Spark Increase Stack Size . When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The following should do the trick. The driver and the executor. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. I'm running python script on spark cluster using jupyter. I found in the documentation. Let’s dive into each of these components and. I want to change driver default stack size. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Spark cache and persist are optimization.
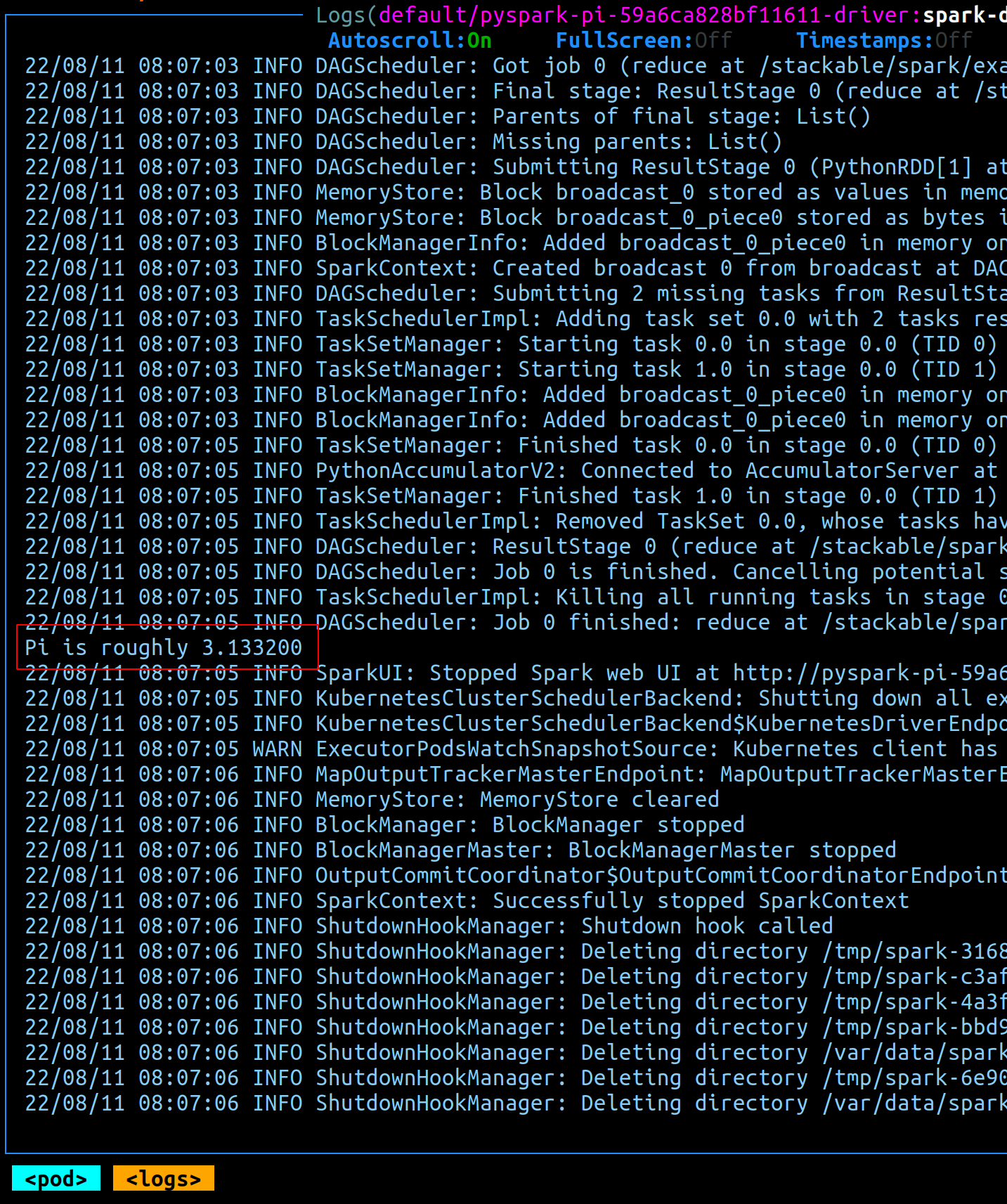
from docs.stackable.tech
When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. I'm running python script on spark cluster using jupyter. I want to change driver default stack size. Let’s dive into each of these components and. Spark cache and persist are optimization. When spark runs out of memory, it can be attributed to two main components: Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. I found in the documentation. The following should do the trick.
First steps sparkk8s Stackable Documentation
Spark Increase Stack Size The following should do the trick. When spark runs out of memory, it can be attributed to two main components: I'm running python script on spark cluster using jupyter. Spark cache and persist are optimization. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. The driver and the executor. I want to change driver default stack size. I found in the documentation. Let’s dive into each of these components and. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. The following should do the trick.
From www.wiseautotools.com
Measuring a spark plug to determine repair insert size Help with Spark Increase Stack Size I found in the documentation. I'm running python script on spark cluster using jupyter. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. The driver and the executor. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The following should do the trick.. Spark Increase Stack Size.
