Number Of Partitions In Spark Dataframe . in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. Columnorname) → dataframe [source] ¶ returns a new. methods to get the current number of partitions of a dataframe. For a concrete example, consider the r5d.2xlarge instance in aws. returns a new :class:dataframe partitioned by the given partitioning expressions. Union [int, columnorname], * cols: one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task.
from techvidvan.com
For a concrete example, consider the r5d.2xlarge instance in aws. returns a new :class:dataframe partitioned by the given partitioning expressions. methods to get the current number of partitions of a dataframe. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. Union [int, columnorname], * cols: one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Columnorname) → dataframe [source] ¶ returns a new.
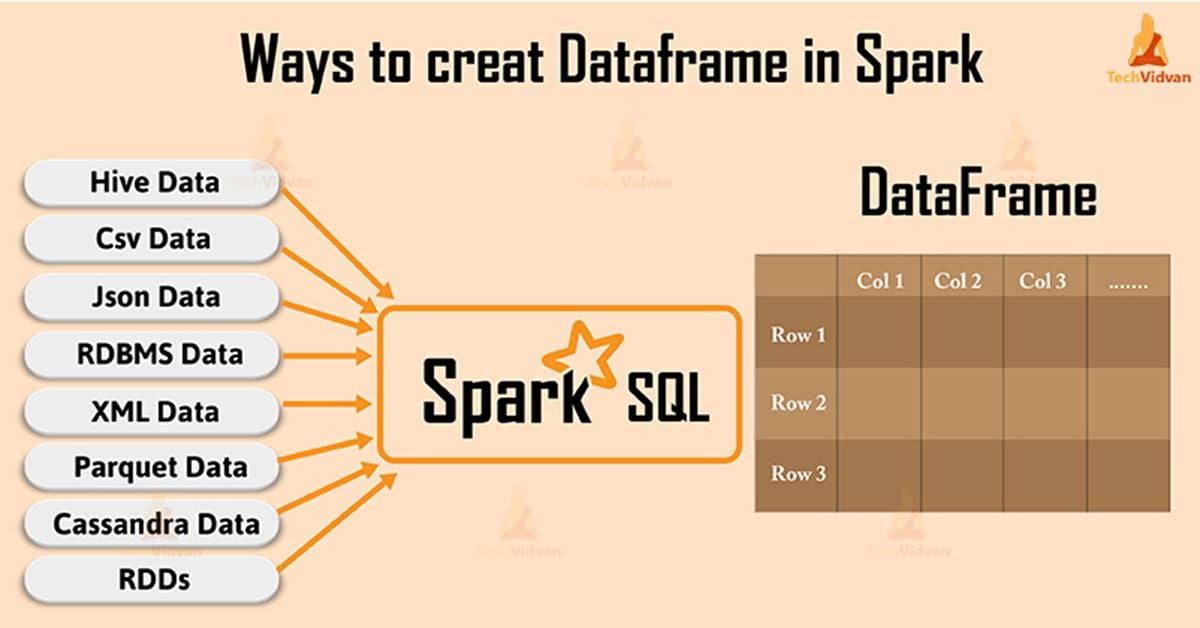
Introduction on Apache Spark SQL DataFrame TechVidvan
Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. Union [int, columnorname], * cols: spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. For a concrete example, consider the r5d.2xlarge instance in aws. methods to get the current number of partitions of a dataframe. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Columnorname) → dataframe [source] ¶ returns a new. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. returns a new :class:dataframe partitioned by the given partitioning expressions.
From www.vrogue.co
Spark And Pyspark Dataframes In Python Data In Python vrogue.co Number Of Partitions In Spark Dataframe spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the. Number Of Partitions In Spark Dataframe.
From stackoverflow.com
Partition a Spark DataFrame based on values in an existing column into Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: Columnorname) → dataframe [source] ¶ returns a new. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. returns. Number Of Partitions In Spark Dataframe.
