Yarn Job History Server . When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. View job history and time spent in various stages of the job: Use the following command format to view all logs for an application: If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. In the cloudera data platform (cdp) management console, go to. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server.
from www.qubole.com
In the cloudera data platform (cdp) management console, go to. Use the following command format to view all logs for an application: If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. View job history and time spent in various stages of the job:
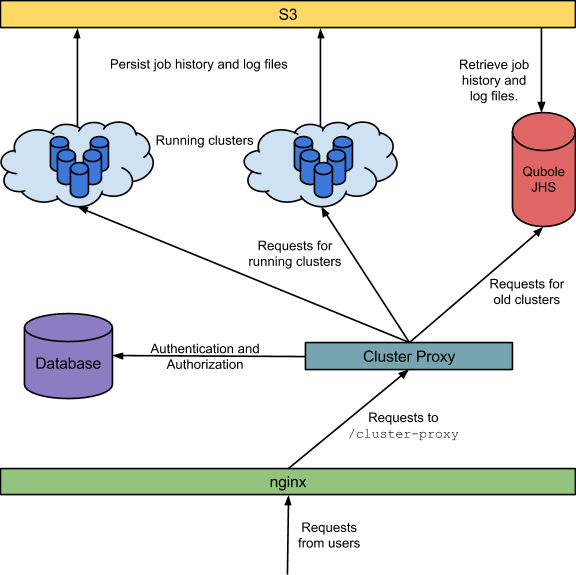
Multi tenant Job History Ephemeral Hadoop & Spark Clusters
Yarn Job History Server Use the following command format to view all logs for an application: The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. In the cloudera data platform (cdp) management console, go to. Use the following command format to view all logs for an application: By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). When the mapreduce applications are running, then you can access the logs from the yarn's web ui. View job history and time spent in various stages of the job:
From www.programmersought.com
[Hadoop04] Yarn job scheduling process Programmer Sought Yarn Job History Server Use the following command format to view all logs for an application: In the cloudera data platform (cdp) management console, go to. View job history and time spent in various stages of the job: @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. When the mapreduce applications are running, then you. Yarn Job History Server.
From www.slideserve.com
PPT Resource Management with YARN YARN Past, Present and Future Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. View job history and time spent in various stages of the job: @michael deguzis, yarn typically stores history. Yarn Job History Server.
From www.youtube.com
Startobservetest Apache Hadoop + Spark cluster when starting dfs Yarn Job History Server The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. View job history and time spent in various stages of the job: @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. Use the following command format to view all logs for. Yarn Job History Server.
From soft-tech-solutions.blogspot.com
How to manage YARN applications with Time line server? Soft Tech Yarn Job History Server In the cloudera data platform (cdp) management console, go to. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. By default, it uses the job history server to obtain application meta information. Yarn Job History Server.
From blog.csdn.net
Spark 配置历史服务器_spark.history.ui.portCSDN博客 Yarn Job History Server By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data. Yarn Job History Server.
From www.laiyy.top
Hadoop(3) yarn、history server、logs server Laiyy 的个人小站 Yarn Job History Server In the cloudera data platform (cdp) management console, go to. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. The storage and retrieval. Yarn Job History Server.
From docs.cloudera.com
Viewing the YARN job history Yarn Job History Server The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. View job history and time spent in various stages of the job: When the mapreduce applications are running, then you can access the logs from the yarn's web ui. Use the following command format to view all logs for an. Yarn Job History Server.
From www.youtube.com
Map Reduce Execution Framework MRv2+YARN Job Flow And Diffs With MRv1 Yarn Job History Server In the cloudera data platform (cdp) management console, go to. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The storage and retrieval of application’s current. Yarn Job History Server.
From blog.csdn.net
yarnsparkcluster配置history server并通过YARN跳转sparkui_spark 日志配置设置过期时间CSDN博客 Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. In the cloudera data platform (cdp) management console, go to. Use the following command format to view all logs for an application: If the ui is not able to connect to the job history server, it will attempt. Yarn Job History Server.
From www.laiyy.top
Hadoop(3) yarn、history server、logs server Laiyy 的个人小站 Yarn Job History Server If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). In the cloudera data platform (cdp) management console, go to. @michael deguzis, yarn typically. Yarn Job History Server.
From jobdrop.blogspot.com
How Hadoop Runs A Mapreduce Job Using Yarn Job Drop Yarn Job History Server In the cloudera data platform (cdp) management console, go to. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. When the. Yarn Job History Server.
From www.researchgate.net
1. YARN Architecture. When a client submits a job to the... Download Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. In the cloudera data platform (cdp) management console, go to. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. When the. Yarn Job History Server.
From 4hadooper.blogspot.com
Big Data YARN ( Yet Another Resource Negotiator ) Yarn Job History Server When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. View job history and time. Yarn Job History Server.
From www.geeksforgeeks.org
Hadoop YARN Architecture Yarn Job History Server By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). Use the following command format to view all logs for an application: In the cloudera data platform (cdp) management console, go to. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. If. Yarn Job History Server.
From blog.csdn.net
flink on yarn集群搭建_flinkonyarn集群部署CSDN博客 Yarn Job History Server If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. By default, it uses the job history server to obtain application meta information (for the log aggregation. Yarn Job History Server.
From www.waitingforcode.com
YARN or for Apache Spark? on articles Yarn Job History Server In the cloudera data platform (cdp) management console, go to. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. View job history and time spent in various stages of the. Yarn Job History Server.
