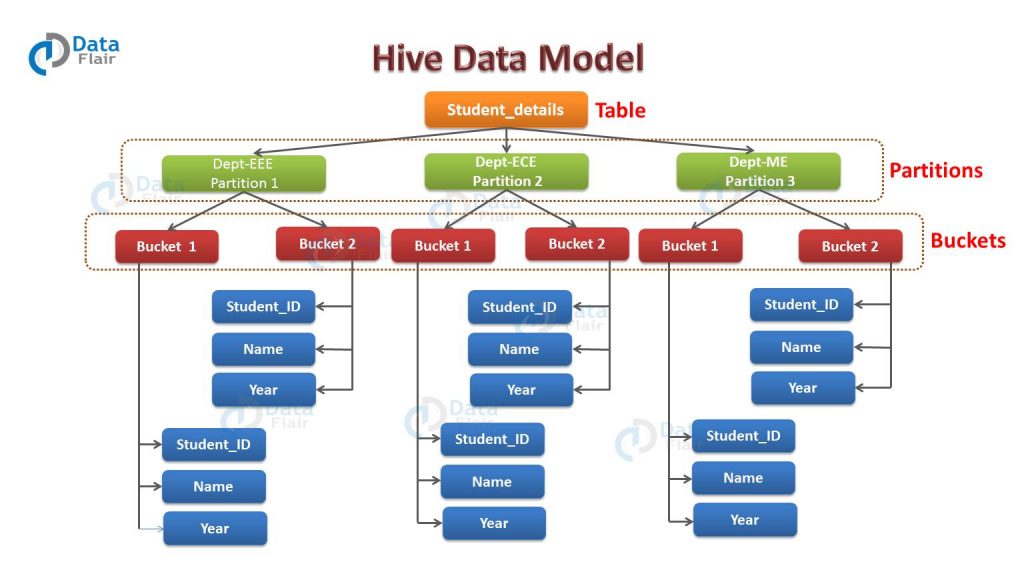
Bucketing Databricks . We are migrating a job from onprem to databricks. How to improve performance with bucketing. Both sides of the join should employ the same number of. The bucket by command allows you to sort the rows of spark sql table by a certain column. Learn how to improve databricks performance by using bucketing. Both sides have the same bucketing, and no shuffles are needed. We are trying to optimize the jobs but couldn't use bucketing because by default. If you then cache the sorted table, you can make subsequent. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. Definitely beyond the scope of this course, but here are some key points:
from data-flair.training
Definitely beyond the scope of this course, but here are some key points: The bucket by command allows you to sort the rows of spark sql table by a certain column. Both sides of the join should employ the same number of. We are trying to optimize the jobs but couldn't use bucketing because by default. If you then cache the sorted table, you can make subsequent. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. How to improve performance with bucketing. Both sides have the same bucketing, and no shuffles are needed. Learn how to improve databricks performance by using bucketing. We are migrating a job from onprem to databricks.
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair
Bucketing Databricks We are trying to optimize the jobs but couldn't use bucketing because by default. Both sides have the same bucketing, and no shuffles are needed. We are trying to optimize the jobs but couldn't use bucketing because by default. We are migrating a job from onprem to databricks. If you then cache the sorted table, you can make subsequent. Both sides of the join should employ the same number of. How to improve performance with bucketing. Learn how to improve databricks performance by using bucketing. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. Definitely beyond the scope of this course, but here are some key points: The bucket by command allows you to sort the rows of spark sql table by a certain column.
From www.youtube.com
Partitions in Data bricks YouTube Bucketing Databricks Learn how to improve databricks performance by using bucketing. We are trying to optimize the jobs but couldn't use bucketing because by default. We are migrating a job from onprem to databricks. Definitely beyond the scope of this course, but here are some key points: How to improve performance with bucketing. If you then cache the sorted table, you can. Bucketing Databricks.
From techblog.ap-com.co.jp
Setting up Databricks on AWS and creating a workspace APC 技術ブログ Bucketing Databricks Both sides of the join should employ the same number of. Definitely beyond the scope of this course, but here are some key points: Both sides have the same bucketing, and no shuffles are needed. The bucket by command allows you to sort the rows of spark sql table by a certain column. How to improve performance with bucketing. Partitioning. Bucketing Databricks.
From www.youtube.com
Working with Partitioned Data in Azure Databricks YouTube Bucketing Databricks Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. The bucket by command allows you to sort the rows of spark sql table by a certain column. Both sides have the same bucketing, and no shuffles are. Bucketing Databricks.
From medium.com
Mounting Amazon S3 Bucket to Databricks by Code_Marshal May, 2024 Bucketing Databricks We are trying to optimize the jobs but couldn't use bucketing because by default. How to improve performance with bucketing. Both sides of the join should employ the same number of. Both sides have the same bucketing, and no shuffles are needed. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive. Bucketing Databricks.
