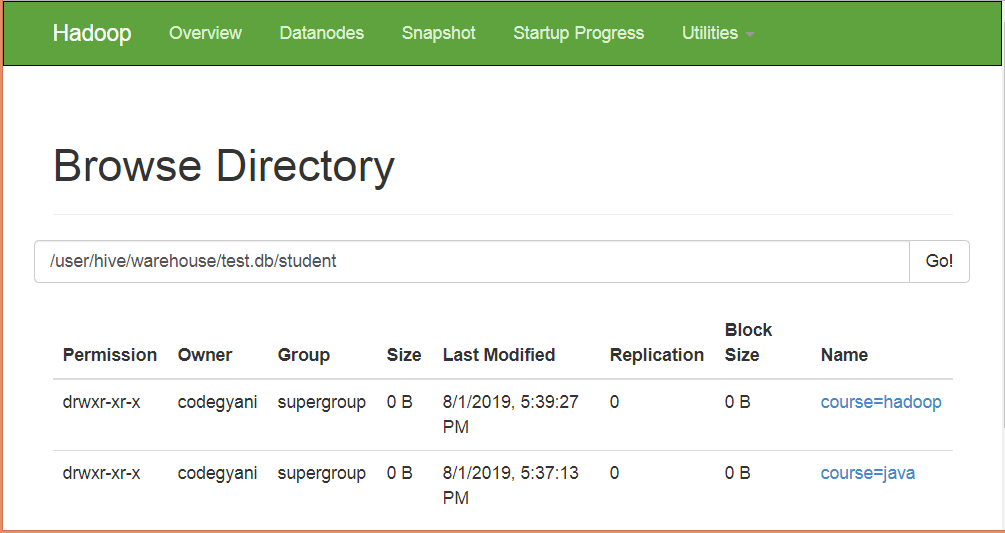
Hive Partition Subdirectory . Partitioning in hive is conceptually very simple: In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. I want to add all data of. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. I have data organized in directories in a particular format (shown below) and want to add these to hive table. In hive, tables are created as a directory on hdfs. Here is an example where there are 3 days. One logical table (partition) for each distinct value. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; You create the table, then add each partition manually via an alter table command. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive.
from www.javatpoint.com
Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. Partitioning in hive is conceptually very simple: In hive, tables are created as a directory on hdfs. One logical table (partition) for each distinct value. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I want to add all data of. You create the table, then add each partition manually via an alter table command. Here is an example where there are 3 days. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding.
Partitioning in Hive javatpoint
Hive Partition Subdirectory Hive partition is a way to organize large tables into smaller logical tables based on values of columns; Hive partition is a way to organize large tables into smaller logical tables based on values of columns; In hive, tables are created as a directory on hdfs. One logical table (partition) for each distinct value. Partitioning in hive is conceptually very simple: In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. You create the table, then add each partition manually via an alter table command. I have data organized in directories in a particular format (shown below) and want to add these to hive table. I want to add all data of. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. Here is an example where there are 3 days. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive.
From phxtechsol.com
NextGen AV and The Challenge of Optimizing Big Data at Scale Phoenix Hive Partition Subdirectory Here is an example where there are 3 days. I want to add all data of. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. One logical table (partition) for each distinct value. Hive doesn't know about those directories until you tell it about them, so. Hive Partition Subdirectory.
From github.com
Hive partition parsing error · Issue 19420 · trinodb/trino · GitHub Hive Partition Subdirectory Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. I have data organized in directories in a particular format (shown below) and want to add these to hive table.. Hive Partition Subdirectory.
From www.javatpoint.com
Partitioning in Hive javatpoint Hive Partition Subdirectory We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. Here is an example where there are 3 days. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. You create the table, then add each partition manually via. Hive Partition Subdirectory.
From www.youtube.com
mv directory to a device partition's subdirectory, e.g. mv directory Hive Partition Subdirectory Here is an example where there are 3 days. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. I have data organized in directories in a particular format (shown. Hive Partition Subdirectory.
From hxeiirfxh.blob.core.windows.net
Difference Between Partitions And Buckets In Hive at Joyce Gonzalez blog Hive Partition Subdirectory I have data organized in directories in a particular format (shown below) and want to add these to hive table. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. Here is an example where there are 3 days. One logical table (partition) for each distinct value. Partitioning. Hive Partition Subdirectory.