From www.edureka.co
Apache Hadoop YARN Introduction to YARN Architecture Edureka Yarn Job History Server View job history and time spent in various stages of the job: When the mapreduce applications are running, then you can access the logs from the yarn's web ui. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). If the ui is not able to connect to the job. Yarn Job History Server.
From blog.csdn.net
SparkYarn模式配置历史服务运行流程端口号总结_SmallScorpion的博客CSDN博客 Yarn Job History Server View job history and time spent in various stages of the job: The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. In the cloudera data platform (cdp) management console, go to. @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce.. Yarn Job History Server.
From data-flair.training
Hadoop YARN Resource Manager A Yarn Tutorial DataFlair Yarn Job History Server By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data. Yarn Job History Server.
From hadoop.apache.org
Apache Hadoop 3.3.3 Hadoop YARN Federation Yarn Job History Server View job history and time spent in various stages of the job: The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. If the ui is not able to connect to. Yarn Job History Server.
From winway.github.io
YARN集群任务一直处于Accepted状态无法Running winway's blog Yarn Job History Server When the mapreduce applications are running, then you can access the logs from the yarn's web ui. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). View job history and time spent in various stages of the job: The storage and retrieval of application’s current and historic information in. Yarn Job History Server.
From community.cloudera.com
Understanding basics of HDFS and YARN Cloudera Community Yarn Job History Server View job history and time spent in various stages of the job: In the cloudera data platform (cdp) management console, go to. Use the following command format to view all logs for an application: When the mapreduce applications are running, then you can access the logs from the yarn's web ui. By default, it uses the job history server to. Yarn Job History Server.
From docs.cloudera.com
Understanding YARN architecture Yarn Job History Server @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. Use the following command format to view all logs for an application: View job history and. Yarn Job History Server.
From github.com
Deploying dask on YARN in an enterprise setting · Issue 2043 · dask Yarn Job History Server When the mapreduce applications are running, then you can access the logs from the yarn's web ui. The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. Use. Yarn Job History Server.
From zhuanlan.zhihu.com
什么!Hadoop只知道MR History Server?YARN的Timeline Server你居然不知道? 知乎 Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). In the cloudera data platform (cdp) management console, go to. If the ui is not able to connect. Yarn Job History Server.
From blog.csdn.net
spark on yarn图形化任务监控利器:Historyserver帮你理解spark的任务执行过程_富兰克林008的博客CSDN博客 Yarn Job History Server Use the following command format to view all logs for an application: If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. In the cloudera data platform (cdp) management console, go to. @michael deguzis, yarn typically stores history of all the application in either. Yarn Job History Server.
From blog.cloudera.com
Apache Hadoop YARN Concepts and Applications Cloudera Blog Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). If the ui is not able to connect to the job history server, it will attempt to obtain. Yarn Job History Server.
From blog.csdn.net
Spark 使用Yarn管理器开启历史日志服务、查看日志_spark历史日志集成到yarn历史日志CSDN博客 Yarn Job History Server When the mapreduce applications are running, then you can access the logs from the yarn's web ui. Use the following command format to view all logs for an application: View job history and time spent in various stages of the job: By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s. Yarn Job History Server.
From docs.cloudera.com
Add queues using YARN Queue Manager UI Yarn Job History Server By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. @michael deguzis, yarn typically stores history of all the application in either mapreduce history. Yarn Job History Server.
From www.qubole.com
Multi tenant Job History Ephemeral Hadoop & Spark Clusters Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. Use the following command format to view all logs for an application:. Yarn Job History Server.
From blog.csdn.net
hadoop yarn jobhistoryserver 配置_yarn开启jobhistoryserverCSDN博客 Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. Use the following command format to view all logs for an application: The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. When the mapreduce applications are running,. Yarn Job History Server.
From blog.csdn.net
Flink on Yarn两种运行模式详解_flink on yarn的运行模式CSDN博客 Yarn Job History Server The history of spark jobs submitted to yarn is handled by a completely separate service called the spark history server. Use the following command format to view all logs for an application: If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. When the. Yarn Job History Server.
From wongxingjun.github.io
Spark on YARN配置日志 UI FlyingMcdull Yarn Job History Server By default, it uses the job history server to obtain application meta information (for the log aggregation file controller’s containerlogsrequest). View job history and time spent in various stages of the job: When the mapreduce applications are running, then you can access the logs from the yarn's web ui. If the ui is not able to connect to the job. Yarn Job History Server.
From blog.csdn.net
hadoop yarn jobhistoryserver 配置_yarn开启jobhistoryserverCSDN博客 Yarn Job History Server The storage and retrieval of application’s current and historic information in a generic fashion is addressed in yarn through the timeline server. If the ui is not able to connect to the job history server, it will attempt to obtain these pieces of data from the timeline server. View job history and time spent in various stages of the job:. Yarn Job History Server.
From hadoop.apache.org
Apache Hadoop 2.10.1 The YARN Timeline Service v.2 Yarn Job History Server In the cloudera data platform (cdp) management console, go to. When the mapreduce applications are running, then you can access the logs from the yarn's web ui. View job history and time spent in various stages of the job: @michael deguzis, yarn typically stores history of all the application in either mapreduce history server (only for mapreduce. If the ui. Yarn Job History Server.