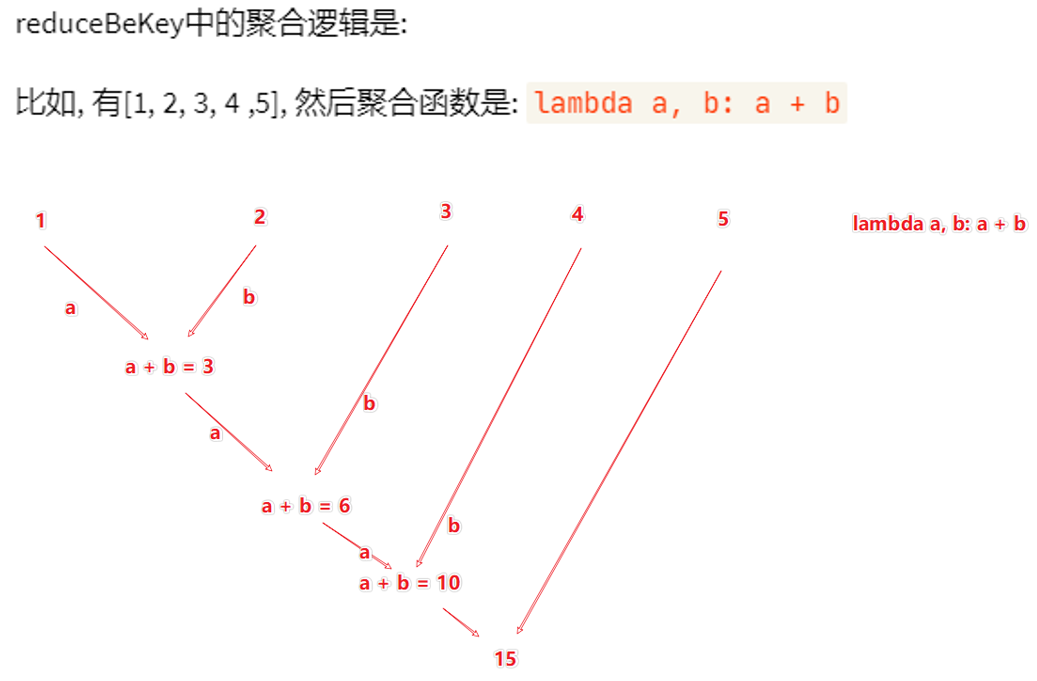
Pyspark Rdd Reduce Sum . Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Learn to use reduce() with java, python examples I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Reduce the values of these rdd's by. Simply use sum, you just need to get the data into a list.
from blog.csdn.net
Learn to use reduce() with java, python examples This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Reduce the values of these rdd's by. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Simply use sum, you just need to get the data into a list. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd.
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群
Pyspark Rdd Reduce Sum Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Reduce the values of these rdd's by. Learn to use reduce() with java, python examples Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Simply use sum, you just need to get the data into a list.
From sparkbyexamples.com
PySpark sum() Columns Example Spark By {Examples} Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Learn to use reduce() with java, python examples Sc.parallelize([('id', [1, 2, 3]),. Pyspark Rdd Reduce Sum.
From zhuanlan.zhihu.com
PySpark RDD有几种类型算子? 知乎 Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Simply use sum, you just need to get the data into a list. Learn to use reduce() with java, python examples Callable [[t,. Pyspark Rdd Reduce Sum.
From www.projectpro.io
PySpark RDD Cheat Sheet A Comprehensive Guide Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Reduce the values of these rdd's by. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PySpark中RDD的数据输出详解_pythonrdd打印内容CSDN博客 Pyspark Rdd Reduce Sum I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Reduce the values of these rdd's by. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with. Pyspark Rdd Reduce Sum.
From zhuanlan.zhihu.com
PySpark实战 17:使用 Python 扩展 PYSPARK:RDD 和用户定义函数 (1) 知乎 Pyspark Rdd Reduce Sum I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Reduce the values of these rdd's by. Callable [[t, t], t]) → t [source]. Pyspark Rdd Reduce Sum.
From www.youtube.com
Practical RDD action reduce in PySpark using Jupyter PySpark 101 Part 25 DM DataMaking Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Learn to use. Pyspark Rdd Reduce Sum.
From sparkbyexamples.com
PySpark Create RDD with Examples Spark by {Examples} Pyspark Rdd Reduce Sum Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Simply use sum, you just need to get the. Pyspark Rdd Reduce Sum.
From www.javatpoint.com
PySpark RDD javatpoint Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Reduce the values of these rdd's by. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how. Pyspark Rdd Reduce Sum.
From www.youtube.com
Pyspark RDD Operations Actions in Pyspark RDD Fold vs Reduce Glom() Pyspark tutorials Pyspark Rdd Reduce Sum Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Simply use sum, you just need to get the data into a list. Learn to use reduce() with java, python examples Spark rdd reduce () aggregate action function is used to calculate min, max, and. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PySpark中RDD的数据输出详解_pythonrdd打印内容CSDN博客 Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Learn to use reduce() with java, python examples I am looking to do the following with the deepest list of. Pyspark Rdd Reduce Sum.
From blog.csdn.net
sparkRDD与sparkSqlDF转换_pyspark shell rdd转化为带表头的dfCSDN博客 Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Spark rdd reduce () aggregate action function is. Pyspark Rdd Reduce Sum.
From www.youtube.com
How to use distinct RDD transformation in PySpark PySpark 101 Part 11 DM DataMaking Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Learn to use reduce() with java, python examples I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset). Pyspark Rdd Reduce Sum.
