Back Propagation Neural Network Algorithm Pdf . An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Backpropagation (\backprop for short) is. Way of computing the partial derivatives of a loss function with respect to the parameters of a. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. But how can we actually learn them?. Roger grosse we've seen that multilayer neural networks are powerful. Linear classifiers learn one template per class. We must compute all the values of the neurons in the second layer. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Forward propagation is a fancy term for computing the output of a neural network. Linear classifiers can only draw linear decision.
from kevintham.github.io
We must compute all the values of the neurons in the second layer. Forward propagation is a fancy term for computing the output of a neural network. Roger grosse we've seen that multilayer neural networks are powerful. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Backpropagation (\backprop for short) is. Linear classifiers can only draw linear decision. Way of computing the partial derivatives of a loss function with respect to the parameters of a. But how can we actually learn them?.
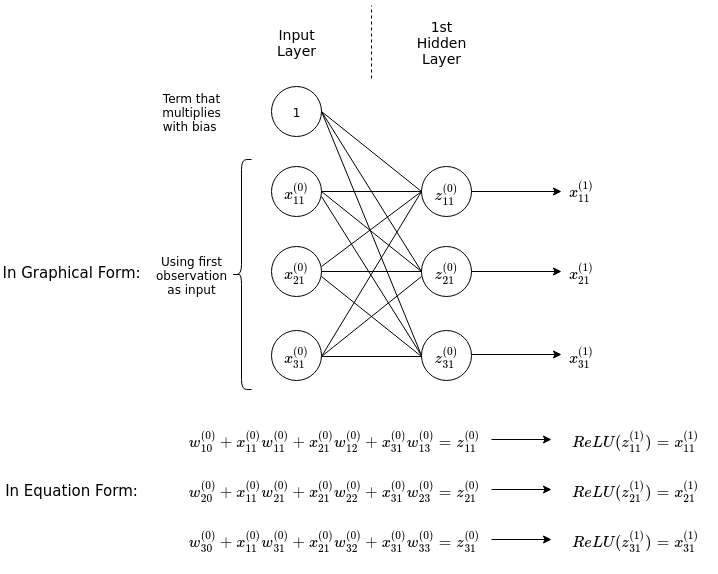
The Backpropagation Algorithm Kevin Tham
Back Propagation Neural Network Algorithm Pdf We must compute all the values of the neurons in the second layer. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. We must compute all the values of the neurons in the second layer. But how can we actually learn them?. Way of computing the partial derivatives of a loss function with respect to the parameters of a. Linear classifiers learn one template per class. Roger grosse we've seen that multilayer neural networks are powerful. Forward propagation is a fancy term for computing the output of a neural network. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Backpropagation (\backprop for short) is. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers can only draw linear decision.
From www.researchgate.net
The architecture of back propagation function neural network diagram Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. Forward propagation is a fancy term for computing the output of a neural network. Roger grosse we've seen that multilayer neural networks are powerful. Linear classifiers learn one template per class. The bp are networks, whose learning’s function tends to “distribute itself” on. Back Propagation Neural Network Algorithm Pdf.
From www.youtube.com
Backpropagation in Neural Network (explained in most simple way) YouTube Back Propagation Neural Network Algorithm Pdf Linear classifiers can only draw linear decision. But how can we actually learn them?. Forward propagation is a fancy term for computing the output of a neural network. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. An algorithm for computing the gradient. Back Propagation Neural Network Algorithm Pdf.
From loelcynte.blob.core.windows.net
Back Propagation Neural Network Classification at Stephen Vanhook blog Back Propagation Neural Network Algorithm Pdf An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers can only draw linear decision. Linear classifiers learn one template per class. But how can we actually learn them?. Roger grosse we've seen that multilayer neural networks are powerful. Forward propagation is a fancy term for computing the output of a. Back Propagation Neural Network Algorithm Pdf.
From kevintham.github.io
The Backpropagation Algorithm Kevin Tham Back Propagation Neural Network Algorithm Pdf In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Linear classifiers can only draw linear decision. But how can we actually learn them?. Roger grosse we've seen that multilayer neural networks are powerful. Backpropagation (\backprop for short) is. The bp are networks, whose learning’s function tends to “distribute itself” on the connections,. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Architecture of the backpropagation neural network (BPNN) algorithm Back Propagation Neural Network Algorithm Pdf The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. Linear classifiers can only draw linear decision. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers learn one template per class. We must compute. Back Propagation Neural Network Algorithm Pdf.
From www.youtube.com
Back Propagation Algorithm Artificial Neural Network Algorithm Machine Back Propagation Neural Network Algorithm Pdf An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Forward propagation is a fancy term for computing the output of a neural network. We must compute all the values of the neurons in the second layer. But how can we actually learn them?. In this lecture we will discuss the task of. Back Propagation Neural Network Algorithm Pdf.
