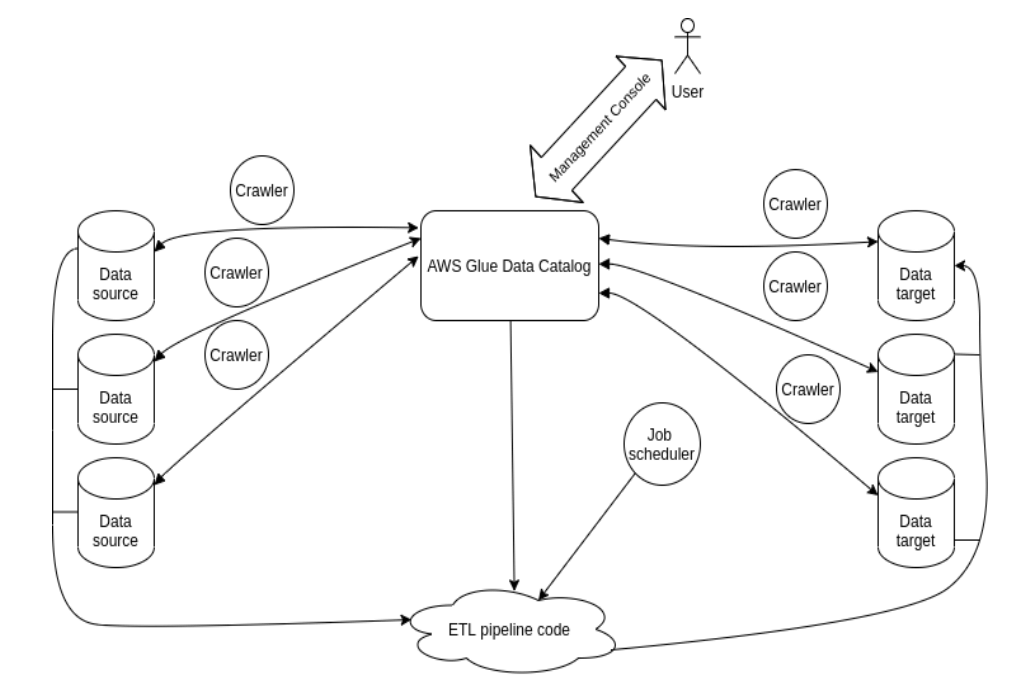
Partitioned Data In Aws Glue . i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. method 1 — glue crawlers: Aws glue crawlers is one of the best options to crawl the data and generate partitions. using aws glue, create a table in your data catalog with appropriate partitioning settings. Specify the partitioning columns and. To filter on partitions in the aws glue data catalog, use a pushdown predicate. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce.
from www.upsolver.com
method 1 — glue crawlers: i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. using aws glue, create a table in your data catalog with appropriate partitioning settings. Aws glue crawlers is one of the best options to crawl the data and generate partitions. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. Specify the partitioning columns and. To filter on partitions in the aws glue data catalog, use a pushdown predicate.
AWS Glue Features, Components, Benefits & Limitations Upsolver
Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. To filter on partitions in the aws glue data catalog, use a pushdown predicate. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. Specify the partitioning columns and. method 1 — glue crawlers: using aws glue, create a table in your data catalog with appropriate partitioning settings. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. Aws glue crawlers is one of the best options to crawl the data and generate partitions.
From www.upsolver.com
AWS Glue Features, Components, Benefits & Limitations Upsolver Partitioned Data In Aws Glue aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. Specify the partitioning columns and. using aws glue, create a table in your data catalog with appropriate partitioning settings. Aws glue crawlers is one of the best options to crawl the data and generate partitions. i read that there is. Partitioned Data In Aws Glue.
From digitalcloud.training
AWS Glue Tutorial for Beginners Partitioned Data In Aws Glue using aws glue, create a table in your data catalog with appropriate partitioning settings. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. Aws. Partitioned Data In Aws Glue.
From www.hava.io
What is Amazon AWS Glue? Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. To filter on partitions in the aws glue data catalog, use a pushdown predicate. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. i read that there is no. Partitioned Data In Aws Glue.
From www.youtube.com
How to build AWS Glue ETL with Python shell Data pipeline Read data Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. Aws glue crawlers is one of the best options to crawl the data and generate partitions. . Partitioned Data In Aws Glue.