From slideplayer.com
Rekha Singhal, Amol Khanapurkar, TCS Mumbai. ppt download Hive Partition Subdirectory You create the table, then add each partition manually via an alter table command. Partitioning in hive is conceptually very simple: In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. We define one or more columns to partition the data on, and then for each unique. Hive Partition Subdirectory.
From twitter.com
Ismael Ghalimi on Twitter "Here are the files on S3, using Hive Hive Partition Subdirectory I have data organized in directories in a particular format (shown below) and want to add these to hive table. In hive, tables are created as a directory on hdfs. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. Hive is a data warehouse infrastructure built. Hive Partition Subdirectory.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Hive Partition Subdirectory Here is an example where there are 3 days. You create the table, then add each partition manually via an alter table command. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Hive doesn't know about those directories until you tell it about them, so there's. Hive Partition Subdirectory.
From analyticshut.com
Inserting Data to Partitions in Hive Table Analyticshut Hive Partition Subdirectory I have data organized in directories in a particular format (shown below) and want to add these to hive table. Here is an example where there are 3 days. You create the table, then add each partition manually via an alter table command. In hive, tables are created as a directory on hdfs. In hadoop hive, data is stored as. Hive Partition Subdirectory.
From www.mytechmint.com
Hive Partitions & Buckets myTechMint Hive Partition Subdirectory I have data organized in directories in a particular format (shown below) and want to add these to hive table. Here is an example where there are 3 days. In hive, tables are created as a directory on hdfs. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without. Hive Partition Subdirectory.
From medium.com
Hive data organization — Partitioning & Clustering by Amit Singh Hive Partition Subdirectory One logical table (partition) for each distinct value. In hive, tables are created as a directory on hdfs. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I. Hive Partition Subdirectory.
From www.outoff.com.co
Partitioning in Hive Hadoop Online Tutorials guest Hive Partition Subdirectory Partitioning in hive is conceptually very simple: Here is an example where there are 3 days. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. I have data organized in directories in a particular format (shown below) and want to add these to hive table. We define. Hive Partition Subdirectory.
From sparkbyexamples.com
Hive Load Partitioned Table with Examples Spark By {Examples} Hive Partition Subdirectory Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; We define. Hive Partition Subdirectory.
From www.youtube.com
HIVE DYNAMIC PARTITION RECAP 10 YouTube Hive Partition Subdirectory Here is an example where there are 3 days. I have data organized in directories in a particular format (shown below) and want to add these to hive table. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I want to add all data of. Hive is a data warehouse infrastructure. Hive Partition Subdirectory.
From www.youtube.com
Inserting Data into Partitions in Hive Tables YouTube Hive Partition Subdirectory We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. You create the table, then add each partition manually via an alter table command. One logical table (partition) for each distinct value. Partitioning in hive is conceptually very simple: In hive, tables are created as a directory. Hive Partition Subdirectory.
From www.projectpro.io
How to create dynamic partition in hive? Projectpro Hive Partition Subdirectory Partitioning in hive is conceptually very simple: Hive partition is a way to organize large tables into smaller logical tables based on values of columns; We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. In hadoop hive, data is stored as files on hdfs, whenever you. Hive Partition Subdirectory.
From sparkbyexamples.com
How to Update or Drop a Hive Partition? Spark By {Examples} Hive Partition Subdirectory In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Here is an example where there are 3 days. I have data organized in directories in a particular format (shown below) and want to add these to hive table. In hive, tables are created as a directory. Hive Partition Subdirectory.
From blog.csdn.net
大数据案例之HDFSHIVE_data.dp.dphdfspath.gethivetablehdfs(dphdfspath.javCSDN博客 Hive Partition Subdirectory In hive, tables are created as a directory on hdfs. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; Here is an example where there are 3 days. I have data organized in. Hive Partition Subdirectory.
From github.com
[Bug] [hive source] read hive partition text error · Issue 4465 Hive Partition Subdirectory You create the table, then add each partition manually via an alter table command. I want to add all data of. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. I have data organized in directories in a particular format (shown below) and want to add. Hive Partition Subdirectory.
From sparkbyexamples.com
Hive Create Partition Table Explained Spark By {Examples} Hive Partition Subdirectory We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. You create the table, then add each partition manually via an alter table command. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; Hive is a data warehouse. Hive Partition Subdirectory.
From sparkbyexamples.com
Hive Partitions Explained with Examples Spark By {Examples} Hive Partition Subdirectory In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. I have data organized in directories in a particular format (shown below) and want to. Hive Partition Subdirectory.