From cloud.google.com
Connecting Databricks to BigQuery Google Cloud Bucketing Databricks Both sides of the join should employ the same number of. The bucket by command allows you to sort the rows of spark sql table by a certain column. Both sides have the same bucketing, and no shuffles are needed. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob. Bucketing Databricks.
From k21academy.com
Structured Streaming With Azure DataBricks K21 Academy Bucketing Databricks How to improve performance with bucketing. Definitely beyond the scope of this course, but here are some key points: Learn how to improve databricks performance by using bucketing. We are migrating a job from onprem to databricks. The bucket by command allows you to sort the rows of spark sql table by a certain column. Partitioning (bucketing) your delta data. Bucketing Databricks.
From medium.com
Connecting an AWS S3 Bucket to Databricks A StepbyStep Guide by Bucketing Databricks Definitely beyond the scope of this course, but here are some key points: Both sides of the join should employ the same number of. The bucket by command allows you to sort the rows of spark sql table by a certain column. Learn how to improve databricks performance by using bucketing. How to improve performance with bucketing. We are trying. Bucketing Databricks.
From docs.databricks.com
Google BigQuery Databricks on AWS Bucketing Databricks We are trying to optimize the jobs but couldn't use bucketing because by default. Both sides of the join should employ the same number of. Definitely beyond the scope of this course, but here are some key points: We are migrating a job from onprem to databricks. Learn how to improve databricks performance by using bucketing. If you then cache. Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks How to improve performance with bucketing. If you then cache the sorted table, you can make subsequent. Definitely beyond the scope of this course, but here are some key points: Learn how to improve databricks performance by using bucketing. We are migrating a job from onprem to databricks. We are trying to optimize the jobs but couldn't use bucketing because. Bucketing Databricks.
From www.devopsschool.com
What is Databricks and use cases of Databricks? Bucketing Databricks Learn how to improve databricks performance by using bucketing. The bucket by command allows you to sort the rows of spark sql table by a certain column. Both sides of the join should employ the same number of. If you then cache the sorted table, you can make subsequent. We are trying to optimize the jobs but couldn't use bucketing. Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks Both sides have the same bucketing, and no shuffles are needed. If you then cache the sorted table, you can make subsequent. How to improve performance with bucketing. Both sides of the join should employ the same number of. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive — your data. Bucketing Databricks.
From www.youtube.com
How to Mount or Connect your AWS S3 Bucket in Databricks YouTube Bucketing Databricks We are trying to optimize the jobs but couldn't use bucketing because by default. If you then cache the sorted table, you can make subsequent. We are migrating a job from onprem to databricks. Definitely beyond the scope of this course, but here are some key points: The bucket by command allows you to sort the rows of spark sql. Bucketing Databricks.
From docs.developers.optimizely.com
How user bucketing works Optimizely Full Stack Bucketing Databricks The bucket by command allows you to sort the rows of spark sql table by a certain column. Definitely beyond the scope of this course, but here are some key points: Both sides of the join should employ the same number of. Learn how to improve databricks performance by using bucketing. If you then cache the sorted table, you can. Bucketing Databricks.
From www.databricks.com
How to Monitor Your Databricks Workspace with Audit Logs The Bucketing Databricks Both sides of the join should employ the same number of. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. We are trying to optimize the jobs but couldn't use bucketing because by default. Learn how to. Bucketing Databricks.
From stackoverflow.com
pyspark How to write the data back to Big Query using Databricks Bucketing Databricks Definitely beyond the scope of this course, but here are some key points: Both sides have the same bucketing, and no shuffles are needed. We are trying to optimize the jobs but couldn't use bucketing because by default. Both sides of the join should employ the same number of. How to improve performance with bucketing. We are migrating a job. Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks Definitely beyond the scope of this course, but here are some key points: Both sides of the join should employ the same number of. We are migrating a job from onprem to databricks. If you then cache the sorted table, you can make subsequent. How to improve performance with bucketing. Partitioning (bucketing) your delta data obviously has a positive —. Bucketing Databricks.
From stackoverflow.com
databricks load file from s3 bucket path parameter Stack Overflow Bucketing Databricks We are trying to optimize the jobs but couldn't use bucketing because by default. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. If you then cache the sorted table, you can make subsequent. Both sides have. Bucketing Databricks.
From www.youtube.com
Day 29 Read Data From AWS S3 Bucket 30 Days of Databricks YouTube Bucketing Databricks We are migrating a job from onprem to databricks. Learn how to improve databricks performance by using bucketing. We are trying to optimize the jobs but couldn't use bucketing because by default. How to improve performance with bucketing. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and. Bucketing Databricks.
From www.youtube.com
Databricks Mounts Mount your AWS S3 bucket to Databricks YouTube Bucketing Databricks Definitely beyond the scope of this course, but here are some key points: Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. Both sides have the same bucketing, and no shuffles are needed. We are trying to. Bucketing Databricks.