From www.automotiverider.com
What Size is a Spark Plug Socket, Spanner Or Wrench? » AutomotiveRider Spark Increase Stack Size Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. I found in the documentation. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. The following should do the trick. I'm running python script on spark cluster using jupyter. I want. Spark Increase Stack Size.
From axleaddict.com
How to Change Your Spark Plugs! AxleAddict Spark Increase Stack Size I'm running python script on spark cluster using jupyter. When spark runs out of memory, it can be attributed to two main components: I found in the documentation. The following should do the trick. I want to change driver default stack size. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Let’s dive. Spark Increase Stack Size.
From repairfixkneewponnabobil.z4.web.core.windows.net
What Size Are Spark Plug Threads Spark Increase Stack Size Let’s dive into each of these components and. I want to change driver default stack size. The following should do the trick. I found in the documentation. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The driver and the executor. Spark persisting/caching is one of the best techniques to. Spark Increase Stack Size.
From blog.dataiku.com
Big Data for Data Padawans Episode 2 What's the Deal With Spark? Spark Increase Stack Size When spark runs out of memory, it can be attributed to two main components: I'm running python script on spark cluster using jupyter. I found in the documentation. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. The following should do the trick. Let’s dive into each of these components and. The driver. Spark Increase Stack Size.
From www.theengineeringknowledge.com
What Size Socket for Spark Plug Needed? 2023 Complete Guide Spark Increase Stack Size I found in the documentation. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split. Spark Increase Stack Size.
From yardandgardenguru.com
Spark Plug Sockets Sizes Spark Increase Stack Size The driver and the executor. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. I'm running python script on spark cluster using jupyter. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. I want to change driver. Spark Increase Stack Size.
From ar.inspiredpencil.com
Spark Plug Gap Size Chart Spark Increase Stack Size The following should do the trick. The driver and the executor. I found in the documentation. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Spark cache and persist are optimization. I want to change driver default stack size. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type. Spark Increase Stack Size.
From www.thermofisher.com
OES Fast Inclusion Characterization during Steel Production Spark Increase Stack Size The following should do the trick. Let’s dive into each of these components and. Spark cache and persist are optimization. I'm running python script on spark cluster using jupyter. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark persisting/caching is one of the best techniques to. Spark Increase Stack Size.
From stackable.tech
The Stackable sparkonk8s operator Stackable Spark Increase Stack Size I found in the documentation. I'm running python script on spark cluster using jupyter. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Spark cache and persist are optimization. I want to change driver default stack size. Configures the default timestamp type of spark sql, including sql ddl, cast clause,. Spark Increase Stack Size.
From dlab.epfl.ch
What I learned from processing big data with Spark Spark Increase Stack Size I want to change driver default stack size. When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. I found in the documentation. I'm running python script on spark cluster using jupyter. Spark persisting/caching is one of. Spark Increase Stack Size.
From www.oreilly.com
4. InMemory Computing with Spark Data Analytics with Hadoop [Book] Spark Increase Stack Size The driver and the executor. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Spark cache and persist are optimization. The following should do the trick. Spark persisting/caching. Spark Increase Stack Size.
From garagesee.com
Spark Plug Sizes Socket Guide Spark Increase Stack Size Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark cache and persist are optimization. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. When spark runs out of memory, it can be attributed to two main components: The following. Spark Increase Stack Size.
From www.toolhustle.com
Use This Spark Plug Size Chart when changing your spark plugs! ToolHustle Spark Increase Stack Size The driver and the executor. Let’s dive into each of these components and. When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type. Spark Increase Stack Size.
From garagesee.com
Spark Plug Sizes Socket Guide Spark Increase Stack Size When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark cache and persist are. Spark Increase Stack Size.
From ar.inspiredpencil.com
Spark Plug Gap Size Chart Spark Increase Stack Size I want to change driver default stack size. I'm running python script on spark cluster using jupyter. The following should do the trick. When spark runs out of memory, it can be attributed to two main components: Let’s dive into each of these components and. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal. Spark Increase Stack Size.
From garagesee.com
Spark Plug Sizes Socket Guide Spark Increase Stack Size The driver and the executor. I want to change driver default stack size. I'm running python script on spark cluster using jupyter. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. When spark runs out of memory, it can be attributed to two main components: When true. Spark Increase Stack Size.
From schematiclistkoenig.z19.web.core.windows.net
Spark Plug Size Chart Spark Increase Stack Size I found in the documentation. When spark runs out of memory, it can be attributed to two main components: Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. The following should do the trick. The driver and the executor. Let’s dive into each of these components and. When true and spark.sql.adaptive.enabled is true,. Spark Increase Stack Size.
From exowbfaut.blob.core.windows.net
What Are Spark Plug Sizes at James Wilkerson blog Spark Increase Stack Size When spark runs out of memory, it can be attributed to two main components: The driver and the executor. I want to change driver default stack size. I'm running python script on spark cluster using jupyter. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The following should do the. Spark Increase Stack Size.