From dev.to
Back Propagation in Neural Networks DEV Community Back Propagation Neural Network Algorithm Pdf Forward propagation is a fancy term for computing the output of a neural network. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. But how can we actually learn them?. Roger grosse we've seen that multilayer neural networks are powerful. Backpropagation (\backprop for short) is. Linear classifiers can only draw linear decision.. Back Propagation Neural Network Algorithm Pdf.
From www.chegg.com
Use the Backpropagation algorithm below to update Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. But how can we actually learn them?. We must compute all the values of the neurons in the second layer. Backpropagation (\backprop for short) is. Roger grosse we've seen that multilayer neural networks are powerful. In this lecture we will discuss the task. Back Propagation Neural Network Algorithm Pdf.
From afteracademy.com
Mastering Backpropagation in Neural Network Back Propagation Neural Network Algorithm Pdf Roger grosse we've seen that multilayer neural networks are powerful. Forward propagation is a fancy term for computing the output of a neural network. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. We must compute all the values of the neurons in the second layer. Linear classifiers can only draw linear. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Back propagation neural network topology structural diagram. Download Back Propagation Neural Network Algorithm Pdf The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. We must compute all the values of the neurons in the second layer. In this lecture we. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Basic structure of backpropagation neural network. Download Back Propagation Neural Network Algorithm Pdf In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. Way of computing the partial derivatives of a loss function with respect to the parameters of a.. Back Propagation Neural Network Algorithm Pdf.
From towardsdatascience.com
How Does BackPropagation Work in Neural Networks? by Kiprono Elijah Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. Backpropagation (\backprop for short) is. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. But how can we actually learn them?. Forward propagation is a fancy term for computing the output of a neural network.. Back Propagation Neural Network Algorithm Pdf.
From www.slideshare.net
Classification using back propagation algorithm Back Propagation Neural Network Algorithm Pdf But how can we actually learn them?. Linear classifiers learn one template per class. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. We must compute all the values of the neurons in the second layer. Way of computing the partial derivatives of a loss function with respect to the parameters of. Back Propagation Neural Network Algorithm Pdf.
From loelcynte.blob.core.windows.net
Back Propagation Neural Network Classification at Stephen Vanhook blog Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. Linear classifiers can only draw linear decision. But how can we actually learn them?. An algorithm for. Back Propagation Neural Network Algorithm Pdf.
From studyglance.in
Back Propagation NN Tutorial Study Glance Back Propagation Neural Network Algorithm Pdf Roger grosse we've seen that multilayer neural networks are powerful. Backpropagation (\backprop for short) is. We must compute all the values of the neurons in the second layer. Forward propagation is a fancy term for computing the output of a neural network. But how can we actually learn them?. Linear classifiers learn one template per class. An algorithm for computing. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Structure of a backpropagation neural network (BPNN) with a single Back Propagation Neural Network Algorithm Pdf Roger grosse we've seen that multilayer neural networks are powerful. Way of computing the partial derivatives of a loss function with respect to the parameters of a. Backpropagation (\backprop for short) is. Linear classifiers can only draw linear decision. But how can we actually learn them?. An algorithm for computing the gradient of a compound function as a series of. Back Propagation Neural Network Algorithm Pdf.
From www.geeksforgeeks.org
Backpropagation in Neural Network Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Way of computing the partial derivatives of a loss function with respect to the parameters of a. Linear classifiers can only draw linear decision. But how can we actually learn them?. Forward propagation is a fancy. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Traditional backpropagation neural network machine learning algorithm Back Propagation Neural Network Algorithm Pdf But how can we actually learn them?. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers learn one template per class. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. Linear classifiers can. Back Propagation Neural Network Algorithm Pdf.
From www.mql5.com
Backpropagation Neural Networks using MQL5 Matrices MQL5 Articles Back Propagation Neural Network Algorithm Pdf Backpropagation (\backprop for short) is. Linear classifiers can only draw linear decision. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. We must compute all the values of the neurons in the second layer. Linear. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Illustration of the architecture of the back propagation neural network Back Propagation Neural Network Algorithm Pdf In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Forward propagation is a fancy term for computing the output of a neural network. Way of computing the partial derivatives of a loss function with respect to the parameters of a. An algorithm for computing the gradient of a compound function as a. Back Propagation Neural Network Algorithm Pdf.
From www.linkedin.com
Back Propagation in Neural Networks Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. But how can we actually learn them?. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Way of computing. Back Propagation Neural Network Algorithm Pdf.
