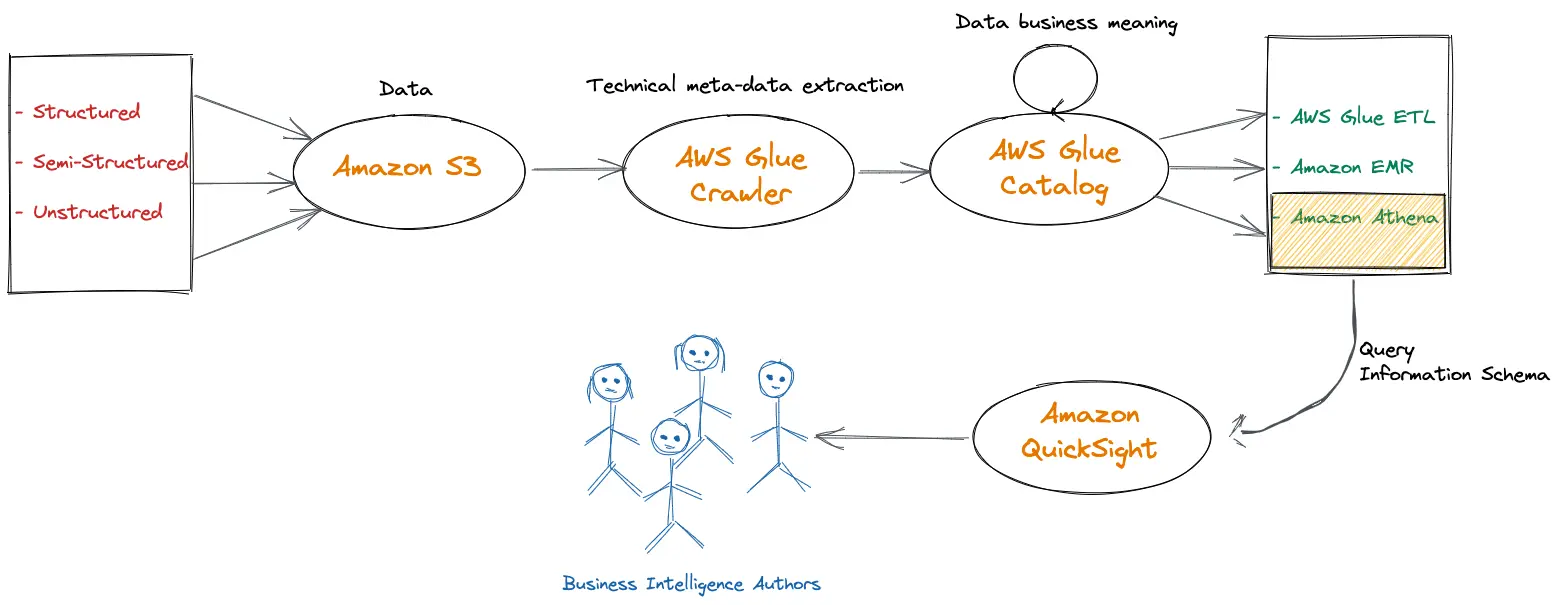
Difference Between Glue Job And Crawler . A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. An aws glue workflow consists of 3 main components: Tools that scan various data stores, extract metadata, and create table definitions. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A crawler can connect to. In this article, i will explain how to create a glue workflow with some various options. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata.
from atlan.com
A crawler can connect to. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. In this article, i will explain how to create a glue workflow with some various options. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. An aws glue workflow consists of 3 main components: A resource that contains the properties needed. Tools that scan various data stores, extract metadata, and create table definitions.
Glue Data Catalog — Architecture, Components, and Crawlers
Difference Between Glue Job And Crawler An aws glue workflow consists of 3 main components: A crawler can connect to. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. Tools that scan various data stores, extract metadata, and create table definitions. In this article, i will explain how to create a glue workflow with some various options. A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. An aws glue workflow consists of 3 main components:
From aws.amazon.com
AWS Glue Job 리소스 사용량에 대한 알람 및 리포팅 자동화 AWS 기술 블로그 Difference Between Glue Job And Crawler A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. You can populate the data catalog using a crawler, which automatically scans your. Difference Between Glue Job And Crawler.
From www.youtube.com
Manage AWS Glue Jobs with Step Functions YouTube Difference Between Glue Job And Crawler A resource that contains the properties needed. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. In this article, i will explain how to create a glue workflow with some various options. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving. Difference Between Glue Job And Crawler.
From www.bigrentz.com
Bulldozer vs. Excavator Which One Do I Need? BigRentz Difference Between Glue Job And Crawler Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A crawler can connect to. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. Tools that scan various data stores, extract metadata, and create table definitions. An aws glue. Difference Between Glue Job And Crawler.