From retromania.cz
Overall advantageous Muscular aws glue best practices Citizen Decimal Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. To filter on partitions in the aws glue data catalog, use a pushdown predicate. method 1 — glue crawlers: Specify the partitioning columns and. Aws glue crawlers is one of the best options to crawl the data. Partitioned Data In Aws Glue.
From laptrinhx.com
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Partitioned Data In Aws Glue Specify the partitioning columns and. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. To filter on partitions in the aws glue data catalog, use a pushdown predicate. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable.. Partitioned Data In Aws Glue.
From www.workfall.com
How to build a serverless eventdriven workflow with AWS Glue and Partitioned Data In Aws Glue partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. method 1 — glue crawlers: To filter on partitions in the aws glue data catalog, use a pushdown predicate. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and. Partitioned Data In Aws Glue.
From laptrinhx.com
How to Use AWS Glue to Prepare and Load Amazon S3 Data for Analysis by Partitioned Data In Aws Glue Specify the partitioning columns and. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. using aws glue, create a table in your data catalog with appropriate partitioning settings. method 1 — glue crawlers: Aws glue crawlers is one of the best options to crawl the. Partitioned Data In Aws Glue.
From awstip.com
Automatically add partitions to AWS Glue using Node/Lambda only by Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. Aws glue crawlers is one of the best options to crawl the data and generate partitions. method 1 — glue crawlers: given that you have a partitioned table in aws glue data catalog, there are few. Partitioned Data In Aws Glue.
From aws.amazon.com
Getting started with AWS Glue Data Quality from the AWS Glue Data Partitioned Data In Aws Glue Specify the partitioning columns and. To filter on partitions in the aws glue data catalog, use a pushdown predicate. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. Aws. Partitioned Data In Aws Glue.
From abcloudz.com
AWS Glue Technology solutions ABCloudZ Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. Aws glue crawlers is one of the best options to crawl the data and generate partitions. . Partitioned Data In Aws Glue.
From www.youtube.com
Create Partitioned Table AWS Glue From simple CSV file with 1M records Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. To filter on partitions in the aws glue data catalog, use a pushdown predicate. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. using. Partitioned Data In Aws Glue.
From www.youtube.com
AWS Glue DataBrew Demo Video For Beginners YouTube Partitioned Data In Aws Glue Specify the partitioning columns and. using aws glue, create a table in your data catalog with appropriate partitioning settings. To filter on partitions in the aws glue data catalog, use a pushdown predicate. Aws glue crawlers is one of the best options to crawl the data and generate partitions. partitions are used in conjunction with s3 data stores. Partitioned Data In Aws Glue.
From docs.aws.haqm.com
Reference architecture with the AWS Glue product family AWS Glue Best Partitioned Data In Aws Glue aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. method 1 — glue crawlers: Specify the partitioning columns and. To filter on partitions in the aws glue. Partitioned Data In Aws Glue.
From genesis-aka.net
Set up CI/CD pipelines for AWS Glue DataBrew using AWS Developer Tools Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. To filter on partitions in the aws glue data catalog, use a pushdown predicate. Specify. Partitioned Data In Aws Glue.
From intellipaat.com
AWS Glue Tutorial for Beginners intellipaat Partitioned Data In Aws Glue i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. To filter on partitions in the aws glue data catalog, use a pushdown predicate. partitions are used in conjunction. Partitioned Data In Aws Glue.
From aws.amazon.com
Field Notes How to Build an AWS Glue Workflow using the AWS Cloud Partitioned Data In Aws Glue partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. To filter on partitions in the aws glue data catalog, use a pushdown predicate. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. aws. Partitioned Data In Aws Glue.
From aws.amazon.com
Automating Engine Training with Amazon Personalize and Partitioned Data In Aws Glue To filter on partitions in the aws glue data catalog, use a pushdown predicate. using aws glue, create a table in your data catalog with appropriate partitioning settings. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. method 1 — glue crawlers: partitions are used. Partitioned Data In Aws Glue.
From www.itbriefcase.net
Data Integration AWS Glue Overview IT Briefcase Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. Specify the partitioning columns and. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. partitions are used in conjunction with s3 data stores to organize. Partitioned Data In Aws Glue.
From aws.amazon.com
Improve Amazon Athena query performance using AWS Glue Data Catalog Partitioned Data In Aws Glue Aws glue crawlers is one of the best options to crawl the data and generate partitions. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable.. Partitioned Data In Aws Glue.
