Partition Data On Hdfs . partition eliminates creating smaller tables, accessing, and managing them separately. the two main elements of hadoop are: It provides a commandline interface called fs shell that lets a user. The three common types of failures are namenode failures,. the primary objective of hdfs is to store data reliably even in the presence of failures. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. hdfs allows user data to be organized in the form of files and directories. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. In this article, we will.
from data-flair.training
It provides a commandline interface called fs shell that lets a user. the two main elements of hadoop are: partition eliminates creating smaller tables, accessing, and managing them separately. the primary objective of hdfs is to store data reliably even in the presence of failures. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. The three common types of failures are namenode failures,. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. hdfs allows user data to be organized in the form of files and directories. In this article, we will.
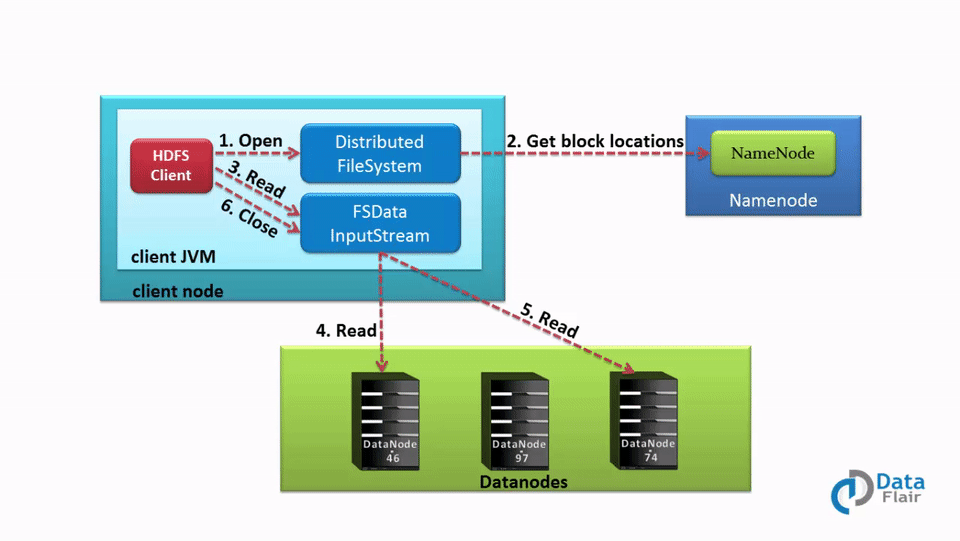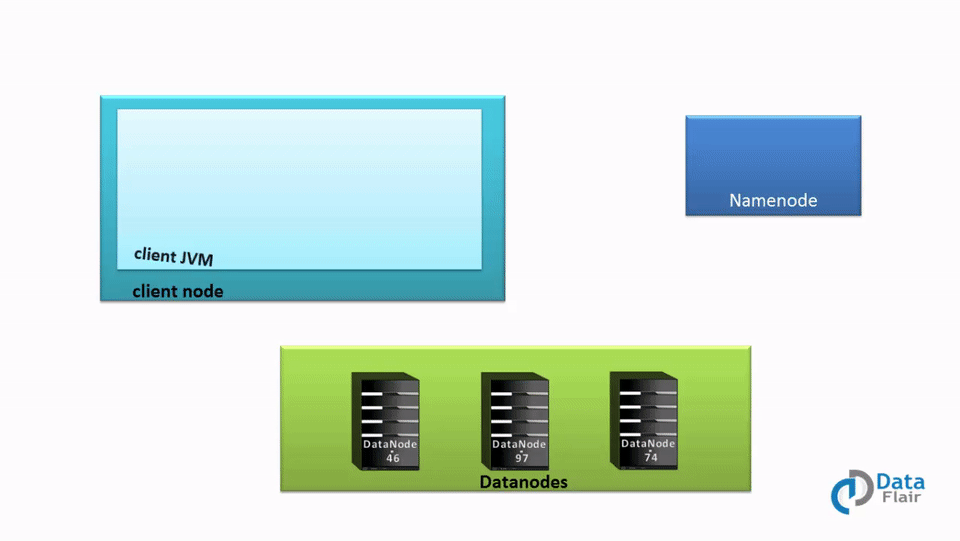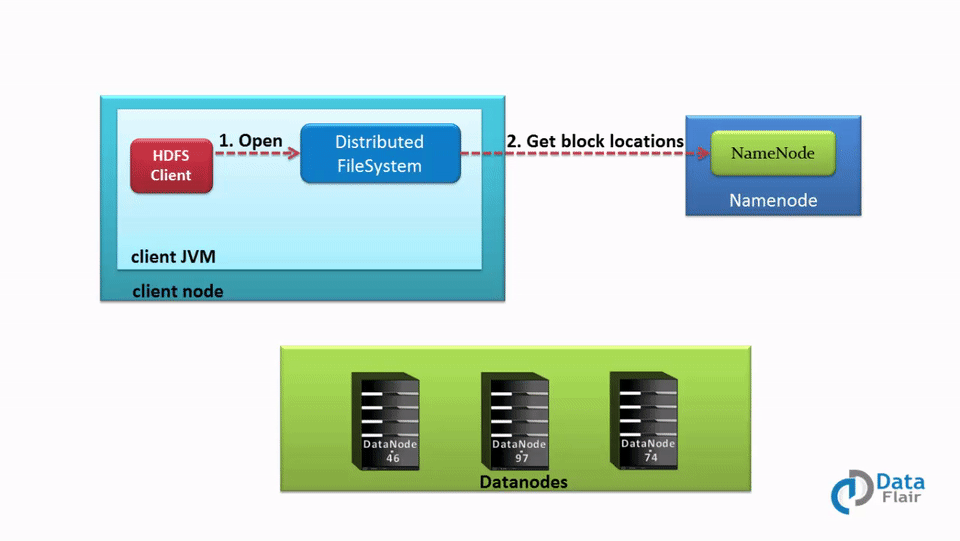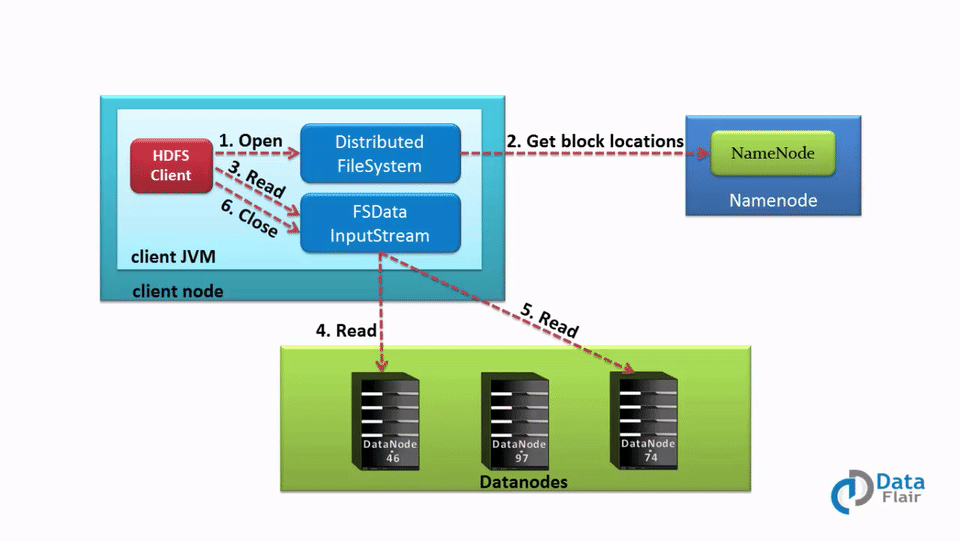
Data Read Operation in HDFS A Quick HDFS Guide DataFlair
Partition Data On Hdfs the primary objective of hdfs is to store data reliably even in the presence of failures. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the two main elements of hadoop are: The three common types of failures are namenode failures,. It provides a commandline interface called fs shell that lets a user. partition eliminates creating smaller tables, accessing, and managing them separately. hdfs allows user data to be organized in the form of files and directories. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. In this article, we will. the primary objective of hdfs is to store data reliably even in the presence of failures.
From www.interviewbit.com
HDFS Architecture Detailed Explanation InterviewBit Partition Data On Hdfs this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. the two main elements of hadoop are: partition eliminates creating smaller tables, accessing, and managing them separately. hdfs allows user data to be organized in the form of files and directories.. Partition Data On Hdfs.
From www.cockroachlabs.com
What is data partitioning, and how to do it right Partition Data On Hdfs the two main elements of hadoop are: In this article, we will. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. hdfs allows user data to be organized in the form of files and directories. partition eliminates creating smaller tables, accessing, and managing them. Partition Data On Hdfs.
From www.vrogue.co
What Is Hdfs Architecture Features Benefits And Examp vrogue.co Partition Data On Hdfs hdfs allows user data to be organized in the form of files and directories. the two main elements of hadoop are: In this article, we will. the primary objective of hdfs is to store data reliably even in the presence of failures. The three common types of failures are namenode failures,. to improve this situation, i. Partition Data On Hdfs.
From www.slidestalk.com
Hadoop Distributed File System (HDFS) YSmart merged patch HIVE Partition Data On Hdfs the two main elements of hadoop are: to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. hdfs allows user data to be organized in the form of files and directories. the primary objective of hdfs is to store data reliably even in the presence. Partition Data On Hdfs.