From laptrinhx.com
Managing Partitions Using Spark Dataframe Methods LaptrinhX / News Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. returns a new :class:dataframe partitioned by the given partitioning expressions. Union [int, columnorname], * cols: Columnorname) → dataframe [source] ¶ returns a new. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task.. Number Of Partitions In Spark Dataframe.
From www.saoniuhuo.com
spark中的partition和partitionby_大数据知识库 Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the. Number Of Partitions In Spark Dataframe.
From techvidvan.com
Introduction on Apache Spark SQL DataFrame TechVidvan Number Of Partitions In Spark Dataframe pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. For a concrete example, consider the r5d.2xlarge instance in aws. in summary, you can easily find the number. Number Of Partitions In Spark Dataframe.
From dataninjago.com
Create Custom Partitioner for Spark Dataframe Azure Data Ninjago & dqops Number Of Partitions In Spark Dataframe For a concrete example, consider the r5d.2xlarge instance in aws. Columnorname) → dataframe [source] ¶ returns a new. Union [int, columnorname], * cols: one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. methods to get. Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Calculate Size of Spark DataFrame & RDD Spark By {Examples} Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new. Union [int, columnorname], * cols: spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. For a concrete example, consider the r5d.2xlarge. Number Of Partitions In Spark Dataframe.
From hxeiseozo.blob.core.windows.net
Partitions Number Spark at Vernon Hyman blog Number Of Partitions In Spark Dataframe For a concrete example, consider the r5d.2xlarge instance in aws. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. returns a new :class:dataframe partitioned by the given partitioning expressions. Union [int, columnorname], * cols: methods to get the current number of partitions of a dataframe. one common case is. Number Of Partitions In Spark Dataframe.
From towardsdatascience.com
How to repartition Spark DataFrames Towards Data Science Number Of Partitions In Spark Dataframe one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. returns a new :class:dataframe partitioned by the given partitioning expressions. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease. Number Of Partitions In Spark Dataframe.
From deepsense.ai
Optimize Spark with DISTRIBUTE BY & CLUSTER BY deepsense.ai Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. Columnorname) → dataframe [source] ¶ returns a new. pyspark.sql.dataframe.repartition(). Number Of Partitions In Spark Dataframe.
From www.youtube.com
Why should we partition the data in spark? YouTube Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. Columnorname) → dataframe [source] ¶ returns a new. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. pyspark.sql.dataframe.repartition() method. Number Of Partitions In Spark Dataframe.
From izhangzhihao.github.io
Spark The Definitive Guide In Short — MyNotes Number Of Partitions In Spark Dataframe one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Columnorname) → dataframe [source] ¶ returns a new. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. methods to get the current number of partitions of a dataframe.. Number Of Partitions In Spark Dataframe.
From www.youtube.com
How to Add Row Number to Spark Dataframe Unique ID Window YouTube Number Of Partitions In Spark Dataframe spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. Columnorname) → dataframe [source] ¶ returns a new. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. returns a new :class:dataframe partitioned by the given partitioning expressions.. Number Of Partitions In Spark Dataframe.
From www.nvidia.com
Introduction to Apache Spark Processing NVIDIA Number Of Partitions In Spark Dataframe For a concrete example, consider the r5d.2xlarge instance in aws. methods to get the current number of partitions of a dataframe. Union [int, columnorname], * cols: returns a new :class:dataframe partitioned by the given partitioning expressions. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. spark generally partitions your rdd. Number Of Partitions In Spark Dataframe.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Number Of Partitions In Spark Dataframe spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. returns a new :class:dataframe partitioned by the given partitioning expressions. Union [int, columnorname], * cols: in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying. Number Of Partitions In Spark Dataframe.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. Union [int, columnorname], * cols: spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of. Number Of Partitions In Spark Dataframe.
From stackoverflow.com
Joining Dataframe performance in Spark Stack Overflow Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. For a concrete. Number Of Partitions In Spark Dataframe.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions,. Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. Union [int, columnorname], * cols: returns. Number Of Partitions In Spark Dataframe.