From www.linkedin.com
2.1 Hive Metastore Managed External Partition(static/Dynamic Hive Partition Subdirectory Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I have data organized in directories in a particular format (shown below) and want to add these to hive table. Here is an example where there are 3 days. In hive, tables are created as a directory on hdfs. Hive doesn't know. Hive Partition Subdirectory.
From www.youtube.com
HIVE PARTITION TABLE 7 YouTube Hive Partition Subdirectory Partitioning in hive is conceptually very simple: I want to add all data of. You create the table, then add each partition manually via an alter table command. I have data organized in directories in a particular format (shown below) and want to add these to hive table. Hive doesn't know about those directories until you tell it about them,. Hive Partition Subdirectory.
From devvoon.github.io
[HIVE] HIVE Partition, Bucket, View, Index devvoon blog Hive Partition Subdirectory Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. One logical table (partition) for each distinct value. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Partitioning in hive is conceptually very simple:. Hive Partition Subdirectory.
From sparkbyexamples.com
Hive Partitioning vs Bucketing with Examples? Spark By {Examples} Hive Partition Subdirectory In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. I want to add all data of. You create the table, then add each partition manually via an alter table command. Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying,. Hive Partition Subdirectory.
From www.youtube.com
Apache Hive 01 Partition an existing data set according to one or Hive Partition Subdirectory I want to add all data of. In hive, tables are created as a directory on hdfs. I have data organized in directories in a particular format (shown below) and want to add these to hive table. Hive doesn't know about those directories until you tell it about them, so there's no way to access the partitions without adding. You. Hive Partition Subdirectory.
From www.youtube.com
Adding Partitions to Tables in Hive YouTube Hive Partition Subdirectory One logical table (partition) for each distinct value. Partitioning in hive is conceptually very simple: Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I have data organized in directories in a particular format (shown below) and want to add these to hive table. In hive, tables are created as a. Hive Partition Subdirectory.
From slideplayer.com
Section 2 Installing SES ppt download Hive Partition Subdirectory Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. One logical table (partition) for each distinct value. Here is an example where there are 3 days. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; We define one or more columns to. Hive Partition Subdirectory.
From hxelhllgy.blob.core.windows.net
Types Of Partitions In Hive at Jessica Schmidt blog Hive Partition Subdirectory You create the table, then add each partition manually via an alter table command. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive.. Hive Partition Subdirectory.
From blog.csdn.net
Hive(一) Hive概述、三种方式搭建和区别_hive安装的两种方式的区别CSDN博客 Hive Partition Subdirectory Partitioning in hive is conceptually very simple: Hive is a data warehouse infrastructure built on top of hadoop that provides data summarization, querying, and analysis. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Hive partition is a way to organize large tables into smaller logical. Hive Partition Subdirectory.
From www.sentinelone.com
NextGen AV and The Challenge of Optimizing Big Data at Scale SentinelOne Hive Partition Subdirectory In hive, tables are created as a directory on hdfs. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Hive is a data warehouse infrastructure built on top. Hive Partition Subdirectory.
From www.youtube.com
11 Hive Static and Dynamic Table Partition HQL Index & View Hive Partition Subdirectory In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive, it creates sub directories within main. Partitioning in hive is conceptually very simple: Here is an example where there are 3 days. One logical table (partition) for each distinct value. Hive is a data warehouse infrastructure built on top of hadoop that provides. Hive Partition Subdirectory.
From data-flair.training
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Hive Partition Subdirectory We define one or more columns to partition the data on, and then for each unique combination of values in those columns, hive. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; In hive, tables are created as a directory on hdfs. I want to add all data of. One logical. Hive Partition Subdirectory.
From hxelhllgy.blob.core.windows.net
Types Of Partitions In Hive at Jessica Schmidt blog Hive Partition Subdirectory Partitioning in hive is conceptually very simple: In hive, tables are created as a directory on hdfs. You create the table, then add each partition manually via an alter table command. I want to add all data of. Hive partition is a way to organize large tables into smaller logical tables based on values of columns; In hadoop hive, data. Hive Partition Subdirectory.
From www.dexlabanalytics.com
The Pros and Cons of HIVE Partitioning Hive Partition Subdirectory Hive partition is a way to organize large tables into smaller logical tables based on values of columns; I want to add all data of. In hive, tables are created as a directory on hdfs. One logical table (partition) for each distinct value. In hadoop hive, data is stored as files on hdfs, whenever you partition the table in hive,. Hive Partition Subdirectory.