From www.gangofcoders.net
How does Spark partition(ing) work on files in HDFS? Gang of Coders Partition Data On Hdfs As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the two main elements of hadoop are: In this article, we will. the primary objective of hdfs is to store data reliably even in the presence of failures. It provides a commandline interface called fs shell that lets a user.. Partition Data On Hdfs.
From andr83.io
How to work with Hive tables with a lot of partitions from Spark Partition Data On Hdfs It provides a commandline interface called fs shell that lets a user. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. In this article, we will. the primary objective of hdfs is to store data reliably even in the presence of failures. partition eliminates creating smaller tables, accessing, and. Partition Data On Hdfs.
From www.alibabacloud.com
Migrate Hive tables and partitions to OSS or OSSHDFS by using Partition Data On Hdfs to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. partition eliminates creating smaller tables, accessing, and managing them separately. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. The. Partition Data On Hdfs.
From www.hdfstutorial.com
A Detailed Guide on HDFS Architecture HDFS Tutorial Partition Data On Hdfs It provides a commandline interface called fs shell that lets a user. the two main elements of hadoop are: partition eliminates creating smaller tables, accessing, and managing them separately. The three common types of failures are namenode failures,. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce. Partition Data On Hdfs.
From peterli.website
如何透過Greenplum查詢Hadoop HDFS上的資料 Peter 工程日誌 Partition Data On Hdfs to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. the primary objective of hdfs is to store data reliably even in the presence of failures. partition eliminates creating smaller tables, accessing, and managing them separately. It provides a commandline interface called fs shell that lets. Partition Data On Hdfs.
From www.vrogue.co
Mengenal Hadoop Hdfs Dan Mapreduce vrogue.co Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. The three common types of failures are namenode failures,. It provides a commandline interface called fs shell that lets a user. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the primary objective of hdfs is to store data. Partition Data On Hdfs.
From dxonegxqq.blob.core.windows.net
Snapshot Hdfs at Rochelle Dodson blog Partition Data On Hdfs the two main elements of hadoop are: It provides a commandline interface called fs shell that lets a user. the primary objective of hdfs is to store data reliably even in the presence of failures. The three common types of failures are namenode failures,. partition eliminates creating smaller tables, accessing, and managing them separately. As data is. Partition Data On Hdfs.
From sqlandhadoop.com
Hive Partitions Everything you must know SQL & Hadoop Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. hdfs allows user data to be organized in the form of files and directories. the two main elements of hadoop are: In this article, we will. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile. Partition Data On Hdfs.
From stacklima.com
HDFS Opération de lecture de données StackLima Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. The three common types of failures are namenode failures,. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the primary objective of hdfs is to store data reliably even in the presence of failures. In this article, we will.. Partition Data On Hdfs.
From www.simplilearn.com.cach3.com
Data File Partitioning and Advanced Concepts of Hive Partition Data On Hdfs to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. partition eliminates creating smaller tables, accessing, and managing them separately. The three common types of failures are namenode failures,.. Partition Data On Hdfs.
From blog.csdn.net
(hadoop学习-3)Total Order Partitioner_totalorderpartitionerCSDN博客 Partition Data On Hdfs this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. the primary objective of hdfs is to store data reliably even in the presence of failures. partition eliminates creating smaller tables, accessing, and managing them separately. to improve this situation, i. Partition Data On Hdfs.
From data-flair.training
Hadoop Partitioner Internals of MapReduce Partitioner DataFlair Partition Data On Hdfs The three common types of failures are namenode failures,. the primary objective of hdfs is to store data reliably even in the presence of failures. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. to improve this situation, i am thinking of partitioning the data based on the domain. Partition Data On Hdfs.
From www.tutorialandexample.com
HDFS Hadoop Modules Partition Data On Hdfs In this article, we will. It provides a commandline interface called fs shell that lets a user. The three common types of failures are namenode failures,. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. hdfs allows user data to be organized in the form of files and directories. . Partition Data On Hdfs.
From www.cloudduggu.com
Apache Hadoop HDFS Tutorial CloudDuggu Partition Data On Hdfs the two main elements of hadoop are: hdfs allows user data to be organized in the form of files and directories. the primary objective of hdfs is to store data reliably even in the presence of failures. partition eliminates creating smaller tables, accessing, and managing them separately. The three common types of failures are namenode failures,.. Partition Data On Hdfs.
From hangmortimer.medium.com
62 Big data technology (part 2) Hadoop architecture, HDFS, YARN, Map Partition Data On Hdfs In this article, we will. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the primary objective of hdfs is to store data reliably even in the presence of failures. The three common types of failures are namenode failures,. the two main elements of hadoop are: to improve. Partition Data On Hdfs.
