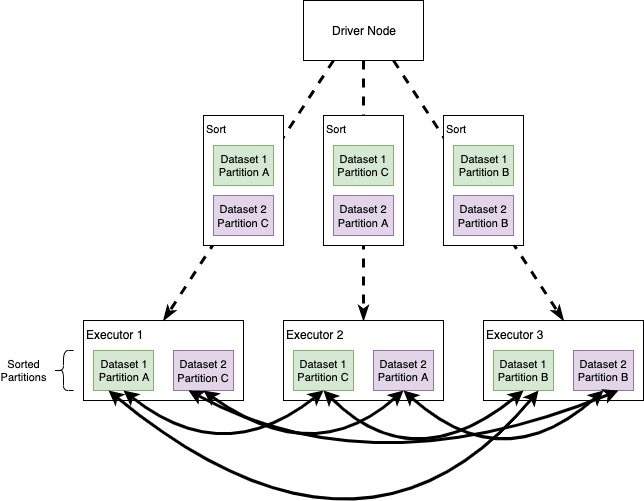
Get Partitions In Spark Sql . The simple code below looks easy and seems to solve the problem. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. We use spark's ui to monitor task times and shuffle read/write times. How does spark partitioning work? Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. This will give you insights into whether you need to repartition your data. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name
from itnext.io
The simple code below looks easy and seems to solve the problem. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name We use spark's ui to monitor task times and shuffle read/write times. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. This will give you insights into whether you need to repartition your data. How does spark partitioning work?
Apache Spark Internals Tips and Optimizations by Javier Ramos ITNEXT
Get Partitions In Spark Sql If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name We use spark's ui to monitor task times and shuffle read/write times. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. This will give you insights into whether you need to repartition your data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. How does spark partitioning work? The simple code below looks easy and seems to solve the problem. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range.
From dataninjago.com
Spark SQL Query Engine Deep Dive (20) Adaptive Query Execution (Part Get Partitions In Spark Sql This will give you insights into whether you need to repartition your data. How does spark partitioning work? Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. The simple code below looks easy and seems to. Get Partitions In Spark Sql.
From cabinet.matttroy.net
Table Partitioning In Sql Server Matttroy Get Partitions In Spark Sql How does spark partitioning work? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. The simple code below looks easy and seems to solve. Get Partitions In Spark Sql.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 Get Partitions In Spark Sql If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. How does spark partitioning work? Spark distributes data across nodes based on various partitioning methods such as hash. Get Partitions In Spark Sql.
From www.youtube.com
what is Spark SQL YouTube Get Partitions In Spark Sql Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Data partitioning is critical. Get Partitions In Spark Sql.
From realbitt.blogspot.com
SQL Server Table Partitioning technique Rembox Get Partitions In Spark Sql How does spark partitioning work? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name The simple code below looks easy and seems to solve the problem. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of. Get Partitions In Spark Sql.
From medium.com
Spark SQL Utilizando SQL em uma Grande Massa de Dados by Ingo Get Partitions In Spark Sql How does spark partitioning work? Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. We use spark's ui to monitor task times and shuffle read/write times. If you have save your data. Get Partitions In Spark Sql.
From www.sqlshack.com
SQL Partition overview Get Partitions In Spark Sql Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. How does spark partitioning work? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column. Get Partitions In Spark Sql.
From ceqeecsp.blob.core.windows.net
Sql Server Partition By List at Jerry Ruiz blog Get Partitions In Spark Sql Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name How does spark partitioning work? This will give you insights into whether you need to repartition your data. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. Data partitioning. Get Partitions In Spark Sql.
From toien.github.io
Spark 分区数量 Kwritin Get Partitions In Spark Sql This will give you insights into whether you need to repartition your data. We use spark's ui to monitor task times and shuffle read/write times. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. The simple code below looks easy and seems to solve the problem. Data partitioning is. Get Partitions In Spark Sql.
From www.waitingforcode.com
Spark SQL checkpoints on articles about Apache Get Partitions In Spark Sql The simple code below looks easy and seems to solve the problem. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Spark distributes data across nodes based. Get Partitions In Spark Sql.
From www.edwinmsarmiento.com
PartitionLevel Online Index Operations in SQL Server 2014 and its Get Partitions In Spark Sql If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. How does spark partitioning work? The simple code below looks easy and seems to solve the problem. Data partitioning. Get Partitions In Spark Sql.
From www.upscpdf.in
spark.sql.shuffle.partitions UPSCPDF Get Partitions In Spark Sql The simple code below looks easy and seems to solve the problem. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Data partitioning is critical to data processing. Get Partitions In Spark Sql.
From www.essentialsql.com
How to Use SQL Variables in Queries Essential SQL Get Partitions In Spark Sql Data partitioning is critical to data processing performance especially for large volume of data processing in spark. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. How does spark partitioning work? Spark distributes data across nodes based on various partitioning methods such as hash. Get Partitions In Spark Sql.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Get Partitions In Spark Sql Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the. Get Partitions In Spark Sql.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Get Partitions In Spark Sql Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. We use spark's ui to monitor task times and shuffle read/write times. This will give you insights into whether you need to repartition your data. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use. Get Partitions In Spark Sql.
