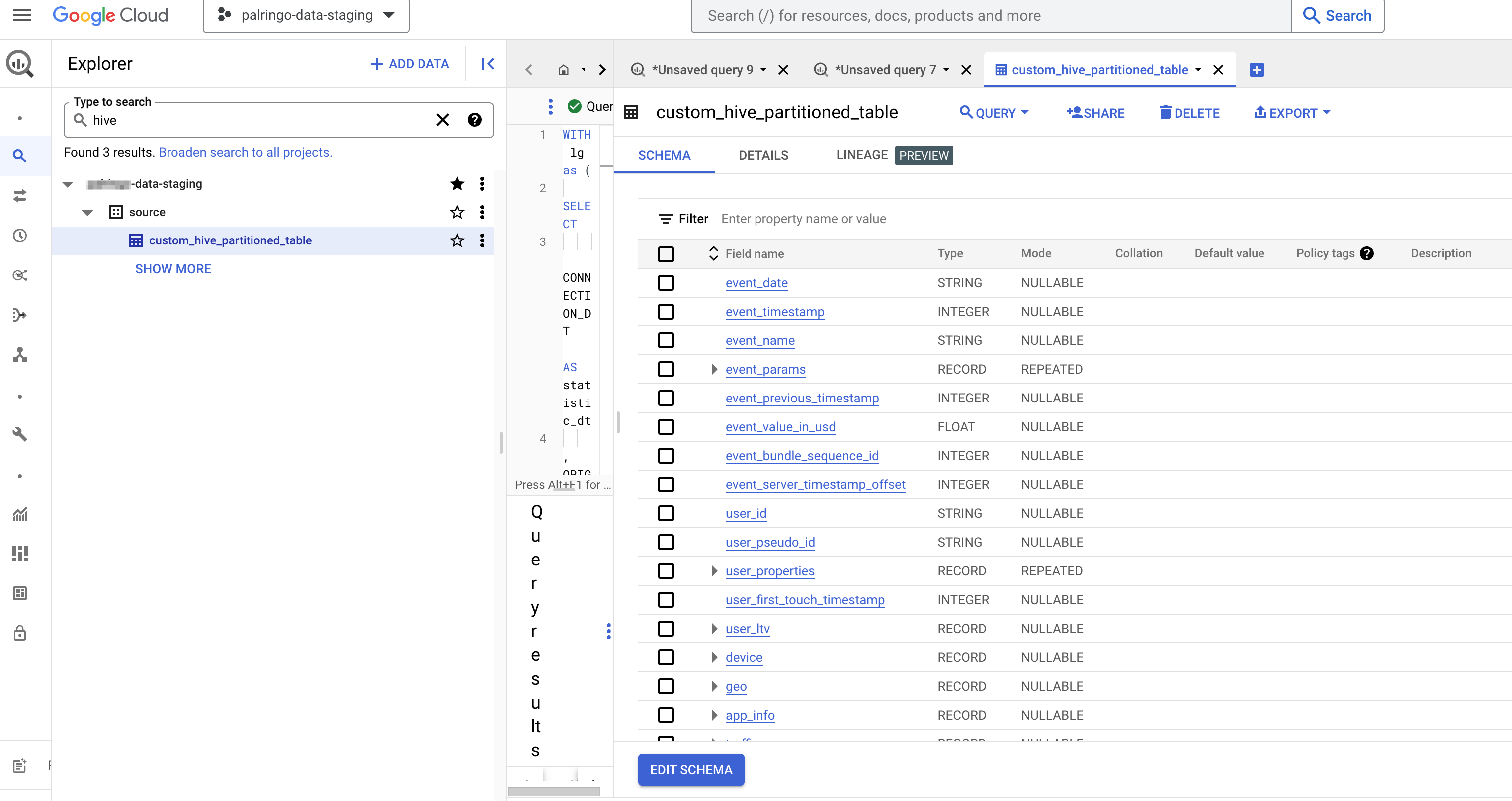
Hive Partition Pyspark . In this article is an introduction to partitioned hive table and pyspark. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. If hive dependencies can be found on the classpath, spark will load them automatically. Note that these hive dependencies must also. A hive table could be a logical representation of. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. If specified, the output is laid out on the file system similar to hive’s partitioning. These are really important things that data engineers should know While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. In this article, we will learn how to read a hive partitioned table using pyspark. Partitions the output by the given columns on the file system. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. Reading hive partitioned table using pyspark.
from mydataschool.com
In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. A hive table could be a logical representation of. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. If hive dependencies can be found on the classpath, spark will load them automatically. In this article, we will learn how to read a hive partitioned table using pyspark. In this article is an introduction to partitioned hive table and pyspark. If specified, the output is laid out on the file system similar to hive’s partitioning. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. Partitions the output by the given columns on the file system.
Hive Partitioning Layout
Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. If specified, the output is laid out on the file system similar to hive’s partitioning. Note that these hive dependencies must also. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. If hive dependencies can be found on the classpath, spark will load them automatically. Reading hive partitioned table using pyspark. These are really important things that data engineers should know Partitions the output by the given columns on the file system. In this article is an introduction to partitioned hive table and pyspark. In this article, we will learn how to read a hive partitioned table using pyspark. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. A hive table could be a logical representation of.