From docs.aws.amazon.com
Datenkatalog und Crawler in AWS Glue AWS Glue Partitioned Data In Aws Glue Aws glue crawlers is one of the best options to crawl the data and generate partitions. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. using aws glue, create a table in your data catalog with appropriate partitioning settings. method 1 — glue crawlers: . Partitioned Data In Aws Glue.
From thecodinginterface.com
Building Data Lakes in AWS with S3, Lambda, Glue, and Athena from Partitioned Data In Aws Glue method 1 — glue crawlers: partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. To filter on partitions in the aws glue data catalog, use a pushdown predicate. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and. Partitioned Data In Aws Glue.
From thecodinginterface.com
Managing S3 Data Store Partitions with AWS Glue Crawlers and Glue Partitioned Data In Aws Glue Aws glue crawlers is one of the best options to crawl the data and generate partitions. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. using aws glue,. Partitioned Data In Aws Glue.
From programmaticponderings.com
AWS Glue DataBrew Programmatic Ponderings Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. method 1 — glue crawlers: partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. i read that there is no way to overwrite. Partitioned Data In Aws Glue.
From noise.getoto.net
Enrich datasets for descriptive analytics with AWS Glue DataBrew Noise Partitioned Data In Aws Glue Specify the partitioning columns and. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. partitions are used in conjunction with s3 data stores to organize. Partitioned Data In Aws Glue.
From aws.amazon.com
Integrate AWS Glue Schema Registry with the AWS Glue Data Catalog to Partitioned Data In Aws Glue Aws glue crawlers is one of the best options to crawl the data and generate partitions. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. To filter on partitions in the aws glue data catalog, use a pushdown predicate. i read that there is no way to. Partitioned Data In Aws Glue.
From www.youtube.com
Load data from S3 to Redshift using AWS GlueAWS Glue Tutorial for Partitioned Data In Aws Glue using aws glue, create a table in your data catalog with appropriate partitioning settings. To filter on partitions in the aws glue data catalog, use a pushdown predicate. Aws glue crawlers is one of the best options to crawl the data and generate partitions. i read that there is no way to overwrite partitions in glue so we. Partitioned Data In Aws Glue.
From www.workfall.com
How to build a serverless eventdriven workflow with AWS Glue and Partitioned Data In Aws Glue aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. Specify the partitioning columns and. Aws glue crawlers is one of the best options to crawl the data and generate partitions. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can.. Partitioned Data In Aws Glue.
From aws.amazon.com
Simplify Snowflake data loading and processing with AWS Glue DataBrew Partitioned Data In Aws Glue Specify the partitioning columns and. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. To filter on partitions in the aws glue data catalog, use. Partitioned Data In Aws Glue.
From 9to5answer.com
[Solved] How to create AWS Glue table where partitions 9to5Answer Partitioned Data In Aws Glue aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. To filter on partitions in the aws glue data catalog, use a pushdown predicate. Aws glue crawlers is one of. Partitioned Data In Aws Glue.
From mindmajix.com
AWS Glue Tutorial for Beginners Managed ETL Service MindMajix Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. partitions are used in conjunction with s3 data stores to organize data using a clear naming. Partitioned Data In Aws Glue.
From acloudxpert.com
What is AWS Glue? A Cloud Xpert Partitioned Data In Aws Glue aws glue partition indexes are an important configuration to reduce overall data transfers and processing, and reduce. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. given that you have a partitioned table in aws glue data catalog, there are few ways in which. Partitioned Data In Aws Glue.
From noise.getoto.net
Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Partitioned Data In Aws Glue Aws glue crawlers is one of the best options to crawl the data and generate partitions. method 1 — glue crawlers: Specify the partitioning columns and. i read that there is no way to overwrite partitions in glue so we must use pyspark code similar to this:. To filter on partitions in the aws glue data catalog, use. Partitioned Data In Aws Glue.
From hevodata.com
Working With AWS Glue Data Catalog An Easy Guide 101 Hevo Partitioned Data In Aws Glue To filter on partitions in the aws glue data catalog, use a pushdown predicate. given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that is meaningful and navigable. Aws glue. Partitioned Data In Aws Glue.
From www.brightworkresearch.com
How to Slim and Replatforming the Data Warehouse with AWS Glue and Partitioned Data In Aws Glue given that you have a partitioned table in aws glue data catalog, there are few ways in which you can. using aws glue, create a table in your data catalog with appropriate partitioning settings. Specify the partitioning columns and. partitions are used in conjunction with s3 data stores to organize data using a clear naming convention that. Partitioned Data In Aws Glue.