdd reduce. Reduce In Rdd.
From sparkbyexamples.com
Spark RDD Transformations with examples Spark By {Examples} Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. That function takes two arguments and returns one. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive.. Reduce In Rdd.
From www.researchgate.net
Examples of assignment rules used in RDD. RDD, regression discontinuity Reduce In Rdd Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Reduce is a spark action that aggregates a data set (rdd) element using a function. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i. Reduce In Rdd.
From www.educba.com
What is RDD? How It Works Skill & Scope Features & Operations Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative. Reduce In Rdd.
From www.linkedin.com
21 map() and reduce () in RDD’s Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. That function takes two arguments and returns one.. Reduce In Rdd.
From www.youtube.com
Pyspark RDD Operations Actions in Pyspark RDD Fold vs Reduce Glom Reduce In Rdd Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Spark rdd reduce () aggregate action function is. Reduce In Rdd.
From www.codingninjas.com
What are Resilient Distributed Dataset (RDD)? Coding Ninjas Reduce In Rdd In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Reduce is a spark action that aggregates a data set (rdd) element using a function. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Spark rdd reduce () aggregate action function. Reduce In Rdd.
From www.data-transitionnumerique.com
Comprendre les RDD pour mieux Développer en Spark Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that. Reduce In Rdd.
From intellipaat.com
What is RDD in Spark Learn about spark RDD Intellipaat Reduce In Rdd Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Pyspark cache and p ersist are optimization techniques to improve the performance of the. Reduce In Rdd.
From www.turing.com
Resilient Distribution Dataset Immutability in Apache Spark Reduce In Rdd In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. That function takes two arguments and returns one.. Reduce In Rdd.
From ittutorial.org
PySpark RDD Example IT Tutorial Reduce In Rdd To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Reduce is a spark action that aggregates a data set (rdd) element using a function. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Learn to. Reduce In Rdd.
From www.bigdatainrealworld.com
What is RDD? Big Data In Real World Reduce In Rdd Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. That function takes two arguments and returns one. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Learn to use reduce () with java, python examples. Spark. Reduce In Rdd.
From www.youtube.com
RDD Advance Transformation And Actions groupbykey And reducebykey Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Learn to use reduce () with java, python examples. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. That function. Reduce In Rdd.
From www.analyticsvidhya.com
Spark Transformations and Actions On RDD Reduce In Rdd Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache. Reduce In Rdd.
From www.freepik.com
Premium Vector reduce reuse recycle symbol set. Red, blue & green Reduce In Rdd That function takes two arguments and returns one. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Callable [[t, t], t]). Reduce In Rdd.
From www.youtube.com
33 Spark RDD Actions reduce() Code Demo 2 YouTube Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Learn to use reduce () with java, python examples. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. In this pyspark rdd tutorial section, i will explain how to use persist () and. Reduce In Rdd.
From zhuanlan.zhihu.com
RDD(二):RDD算子 知乎 Reduce In Rdd Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Reduce is a spark action that aggregates a data set (rdd) element using a function. Learn to use reduce () with java, python. Reduce In Rdd.
From japaneseclass.jp
Images of RDD JapaneseClass.jp Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. That function takes two arguments and returns one. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Learn to use reduce. Reduce In Rdd.
From sparkbyexamples.com
PySpark Convert DataFrame to RDD Spark By {Examples} Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Learn to use reduce () with java, python examples. That function takes two arguments and returns one. In this pyspark rdd tutorial section, i. Reduce In Rdd.
From zhenye-na.github.io
APIOriented Programming RDD Programming Zhenye's Blog Reduce In Rdd In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Learn to use reduce () with java, python examples. Spark rdd reduce () aggregate action function is. Reduce In Rdd.
From note-on-clouds.blogspot.com
[SPARK] RDD, Action 和 Transformation (2) Reduce In Rdd That function takes two arguments and returns one. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Reduce is a spark action that aggregates a data set (rdd) element using a function. To summarize reduce, excluding driver side. Reduce In Rdd.
From slideplayer.com
Introduction to Hadoop and Spark ppt download Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Callable [[t, t], t]) → t [source] ¶ reduces the elements of. Reduce In Rdd.
From www.prathapkudupublog.com
Snippets Common methods in RDD Reduce In Rdd Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Spark rdd reduce () aggregate action function is used to calculate min, max, and. Reduce In Rdd.
From sparkbyexamples.com
Spark RDD reduce() function example Spark By {Examples} Reduce In Rdd Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Callable [[t, t], t]) → t [source] ¶ reduces the elements. Reduce In Rdd.
From zhenye-na.github.io
APIOriented Programming RDD Programming Zhenye's Blog Reduce In Rdd Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Spark rdd reduce () aggregate action function is. Reduce In Rdd.
From www.showmeai.tech
图解大数据 基于RDD大数据处理分析Spark操作 Reduce In Rdd In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Learn to use reduce () with java, python examples. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. To summarize reduce, excluding driver side processing, uses. Reduce In Rdd.
From abs-tudelft.github.io
Resilient Distributed Datasets for Big Data Lab Manual Reduce In Rdd Learn to use reduce () with java, python examples. In this pyspark rdd tutorial section, i will explain how to use persist () and cache () methods on rdd with examples. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Reduce is a spark action that aggregates a. Reduce In Rdd.
From sparkbyexamples.com
PySpark RDD Tutorial Learn with Examples Spark By {Examples} Reduce In Rdd Learn to use reduce () with java, python examples. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶. Reduce In Rdd.
From www.youtube.com
Spark RDD Transformations and Actions PySpark Tutorial for Beginners Reduce In Rdd Learn to use reduce () with java, python examples. That function takes two arguments and returns one. To summarize reduce, excluding driver side processing, uses exactly the same mechanisms (mappartitions) as the basic. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. In this pyspark rdd tutorial section,. Reduce In Rdd.
From data-flair.training
PySpark RDD With Operations and Commands DataFlair Reduce In Rdd Reduce is a spark action that aggregates a data set (rdd) element using a function. Pyspark cache and p ersist are optimization techniques to improve the performance of the rdd jobs that are iterative and interactive. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i. Reduce In Rdd.