From slideplayer.com
A Warehousing Solution Over a MapReduce Framework ppt download Partition Data On Hdfs the primary objective of hdfs is to store data reliably even in the presence of failures. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. the two main elements of hadoop are: this tutorial describes how to add partition field to the content of the flowfile, create dynamic. Partition Data On Hdfs.
From www.updatecg.xin
大数据案例之HDFSHIVE 我的学习记录 Partition Data On Hdfs to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. The three common types of failures are namenode failures,. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. It provides a commandline interface called fs shell that lets a. Partition Data On Hdfs.
From medium.com
HDFS Architecture. HDFS is an Open source component of the… by Hari Partition Data On Hdfs It provides a commandline interface called fs shell that lets a user. the two main elements of hadoop are: the primary objective of hdfs is to store data reliably even in the presence of failures. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. The three common types of. Partition Data On Hdfs.
From dzone.com
Building a LargeScale Distributed Storage System Based on Raft DZone Partition Data On Hdfs the primary objective of hdfs is to store data reliably even in the presence of failures. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. to improve this situation, i am thinking of partitioning the data based on the domain name. Partition Data On Hdfs.
From hadoop.apache.org
HDFS Architecture Guide Partition Data On Hdfs this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. the two main elements of hadoop are: partition eliminates creating. Partition Data On Hdfs.
From www.youtube.com
Hadoop Distributed Filesystem (HDFS) And Its Features YouTube Partition Data On Hdfs In this article, we will. It provides a commandline interface called fs shell that lets a user. The three common types of failures are namenode failures,. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. hdfs allows user data to be organized. Partition Data On Hdfs.
From www.simplilearn.com
Spark Parallel Processing Tutorial Simplilearn Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. The three common types of failures are namenode failures,. the two main elements of hadoop are: hdfs allows user data to. Partition Data On Hdfs.
From data-flair.training
Data Read Operation in HDFS A Quick HDFS Guide DataFlair Partition Data On Hdfs the primary objective of hdfs is to store data reliably even in the presence of failures. In this article, we will. The three common types of failures are namenode failures,. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. It provides a commandline interface called fs shell that lets a. Partition Data On Hdfs.
From blog.csdn.net
Hadoop系列之HDFS 架构(9)_存储元数据叫什么节点CSDN博客 Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. the two main elements of hadoop are: The three common types of failures are namenode failures,. hdfs allows user data to be organized in the form of files and directories. As data is loaded into the partitioned table, hive internally divides the records based on the partition. Partition Data On Hdfs.
From www.codersarts.com
Big Data, HDFS, Spark Project Help Partition Data On Hdfs hdfs allows user data to be organized in the form of files and directories. the two main elements of hadoop are: As data is loaded into the partitioned table, hive internally divides the records based on the partition key. In this article, we will. The three common types of failures are namenode failures,. this tutorial describes how. Partition Data On Hdfs.
From www.javatpoint.com
HDFS javatpoint Partition Data On Hdfs the two main elements of hadoop are: partition eliminates creating smaller tables, accessing, and managing them separately. the primary objective of hdfs is to store data reliably even in the presence of failures. It provides a commandline interface called fs shell that lets a user. In this article, we will. this tutorial describes how to add. Partition Data On Hdfs.
From www.glennklockwood.com
Conceptual Overview of MapReduce and Hadoop Partition Data On Hdfs hdfs allows user data to be organized in the form of files and directories. this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby. Partition Data On Hdfs.
From bradhedlund.com
Understanding Hadoop Clusters and the Network Partition Data On Hdfs this tutorial describes how to add partition field to the content of the flowfile, create dynamic partitions based on flowfile content and store data into. the primary objective of hdfs is to store data reliably even in the presence of failures. to improve this situation, i am thinking of partitioning the data based on the domain name. Partition Data On Hdfs.
From slideplayer.com
Big Data in Azure HDInsight ppt download Partition Data On Hdfs partition eliminates creating smaller tables, accessing, and managing them separately. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. to improve this situation, i am thinking of partitioning the data based on the domain name and thereby reduce my search. The three common types of failures are namenode failures,.. Partition Data On Hdfs.
From techvidvan.com
Apache Hadoop Architecture HDFS, YARN & MapReduce TechVidvan Partition Data On Hdfs hdfs allows user data to be organized in the form of files and directories. In this article, we will. partition eliminates creating smaller tables, accessing, and managing them separately. As data is loaded into the partitioned table, hive internally divides the records based on the partition key. to improve this situation, i am thinking of partitioning the. Partition Data On Hdfs.
From hudi.apache.org
File Layouts Apache Hudi Partition Data On Hdfs It provides a commandline interface called fs shell that lets a user. In this article, we will. hdfs allows user data to be organized in the form of files and directories. the primary objective of hdfs is to store data reliably even in the presence of failures. As data is loaded into the partitioned table, hive internally divides. Partition Data On Hdfs.