From blog.csdn.net
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群 Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Learn to use reduce() with java, python examples I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial,. Pyspark Rdd Reduce Sum.
From blog.csdn.net
pyspark RDD reduce、reduceByKey、reduceByKeyLocally用法CSDN博客 Pyspark Rdd Reduce Sum Learn to use reduce() with java, python examples Reduce the values of these rdd's by. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github. Pyspark Rdd Reduce Sum.
From blog.csdn.net
【Python】PySpark 数据输入 ① ( RDD 简介 RDD 中的数据存储与计算 Python 容器数据转 RDD 对象 文件文件转 RDD 对象 )_pyspark Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Reduce the values of these rdd's by. Simply use sum, you just need to get the data into a list. I am looking to do the following with the deepest list of (key,val). Pyspark Rdd Reduce Sum.
From data-flair.training
PySpark RDD With Operations and Commands DataFlair Pyspark Rdd Reduce Sum This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Learn to use reduce() with java, python examples Spark rdd reduce () aggregate action function is used to calculate min, max,. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PySpark数据分析基础核心数据集RDD原理以及操作一文详解(一)_rdd中rCSDN博客 Pyspark Rdd Reduce Sum Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Reduce the values of these rdd's by. Learn to use reduce() with java, python examples Spark rdd reduce () aggregate action function is used to calculate min, max, and total. Pyspark Rdd Reduce Sum.
From www.analyticsvidhya.com
Create RDD in Apache Spark using Pyspark Analytics Vidhya Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Reduce the values of these rdd's by. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Callable [[t, t], t]) → t [source] ¶ reduces the. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群 Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Learn to use reduce() with java, python examples Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. I am looking to. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群 Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Learn to. Pyspark Rdd Reduce Sum.
From zhuanlan.zhihu.com
PySpark Transformation/Action 算子详细介绍 知乎 Pyspark Rdd Reduce Sum Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. This pyspark rdd. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群 Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. Learn to use reduce() with java, python examples Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i. Pyspark Rdd Reduce Sum.
From medium.com
Pyspark RDD. Resilient Distributed Datasets (RDDs)… by Muttineni Sai Rohith CodeX Medium Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Learn to use reduce() with java, python examples Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t,. Pyspark Rdd Reduce Sum.
From www.educba.com
PySpark RDD Operations PIP Install PySpark Features Pyspark Rdd Reduce Sum Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples. Simply use sum, you just need to get the. Pyspark Rdd Reduce Sum.
From sparkbyexamples.com
PySpark RDD Tutorial Learn with Examples Spark by {Examples} Pyspark Rdd Reduce Sum I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Learn to use reduce() with java, python examples. Pyspark Rdd Reduce Sum.
From zhuanlan.zhihu.com
PySpark Transformation/Action 算子详细介绍 知乎 Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it,. Pyspark Rdd Reduce Sum.
From www.youtube.com
Pyspark Tutorial 5, RDD Actions,reduce,countbykey,countbyvalue,fold,variance,stats, Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Reduce the values of these rdd's by. Simply use sum, you just need to get the data. Pyspark Rdd Reduce Sum.
From github.com
GitHub Wizc1998/BigDataManagementwithPysparkRDD This project is to use Pyspark RDD Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and. Pyspark Rdd Reduce Sum.
From blog.csdn.net
pyspark RDD reduce、reduceByKey、reduceByKeyLocally用法CSDN博客 Pyspark Rdd Reduce Sum I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Simply use sum, you just need to get the data into a list. Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. This pyspark rdd tutorial. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PySpark中RDD的数据输出详解_pythonrdd打印内容CSDN博客 Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Reduce the values of these rdd's by. I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: Callable. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PythonPySpark案例实战:Spark介绍、库安装、编程模型、RDD对象、flat Map、reduce By Key、filter、distinct、sort By方法、分布式集群 Pyspark Rdd Reduce Sum Learn to use reduce() with java, python examples Simply use sum, you just need to get the data into a list. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how to create an rdd and use it, along with github examples.. Pyspark Rdd Reduce Sum.
From subscription.packtpub.com
Python to RDD communications Learning PySpark Pyspark Rdd Reduce Sum Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. I am looking to do the following with the deepest list of. Pyspark Rdd Reduce Sum.
From blog.csdn.net
PySpark reduce reduceByKey用法_pyspark reducebykeyCSDN博客 Pyspark Rdd Reduce Sum Simply use sum, you just need to get the data into a list. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. Reduce the values of these rdd's by. This pyspark rdd tutorial will help you understand what is rdd (resilient distributed dataset) , its advantages, and how. Pyspark Rdd Reduce Sum.
From ittutorial.org
PySpark RDD Example IT Tutorial Pyspark Rdd Reduce Sum Reduce the values of these rdd's by. Sc.parallelize([('id', [1, 2, 3]), ('id2', [3, 4, 5])]) \. Simply use sum, you just need to get the data into a list. Learn to use reduce() with java, python examples I am looking to do the following with the deepest list of (key,val) rdd's.reducebykey(lambda a, b: This pyspark rdd tutorial will help you. Pyspark Rdd Reduce Sum.
From data-flair.training
PySpark RDD With Operations and Commands DataFlair Pyspark Rdd Reduce Sum Learn to use reduce() with java, python examples Spark rdd reduce () aggregate action function is used to calculate min, max, and total of elements in a dataset, in this tutorial, i will explain rdd. Callable [[t, t], t]) → t [source] ¶ reduces the elements of this rdd using the specified commutative and associative binary. I am looking to. Pyspark Rdd Reduce Sum.