From www.youtube.com
aws s3 bucket parquet file Connect AWS S3 Bucket in Databricks Bucketing Databricks Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. We are trying to optimize the jobs but couldn't use bucketing because by default. How to improve performance with bucketing. Both sides of the join should employ the. Bucketing Databricks.
From bigdatansql.com
Bucketing_With_Partitioning Big Data and SQL Bucketing Databricks The bucket by command allows you to sort the rows of spark sql table by a certain column. If you then cache the sorted table, you can make subsequent. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and. Bucketing Databricks.
From www.simplilearn.com
Advanced Hive Concepts and Data File Partitioning Tutorial Simplilearn Bucketing Databricks How to improve performance with bucketing. If you then cache the sorted table, you can make subsequent. We are migrating a job from onprem to databricks. We are trying to optimize the jobs but couldn't use bucketing because by default. Both sides have the same bucketing, and no shuffles are needed. The bucket by command allows you to sort the. Bucketing Databricks.
From www.okera.com
Bucketing in Hive What is Bucketing in Hive? Okera Bucketing Databricks Both sides have the same bucketing, and no shuffles are needed. We are trying to optimize the jobs but couldn't use bucketing because by default. The bucket by command allows you to sort the rows of spark sql table by a certain column. Learn how to improve databricks performance by using bucketing. We are migrating a job from onprem to. Bucketing Databricks.
From www.databricks.com
How to Use the Bucket Brigade to Secure Your Public AWS S3 Buckets Bucketing Databricks How to improve performance with bucketing. Definitely beyond the scope of this course, but here are some key points: Both sides have the same bucketing, and no shuffles are needed. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage). Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks If you then cache the sorted table, you can make subsequent. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. We are trying to optimize the jobs but couldn't use bucketing because by default. Both sides of. Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks The bucket by command allows you to sort the rows of spark sql table by a certain column. If you then cache the sorted table, you can make subsequent. How to improve performance with bucketing. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query. Bucketing Databricks.
From aws.amazon.com
Optimize data layout by bucketing with Amazon Athena and AWS Glue to Bucketing Databricks We are migrating a job from onprem to databricks. Both sides have the same bucketing, and no shuffles are needed. If you then cache the sorted table, you can make subsequent. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only. Bucketing Databricks.
From www.databricks.com
Orchestrate Databricks on AWS with Airflow Databricks Blog Bucketing Databricks Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. Both sides of the join should employ the same number of. Definitely beyond the scope of this course, but here are some key points: The bucket by command. Bucketing Databricks.
From exolwjxvu.blob.core.windows.net
Partition Key Databricks at Cathy Dalzell blog Bucketing Databricks Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. Both sides of the join should employ the same number of. We are migrating a job from onprem to databricks. If you then cache the sorted table, you. Bucketing Databricks.
From medium.com
Databricks — Qué es y qué no es “Bucketing” by Fermín Martínez Bucketing Databricks Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. The bucket by command allows you to sort the rows of spark sql table by a certain column. Both sides have the same bucketing, and no shuffles are. Bucketing Databricks.
From blog.det.life
Data Partitioning and Bucketing Examples and Best Practices by Bucketing Databricks We are migrating a job from onprem to databricks. How to improve performance with bucketing. Definitely beyond the scope of this course, but here are some key points: Learn how to improve databricks performance by using bucketing. We are trying to optimize the jobs but couldn't use bucketing because by default. Partitioning (bucketing) your delta data obviously has a positive. Bucketing Databricks.
From www.geeksforgeeks.org
How Do I Add A S3 Bucket To Databricks ? Bucketing Databricks Both sides of the join should employ the same number of. If you then cache the sorted table, you can make subsequent. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob storage) and when you query this store you only need to load. We are trying to optimize the. Bucketing Databricks.
From data-flair.training
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Bucketing Databricks Both sides of the join should employ the same number of. If you then cache the sorted table, you can make subsequent. The bucket by command allows you to sort the rows of spark sql table by a certain column. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive — your. Bucketing Databricks.
From community.databricks.com
bucket ownership of s3 bucket in databricks Databricks Community 4348 Bucketing Databricks The bucket by command allows you to sort the rows of spark sql table by a certain column. How to improve performance with bucketing. We are trying to optimize the jobs but couldn't use bucketing because by default. Learn how to improve databricks performance by using bucketing. If you then cache the sorted table, you can make subsequent. Partitioning (bucketing). Bucketing Databricks.
From newbedev.com
Why is Spark saveAsTable with bucketBy creating thousands of files? Bucketing Databricks Learn how to improve databricks performance by using bucketing. Both sides of the join should employ the same number of. If you then cache the sorted table, you can make subsequent. We are migrating a job from onprem to databricks. Partitioning (bucketing) your delta data obviously has a positive — your data is filtered into separate buckets (folders in blob. Bucketing Databricks.