From www.projectpro.io
How to create dynamic partition in hive? Projectpro Hive Partition Pyspark In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. These are really important things that data engineers should know By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. Reading hive partitioned table using. Hive Partition Pyspark.
From www.youtube.com
Video5Spark Hive Partition Basic & Incremental Load YouTube Hive Partition Pyspark These are really important things that data engineers should know Reading hive partitioned table using pyspark. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. In this article, we will learn how to read a hive partitioned table using pyspark.. Hive Partition Pyspark.
From www.youtube.com
Hive Partitioning and Bucketing YouTube Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. In this article is an introduction to partitioned hive table and pyspark. Partitions the output by the given columns on the file system. In this article, we will learn how to read. Hive Partition Pyspark.
From www.simplilearn.com
Advanced Hive Concepts and Data File Partitioning Tutorial Simplilearn Hive Partition Pyspark In this article, we will learn how to read a hive partitioned table using pyspark. If hive dependencies can be found on the classpath, spark will load them automatically. Note that these hive dependencies must also. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based. Hive Partition Pyspark.
From blog.csdn.net
Hive分区(partition)详解_hive partitionCSDN博客 Hive Partition Pyspark These are really important things that data engineers should know By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. If hive dependencies can be found on the classpath, spark will load them automatically. In this article, we will learn how. Hive Partition Pyspark.
From blog.csdn.net
python取出hive_python环境下使用pyspark读取hive表CSDN博客 Hive Partition Pyspark These are really important things that data engineers should know A hive table could be a logical representation of. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. Note that these hive dependencies must also. Partitions the output by the given. Hive Partition Pyspark.
From www.youtube.com
Partition Management in Hive An Overview of MSCK Repair YouTube Hive Partition Pyspark A hive table could be a logical representation of. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. If specified, the output is laid out on the file system similar to hive’s partitioning. In conclusion, saving a pyspark dataframe to a hive table. Hive Partition Pyspark.
From issamhijazi.com
Hive, Partitions and Oracle Data Integrator ISSAM HIJAZI Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. These are really important things that data engineers should know By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. In this article, we will learn how. Hive Partition Pyspark.
From sparkbyexamples.com
Hive Partitioning vs Bucketing with Examples? Spark By {Examples} Hive Partition Pyspark The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. If hive dependencies can be found on the classpath, spark will load them automatically. In this article is an introduction to partitioned hive table and pyspark. Partitions the output by the given columns on. Hive Partition Pyspark.
From sparkbyexamples.com
How to Update or Drop a Hive Partition? Spark By {Examples} Hive Partition Pyspark If specified, the output is laid out on the file system similar to hive’s partitioning. Note that these hive dependencies must also. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. By utilizing pyspark’s dataframe api and sql capabilities, users can. Hive Partition Pyspark.
From sparkbyexamples.com
PySpark Save DataFrame to Hive Table Spark By {Examples} Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. In this article, we will learn how to read a hive partitioned table using pyspark. A hive table could be a logical representation of. In conclusion, saving a pyspark dataframe to a. Hive Partition Pyspark.
From mydataschool.com
Hive Partitioning Layout Hive Partition Pyspark The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. By utilizing pyspark’s dataframe api and. Hive Partition Pyspark.
From sparkbyexamples.com
Hive Load Partitioned Table with Examples Spark By {Examples} Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. These are really important things that data engineers should know A hive table could be a logical representation of. The above code works fine, but i have so much data for each. Hive Partition Pyspark.
From blog.csdn.net
pyspark环境搭建,连接hive_pyspark 怎么跟hive交互的CSDN博客 Hive Partition Pyspark In this article, we will learn how to read a hive partitioned table using pyspark. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. In this article is an introduction to partitioned hive table and pyspark. Partitions the output by the given columns on the file system. If hive dependencies can be found. Hive Partition Pyspark.
From blog.csdn.net
Hive动态分区(Dynamic Partition)导致的内存问题_hive.optimize.sort.dynamic.partition Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. In this article, we will learn how to read a hive partitioned table using pyspark. Reading hive partitioned table using pyspark. Note that these hive dependencies must also. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive. Hive Partition Pyspark.
From templates.udlvirtual.edu.pe
Pyspark Map Partition Example Printable Templates Hive Partition Pyspark By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. If hive dependencies can be found on the classpath, spark will load them automatically. Note that these hive dependencies must also. In conclusion, saving a pyspark dataframe to a hive table. Hive Partition Pyspark.
From blog.csdn.net
Pyspark+Hive环境搭建与配置_pyspark离线安装CSDN博客 Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. These are really important things that data engineers should know Reading hive partitioned table using pyspark. In this article is an introduction to partitioned hive table and pyspark. Partitions the output by the given columns on the file system. While you are create data lake out. Hive Partition Pyspark.
From sparkbyexamples.com
Hive Create Partition Table Explained Spark By {Examples} Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. Reading hive partitioned table using pyspark. In this article is an introduction to partitioned hive table and pyspark. If hive dependencies can be found on the classpath, spark will load them automatically.. Hive Partition Pyspark.