From www.hava.io
What is Amazon AWS Glue? Difference Between Glue Job And Crawler Tools that scan various data stores, extract metadata, and create table definitions. An aws glue workflow consists of 3 main components: A resource that contains the properties needed. In this article, i will explain how to create a glue workflow with some various options. In summary, aws glue is a powerful and flexible etl service that simplifies the process of. Difference Between Glue Job And Crawler.
From www.facebook.com
We’ve tested difference glue techniques and found the best one We’ve Difference Between Glue Job And Crawler You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. Tools that scan various data stores, extract metadata, and create table definitions. A resource that contains the properties needed. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. In. Difference Between Glue Job And Crawler.
From aws.amazon.com
AWS Glue DataBrew AWS Big Data Blog Difference Between Glue Job And Crawler In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. An aws glue workflow consists of 3 main components: A resource that contains the properties needed. In this article, i will explain. Difference Between Glue Job And Crawler.
From www.youtube.com
Crawl different datastores in a single Glue Crawler job YouTube Difference Between Glue Job And Crawler In this article, i will explain how to create a glue workflow with some various options. A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler,. Difference Between Glue Job And Crawler.
From towardsdatascience.com
A Complete Guide On Serverless Data Lake Using AWS Glue, Athena and Difference Between Glue Job And Crawler An aws glue workflow consists of 3 main components: Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. Tools that scan various data stores, extract metadata, and. Difference Between Glue Job And Crawler.
From www.neenopal.com
What is Glue Crawler and how to use it Difference Between Glue Job And Crawler In this article, i will explain how to create a glue workflow with some various options. An aws glue workflow consists of 3 main components: A crawler can connect to. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. Aws glue is made up of several individual. Difference Between Glue Job And Crawler.
From aws.amazon.com
How SumUp made digital analytics more accessible using AWS Glue AWS Difference Between Glue Job And Crawler You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. A crawler can connect to. A resource that contains the properties needed. In this article, i will explain how to create a glue workflow with some various options. Tools that scan various data stores, extract metadata, and create table definitions. In summary,. Difference Between Glue Job And Crawler.
From www.bigrentz.com
11 Types of Cranes Commonly Used in Construction BigRentz Difference Between Glue Job And Crawler A resource that contains the properties needed. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. An aws glue workflow consists of 3 main components: A crawler can connect. Difference Between Glue Job And Crawler.
From medium.com
Automating ETL jobs on AWS using Glue, Lambda, EventsBridge and Athena Difference Between Glue Job And Crawler In this article, i will explain how to create a glue workflow with some various options. An aws glue workflow consists of 3 main components: You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. A resource that contains the properties needed. Tools that scan various data stores, extract metadata, and create. Difference Between Glue Job And Crawler.
From www.abccranehire.com.au
Major Differences Between Crawler Cranes and Mobile Cranes. Difference Between Glue Job And Crawler A crawler can connect to. Tools that scan various data stores, extract metadata, and create table definitions. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. An. Difference Between Glue Job And Crawler.
From www.youtube.com
AWS GLUE CRAWLER TUTORIAL with DEMO Learn AWS GLUE YouTube Difference Between Glue Job And Crawler A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In other words it persists information about physical location of data, its schema, format and. Difference Between Glue Job And Crawler.
From www.neenopal.com
How to set up and run a glue job Difference Between Glue Job And Crawler Tools that scan various data stores, extract metadata, and create table definitions. An aws glue workflow consists of 3 main components: Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A resource that contains the properties needed. In other words it persists information about physical location of data, its. Difference Between Glue Job And Crawler.
From hxefhazft.blob.core.windows.net
Job Bookmarks In Aws Glue at Donna Richard blog Difference Between Glue Job And Crawler In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. A crawler can connect to. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. Tools that scan various data stores, extract metadata, and create table definitions. An aws glue. Difference Between Glue Job And Crawler.
From towardsaws.com
AWS Glue Initial Steps. What is AWS Glue by Ruchi A Towards AWS Difference Between Glue Job And Crawler In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. An aws glue workflow consists of 3 main components: In this article, i will explain how to create a glue workflow with some various options. You can populate the data catalog using a crawler, which automatically scans your data sources. Difference Between Glue Job And Crawler.
From docs.aws.amazon.com
Data Catalog and crawlers in AWS Glue AWS Glue Difference Between Glue Job And Crawler A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. A crawler can connect to. An aws glue workflow consists of 3 main components: In other words it persists information about physical location of data, its schema, format and partitions which makes it. Difference Between Glue Job And Crawler.
From www.familyhandyman.com
A DIYer's Guide Glue and Adhesives The Family Handyman Difference Between Glue Job And Crawler An aws glue workflow consists of 3 main components: In this article, i will explain how to create a glue workflow with some various options. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. Tools that scan various data stores, extract metadata, and create table definitions. A resource that contains the. Difference Between Glue Job And Crawler.