From www.motortech.de
DENSO® Spark Plugs motortech Spark Increase Stack Size I'm running python script on spark cluster using jupyter. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The following should do the trick. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. I found in the documentation. Configures the default timestamp type. Spark Increase Stack Size.
From docs.stackable.tech
First steps sparkk8s Stackable Documentation Spark Increase Stack Size I want to change driver default stack size. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Let’s dive into each of these components and. I found in the documentation. Spark cache and persist are optimization. When spark runs out of memory, it can be attributed to. Spark Increase Stack Size.
From ar.inspiredpencil.com
Spark Plug Gap Size Chart Spark Increase Stack Size When spark runs out of memory, it can be attributed to two main components: The driver and the executor. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. The following should do the trick. Let’s dive into each of these components and. I found in the documentation. I want to. Spark Increase Stack Size.
From stackable.tech
The Stackable sparkonk8s operator Stackable Spark Increase Stack Size I'm running python script on spark cluster using jupyter. I found in the documentation. When spark runs out of memory, it can be attributed to two main components: Spark cache and persist are optimization. I want to change driver default stack size. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them. Spark Increase Stack Size.
From ar.inspiredpencil.com
Spark Plug Gap Size Chart Spark Increase Stack Size I found in the documentation. When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark persisting/caching is one of the best techniques to improve the performance of the. Spark Increase Stack Size.
From yorktudder.blogspot.com
What Size Spark Plug Socket Do I Need York Tudder Spark Increase Stack Size Let’s dive into each of these components and. I want to change driver default stack size. I found in the documentation. The driver and the executor. I'm running python script on spark cluster using jupyter. The following should do the trick. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. When true and. Spark Increase Stack Size.
From ar.inspiredpencil.com
Spark Plug Gap Size Chart Spark Increase Stack Size I found in the documentation. The driver and the executor. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. I want to change driver default stack size. The following should do the trick. When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true,. Spark Increase Stack Size.
From yardandgardenguru.com
Spark Plug Sockets Sizes Spark Increase Stack Size Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. I want to change driver default stack size. Spark cache and persist are optimization. I found in the documentation. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. When true and. Spark Increase Stack Size.
From www.reddit.com
Cab arrived today to finish the spark stack. r/PositiveGridSpark Spark Increase Stack Size When spark runs out of memory, it can be attributed to two main components: When true and spark.sql.adaptive.enabled is true, spark will optimize the skewed shuffle partitions in rebalancepartitions and split them to. I'm running python script on spark cluster using jupyter. The driver and the executor. Let’s dive into each of these components and. Configures the default timestamp type. Spark Increase Stack Size.
From schematiclistkoenig.z19.web.core.windows.net
Spark Plug Size Chart Spark Increase Stack Size I want to change driver default stack size. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Spark cache and persist are optimization. I'm running python script on spark cluster using jupyter. When spark runs out of memory, it can be attributed to two main components: The driver and the executor. When true. Spark Increase Stack Size.
From eaglesgarage.com
A Complete Guide to Spark Plug Socket Size Eagles Garage Spark Increase Stack Size The following should do the trick. Let’s dive into each of these components and. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. Spark cache and persist are optimization. I'm running python script on spark cluster using jupyter. The driver and the executor. When true and spark.sql.adaptive.enabled. Spark Increase Stack Size.
From garagesee.com
Spark Plug Sizes Socket Guide Spark Increase Stack Size Spark cache and persist are optimization. The following should do the trick. I want to change driver default stack size. I found in the documentation. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. I'm running python script on spark cluster using jupyter. Let’s dive into each. Spark Increase Stack Size.
From greenbushfarmcom.blogspot.com
Spark Plug Sizes Chart Spark Increase Stack Size Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. I found in the documentation. The following should do the trick. Let’s dive into each of these components and. The driver and the executor. I want to change driver default stack size. When true and spark.sql.adaptive.enabled is true,. Spark Increase Stack Size.
From hxebqiheh.blob.core.windows.net
Generator Spark Plug Socket Size at Pedro Hood blog Spark Increase Stack Size I'm running python script on spark cluster using jupyter. I found in the documentation. The driver and the executor. The following should do the trick. I want to change driver default stack size. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. When spark runs out of. Spark Increase Stack Size.
From www.iteblog.com
Chapter 1. Introduction to Data Analysis with Spark 过往记忆 Spark Increase Stack Size I found in the documentation. When spark runs out of memory, it can be attributed to two main components: Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. Configures the default timestamp type of spark sql, including sql ddl, cast clause, type literal and the schema inference of data sources. When true and. Spark Increase Stack Size.
From autosbible.com
The Ultimate Guide to Choosing the Right Socket Size for Spark Plugs Spark Increase Stack Size The driver and the executor. I found in the documentation. Let’s dive into each of these components and. I want to change driver default stack size. The following should do the trick. Spark persisting/caching is one of the best techniques to improve the performance of the spark workloads. I'm running python script on spark cluster using jupyter. Configures the default. Spark Increase Stack Size.