From sparkbyexamples.com
Hive Partitions Explained with Examples Spark By {Examples} Hive Partition Pyspark If specified, the output is laid out on the file system similar to hive’s partitioning. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. In this article is an introduction to partitioned hive table and pyspark. A hive table could be a logical representation of. By utilizing pyspark’s dataframe api and sql capabilities,. Hive Partition Pyspark.
From sqlandhadoop.com
Hive Partitions Everything you must know Hive Partition Pyspark In this article is an introduction to partitioned hive table and pyspark. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. Note that these hive dependencies must also. Partitions the output by the given columns on the file system. If specified,. Hive Partition Pyspark.
From davy.ai
How to reduce file size of PySpark output to that of Hive? Hive Partition Pyspark Partitions the output by the given columns on the file system. If specified, the output is laid out on the file system similar to hive’s partitioning. Reading hive partitioned table using pyspark. These are really important things that data engineers should know By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive. Hive Partition Pyspark.
From mydataschool.com
Hive Partitioning Layout Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. A hive table could be a logical representation of. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table. Hive Partition Pyspark.
From medium.com
Partitioning & Bucketing in Hive. Partition & Bucket in Hive by Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. These are really important things that data engineers should know The above code works fine, but i have so much data for each day that i want to dynamic partition. Hive Partition Pyspark.
From github.com
GitHub sparkexamples/pysparkhiveexample Hive Partition Pyspark Reading hive partitioned table using pyspark. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. In this article is an introduction to partitioned hive table and pyspark. Note that these hive dependencies must also. The above code works fine, but i. Hive Partition Pyspark.
From www.youtube.com
How to load Hive table into PySpark? YouTube Hive Partition Pyspark If specified, the output is laid out on the file system similar to hive’s partitioning. In this article, we will learn how to read a hive partitioned table using pyspark. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. In. Hive Partition Pyspark.
From www.cnblogs.com
大数据pyspark远程连接hive 脑袋凉凉 博客园 Hive Partition Pyspark Reading hive partitioned table using pyspark. In this article is an introduction to partitioned hive table and pyspark. In this article, we will learn how to read a hive partitioned table using pyspark. These are really important things that data engineers should know If hive dependencies can be found on the classpath, spark will load them automatically. If specified, the. Hive Partition Pyspark.
From sparkbyexamples.com
Hive Bucketing Explained with Examples Spark By {Examples} Hive Partition Pyspark In this article is an introduction to partitioned hive table and pyspark. A hive table could be a logical representation of. By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. In conclusion, saving a pyspark dataframe to a hive table. Hive Partition Pyspark.
From devvoon.github.io
[HIVE] HIVE Partition, Bucket, View, Index devvoon blog Hive Partition Pyspark Note that these hive dependencies must also. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby(). Hive Partition Pyspark.
From www.youtube.com
PySpark Tutorial11 Creating DataFrame from a Hive table Writing Hive Partition Pyspark In this article is an introduction to partitioned hive table and pyspark. Note that these hive dependencies must also. A hive table could be a logical representation of. Partitions the output by the given columns on the file system. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data. Hive Partition Pyspark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Hive Partition Pyspark Note that these hive dependencies must also. If hive dependencies can be found on the classpath, spark will load them automatically. Reading hive partitioned table using pyspark. A hive table could be a logical representation of. If specified, the output is laid out on the file system similar to hive’s partitioning. In conclusion, saving a pyspark dataframe to a hive. Hive Partition Pyspark.
From issamhijazi.com
Hive, Partitions and Oracle Data Integrator ISSAM HIJAZI Hive Partition Pyspark In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. If specified, the output is laid out on the file system similar to hive’s partitioning. In this article, we will learn how to read a hive partitioned table using pyspark. Partitions the output by the given columns on the file system. In this article. Hive Partition Pyspark.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Hive Partition Pyspark If hive dependencies can be found on the classpath, spark will load them automatically. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. In this article is an introduction to partitioned hive table and pyspark. While you are create data lake out of azure, hdfs or aws you need to understand how to. Hive Partition Pyspark.
From sparkbyexamples.com
PySpark SQL Read Hive Table Spark By {Examples} Hive Partition Pyspark Reading hive partitioned table using pyspark. In conclusion, saving a pyspark dataframe to a hive table persist data within the hive cluster. In this article is an introduction to partitioned hive table and pyspark. While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark. Hive Partition Pyspark.
From www.youtube.com
Store pyspark Dataframe to hive table YouTube Hive Partition Pyspark While you are create data lake out of azure, hdfs or aws you need to understand how to partition your data at rest (file system/disk), pyspark partitionby() and. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. If specified, the output is laid. Hive Partition Pyspark.
From www.youtube.com
Create A Data Pipeline on Messaging Using PySpark Hive Introduction Hive Partition Pyspark By utilizing pyspark’s dataframe api and sql capabilities, users can easily create, manipulate, and save data to hive tables, enabling a wide range of data analytics and processing tasks. The above code works fine, but i have so much data for each day that i want to dynamic partition the hive table based on the. Partitions the output by the. Hive Partition Pyspark.