From docs.aws.amazon.com
AWS Glue concepts AWS Glue Difference Between Glue Job And Crawler Tools that scan various data stores, extract metadata, and create table definitions. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. A resource that contains the properties needed. A crawler can connect to. An aws glue workflow consists of 3 main components: In summary, aws glue is a powerful and flexible. Difference Between Glue Job And Crawler.
From noise.getoto.net
Automate ETL jobs between Amazon RDS for SQL Server and Azure Managed Difference Between Glue Job And Crawler In this article, i will explain how to create a glue workflow with some various options. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A resource that contains the properties. Difference Between Glue Job And Crawler.
From www.youtube.com
AWS Glue Data Catalog and Crawlers AWS Glue tutorial p3 YouTube Difference Between Glue Job And Crawler A resource that contains the properties needed. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. In this article, i will explain how to create a glue. Difference Between Glue Job And Crawler.
From programmaticponderings.com
AthenaGlueArchitecturev2 Programmatic Ponderings Difference Between Glue Job And Crawler Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. In this article, i will explain how to create a glue workflow with some various options. A resource that contains. Difference Between Glue Job And Crawler.
From github.com
GitHub moritzkoerber/covid19dataengineeringpipeline A Covid19 Difference Between Glue Job And Crawler You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A crawler can connect to. An aws glue workflow consists of 3 main components: In other words it persists information about physical. Difference Between Glue Job And Crawler.
From noise.getoto.net
Automate ETL jobs between Amazon RDS for SQL Server and Azure Managed Difference Between Glue Job And Crawler A resource that contains the properties needed. An aws glue workflow consists of 3 main components: In this article, i will explain how to create a glue workflow with some various options. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In summary, aws glue is a powerful and flexible etl. Difference Between Glue Job And Crawler.
From www.neenopal.com
How to set up and run a glue job Difference Between Glue Job And Crawler A resource that contains the properties needed. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. In this article, i will explain how to create a glue workflow with. Difference Between Glue Job And Crawler.
From www.youtube.com
Build and automate Serverless DataLake using an AWS Glue , Lambda Difference Between Glue Job And Crawler In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. An aws glue workflow consists of 3 main components: Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A resource that contains the properties needed. Tools that scan various. Difference Between Glue Job And Crawler.
From www.bosscrane.com
All Terrain Cranes Vs. Crawler Cranes 3 Differences Difference Between Glue Job And Crawler In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. An aws glue workflow consists of 3 main components: Tools that scan various data stores, extract metadata, and create table definitions. A crawler can connect to. A resource that contains the properties needed. You can populate the data. Difference Between Glue Job And Crawler.
From www.youtube.com
AWS Glue Ingest data from S3 to Redshift ETL with AWS Glue AWS Data Difference Between Glue Job And Crawler A resource that contains the properties needed. An aws glue workflow consists of 3 main components: Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. Tools that scan various data stores, extract metadata, and create table definitions. In summary, aws glue is a powerful and flexible etl service that. Difference Between Glue Job And Crawler.
From smathanshse.blogspot.com
HSE Insider TOWER, CRAWLER CRANE PICTORIAL CHECKLIST Difference Between Glue Job And Crawler Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. Tools that scan various data stores, extract metadata, and create table definitions. A crawler can connect to. In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. An. Difference Between Glue Job And Crawler.
From www.dremio.com
AWS Glue Integration Guide Wiki Difference Between Glue Job And Crawler In other words it persists information about physical location of data, its schema, format and partitions which makes it possible to query. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. A resource that contains the properties needed. An aws glue workflow consists of 3 main components: In this article, i. Difference Between Glue Job And Crawler.
From atlan.com
Glue Data Catalog — Architecture, Components, and Crawlers Difference Between Glue Job And Crawler A resource that contains the properties needed. Tools that scan various data stores, extract metadata, and create table definitions. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In other words. Difference Between Glue Job And Crawler.
From www.linkedin.com
The Difference between 3axis, 4axis, and 5axis Glue Dispensing Robot Difference Between Glue Job And Crawler Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. You can populate the data catalog using a crawler, which automatically scans your data sources and extracts metadata. In this article, i will explain how to create a glue workflow with some various options. In other words it persists information. Difference Between Glue Job And Crawler.
From exojwxuon.blob.core.windows.net
Glue Flooring To Concrete Slab at Fred Gordon blog Difference Between Glue Job And Crawler A crawler can connect to. An aws glue workflow consists of 3 main components: A resource that contains the properties needed. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming. Difference Between Glue Job And Crawler.
From aws.amazon.com
Design patterns Set up AWS Glue Crawlers using S3 event notifications Difference Between Glue Job And Crawler A resource that contains the properties needed. In summary, aws glue is a powerful and flexible etl service that simplifies the process of moving and transforming data. Aws glue is made up of several individual components, such as the glue data catalog, crawlers, scheduler, and so on. A crawler can connect to. You can populate the data catalog using a. Difference Between Glue Job And Crawler.