From awesomehome.co
Table Partitioning In Sql Server 2017 Awesome Home Get Partitions In Spark Sql The simple code below looks easy and seems to solve the problem. We use spark's ui to monitor task times and shuffle read/write times. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. This will give you insights into whether you need to repartition. Get Partitions In Spark Sql.
From medium.com
Spark Data Structures. In last post , I discussed about power… by Get Partitions In Spark Sql If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. We use spark's ui to monitor task times and shuffle read/write times. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Data partitioning is. Get Partitions In Spark Sql.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Get Partitions In Spark Sql Data partitioning is critical to data processing performance especially for large volume of data processing in spark. The simple code below looks easy and seems to solve the problem. This will give you insights into whether you need to repartition your data. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to. Get Partitions In Spark Sql.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Get Partitions In Spark Sql How does spark partitioning work? If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd. Get Partitions In Spark Sql.
From mybios.me
Create Hive Table From Spark Dataframe Python Bios Pics Get Partitions In Spark Sql How does spark partitioning work? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. The simple code below looks easy and seems to solve the problem. Spark distributes data. Get Partitions In Spark Sql.
From exocpydfk.blob.core.windows.net
What Is Shuffle Partitions In Spark at Joe Warren blog Get Partitions In Spark Sql This will give you insights into whether you need to repartition your data. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. How does spark partitioning work? The simple code below looks easy and seems to solve the problem. Pyspark.sql.dataframe.repartition() method is used to. Get Partitions In Spark Sql.
From itnext.io
Apache Spark Internals Tips and Optimizations by Javier Ramos ITNEXT Get Partitions In Spark Sql Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. If you have save your data as. Get Partitions In Spark Sql.
From janzednicek.cz
SQL OVER() with PARTITION BY Definition, Example wint ROWS BETWEEN Get Partitions In Spark Sql We use spark's ui to monitor task times and shuffle read/write times. How does spark partitioning work? Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. The simple code below looks easy and seems to solve the problem. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions,. Get Partitions In Spark Sql.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Get Partitions In Spark Sql The simple code below looks easy and seems to solve the problem. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. We use spark's ui to monitor task times and shuffle read/write times. How does spark partitioning work? This will give you insights into. Get Partitions In Spark Sql.
From www.yugabyte.com
Distributed SQL Sharding and Partitioning YugabyteDB Get Partitions In Spark Sql Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. How does spark partitioning work? This will give you insights into whether you need to repartition your data. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Spark distributes data across nodes. Get Partitions In Spark Sql.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Get Partitions In Spark Sql How does spark partitioning work? Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column. Get Partitions In Spark Sql.
From www.youtube.com
Spark SQL with SQL Part 1 (using Scala) YouTube Get Partitions In Spark Sql This will give you insights into whether you need to repartition your data. Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. We use spark's ui to monitor task times and shuffle read/write times. If you have save your data as a delta table, you can get the partitions. Get Partitions In Spark Sql.
From sparkbyexamples.com
Spark SQL Explained with Examples Spark By {Examples} Get Partitions In Spark Sql How does spark partitioning work? Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Data partitioning is critical to data processing performance especially for large volume of data processing in spark. The simple code below looks easy and seems to solve the problem. Spark rdd provides getnumpartitions, partitions.length and. Get Partitions In Spark Sql.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Get Partitions In Spark Sql This will give you insights into whether you need to repartition your data. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. How does spark partitioning work?. Get Partitions In Spark Sql.
From towardsdatascience.com
How to Use Partitions and Clusters in BigQuery Using SQL by Romain Get Partitions In Spark Sql We use spark's ui to monitor task times and shuffle read/write times. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size. Get Partitions In Spark Sql.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Get Partitions In Spark Sql Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. This will give you insights into whether you need to repartition your data. If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. How does. Get Partitions In Spark Sql.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Get Partitions In Spark Sql Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Data partitioning is critical to data processing performance especially for large volume of data processing. Get Partitions In Spark Sql.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Get Partitions In Spark Sql Data partitioning is critical to data processing performance especially for large volume of data processing in spark. The simple code below looks easy and seems to solve the problem. How does spark partitioning work? Spark rdd provides getnumpartitions, partitions.length and partitions.size that returns the length/size of current rdd partitions, in order to use this. This will give you insights into. Get Partitions In Spark Sql.
From www.scaler.com
SQL PARTITION BY Clause Scaler Topics Get Partitions In Spark Sql Spark distributes data across nodes based on various partitioning methods such as hash partitioning or range. Data partitioning is critical to data processing performance especially for large volume of data processing in spark. We use spark's ui to monitor task times and shuffle read/write times. If you have save your data as a delta table, you can get the partitions. Get Partitions In Spark Sql.
From blog.quest.com
SQL PARTITION BY Clause When and How to Use It Get Partitions In Spark Sql How does spark partitioning work? If you have save your data as a delta table, you can get the partitions information by providing the table name instead of the delta. Pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or by single column name This will give you insights into whether you need to. Get Partitions In Spark Sql.