From medium.com
On Spark Performance and partitioning strategies by Laurent Leturgez Number Of Partitions In Spark Dataframe returns a new :class:dataframe partitioned by the given partitioning expressions. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. Columnorname) → dataframe [source] ¶ returns a new.. Number Of Partitions In Spark Dataframe.
From www.youtube.com
Number of Partitions in Dataframe Spark Tutorial Interview Question Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new. methods to get the current number of partitions of a dataframe. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. For a. Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Number Of Partitions In Spark Dataframe in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Union [int, columnorname], * cols: pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. For. Number Of Partitions In Spark Dataframe.
From toien.github.io
Spark 分区数量 Kwritin Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. returns a new :class:dataframe partitioned by. Number Of Partitions In Spark Dataframe.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Number Of Partitions In Spark Dataframe For a concrete example, consider the r5d.2xlarge instance in aws. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Columnorname) → dataframe [source] ¶ returns a new. methods to get the current number of partitions of a dataframe. in summary, you can easily find the number of partitions of a dataframe. Number Of Partitions In Spark Dataframe.
From www.researchgate.net
Processing time of PSLIConSpark as the number of partitions is varied Number Of Partitions In Spark Dataframe spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. returns a. Number Of Partitions In Spark Dataframe.
From medium.com
Spark Under The Hood Partition. Spark is a distributed computing Number Of Partitions In Spark Dataframe in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of. Number Of Partitions In Spark Dataframe.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. methods to get the current number of partitions of a dataframe. returns a new :class:dataframe partitioned by the given partitioning expressions. in summary, you can. Number Of Partitions In Spark Dataframe.
From www.youtube.com
Trending Big Data Interview Question Number of Partitions in your Number Of Partitions In Spark Dataframe Union [int, columnorname], * cols: in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. For a concrete example, consider the r5d.2xlarge instance in aws.. Number Of Partitions In Spark Dataframe.
From sparkbyexamples.com
Calculate Size of Spark DataFrame & RDD Spark By {Examples} Number Of Partitions In Spark Dataframe one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. Union [int, columnorname], * cols: in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. methods to get the current number of partitions of a dataframe. spark generally partitions your rdd. Number Of Partitions In Spark Dataframe.
From itnext.io
Apache Spark Internals Tips and Optimizations by Javier Ramos ITNEXT Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. returns a new :class:dataframe partitioned by the given partitioning expressions. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. in summary, you can easily find the number of partitions of a. Number Of Partitions In Spark Dataframe.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Number Of Partitions In Spark Dataframe methods to get the current number of partitions of a dataframe. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. For a concrete example, consider the r5d.2xlarge instance in aws. Columnorname) → dataframe [source] ¶ returns a new. Union [int, columnorname], * cols: returns a new. Number Of Partitions In Spark Dataframe.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark Number Of Partitions In Spark Dataframe Columnorname) → dataframe [source] ¶ returns a new. methods to get the current number of partitions of a dataframe. in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. returns a new :class:dataframe partitioned by the given partitioning expressions. For a concrete example, consider the r5d.2xlarge instance. Number Of Partitions In Spark Dataframe.
From www.youtube.com
Determining the number of partitions YouTube Number Of Partitions In Spark Dataframe in summary, you can easily find the number of partitions of a dataframe in spark by accessing the underlying rdd. pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. returns a new :class:dataframe partitioned. Number Of Partitions In Spark Dataframe.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks Number Of Partitions In Spark Dataframe pyspark.sql.dataframe.repartition() method is used to increase or decrease the rdd/dataframe partitions by number of partitions or. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. Union [int, columnorname], * cols: methods to get the current number of partitions of a dataframe. one. Number Of Partitions In Spark Dataframe.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting Number Of Partitions In Spark Dataframe returns a new :class:dataframe partitioned by the given partitioning expressions. spark generally partitions your rdd based on the number of executors in cluster so that each executor gets fair share of the task. one common case is where the default number of partitions, defined by spark.sql.shuffle.partitions, is suboptimal. For a concrete example, consider the r5d.2xlarge instance in. Number Of Partitions In Spark Dataframe.