From www.dreamstime.com
The Backpropagation Algorithm Illustration, Scientific Infographics Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. We must compute all the values of the neurons in the second layer. Forward propagation is a fancy term for computing the output of a neural network. But how can we actually learn them?. Linear classifiers can only draw linear decision. An algorithm for computing the gradient of a compound function as a. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Feedforward Backpropagation Neural Network architecture. Download Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. But how can we actually learn them?. Backpropagation (\backprop for short) is. Forward propagation is a fancy term for computing the output of a neural network.. Back Propagation Neural Network Algorithm Pdf.
From www.techopedia.com
What is Backpropagation? Definition from Techopedia Back Propagation Neural Network Algorithm Pdf Linear classifiers can only draw linear decision. Linear classifiers learn one template per class. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. We must compute all the values of the neurons in the second layer. Roger grosse we've seen that multilayer neural networks are powerful. Backpropagation (\backprop for short) is. Way. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Structure of backpropagation neural network. Download Scientific Back Propagation Neural Network Algorithm Pdf Linear classifiers can only draw linear decision. Linear classifiers learn one template per class. Roger grosse we've seen that multilayer neural networks are powerful. But how can we actually learn them?. We must compute all the values of the neurons in the second layer. Forward propagation is a fancy term for computing the output of a neural network. The bp. Back Propagation Neural Network Algorithm Pdf.
From www.mdpi.com
Applied Sciences Free FullText PID Control Model Based on Back Back Propagation Neural Network Algorithm Pdf Roger grosse we've seen that multilayer neural networks are powerful. Linear classifiers can only draw linear decision. But how can we actually learn them?. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. We must compute all the values of the neurons in. Back Propagation Neural Network Algorithm Pdf.
From www.researchgate.net
Backpropagation training algorithm of MFNN. Download Scientific Diagram Back Propagation Neural Network Algorithm Pdf An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers learn one template per class. We must compute all the values of the neurons in the second layer. But how can we actually learn them?. Roger grosse we've seen that multilayer neural networks are powerful. Forward propagation is a fancy term. Back Propagation Neural Network Algorithm Pdf.
From towardsdatascience.com
Understanding Backpropagation Algorithm by Simeon Kostadinov Back Propagation Neural Network Algorithm Pdf Linear classifiers can only draw linear decision. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Forward propagation is a fancy term for computing the output of a neural network. Linear classifiers learn one template per class. Roger grosse we've seen that multilayer neural networks are powerful. An algorithm for computing the. Back Propagation Neural Network Algorithm Pdf.
From pdfslide.net
(PDF) of Artificial Neural Network Algorithms Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. Forward propagation is a fancy term for computing the output of a neural network. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Way of computing the partial derivatives of a loss function with respect to the parameters of a. Backpropagation (\backprop for short) is.. Back Propagation Neural Network Algorithm Pdf.
From mmuratarat.github.io
Backpropagation Through Time for Recurrent Neural Network Mustafa Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. Linear classifiers can only draw linear decision. But how can we actually learn them?. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Way of computing the partial. Back Propagation Neural Network Algorithm Pdf.
From medium.com
Backpropagation — Algorithm that tells “How A Neural Network Learns Back Propagation Neural Network Algorithm Pdf An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Roger grosse we've seen that multilayer neural networks are powerful. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. Forward propagation is a fancy term for. Back Propagation Neural Network Algorithm Pdf.
From www.qwertee.io
An introduction to backpropagation Back Propagation Neural Network Algorithm Pdf Linear classifiers learn one template per class. Backpropagation (\backprop for short) is. We must compute all the values of the neurons in the second layer. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Way. Back Propagation Neural Network Algorithm Pdf.
From www.semanticscholar.org
A Survey on Backpropagation Algorithms for Feedforward Neural Networks Back Propagation Neural Network Algorithm Pdf Forward propagation is a fancy term for computing the output of a neural network. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. In this lecture we will discuss the task of training neural networks using stochastic gradient descent algorithm. Backpropagation (\backprop for. Back Propagation Neural Network Algorithm Pdf.
From www.youtube.com
Neural Networks 11 Backpropagation in detail YouTube Back Propagation Neural Network Algorithm Pdf We must compute all the values of the neurons in the second layer. The bp are networks, whose learning’s function tends to “distribute itself” on the connections, just for the specific correction algorithm of the weights that is utilized. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Linear classifiers can only. Back Propagation Neural Network Algorithm Pdf.
From www.datasciencecentral.com
Neural Networks The Backpropagation algorithm in a picture Back Propagation Neural Network Algorithm Pdf Way of computing the partial derivatives of a loss function with respect to the parameters of a. Forward propagation is a fancy term for computing the output of a neural network. An algorithm for computing the gradient of a compound function as a series of local, intermediate gradients. Backpropagation (\backprop for short) is. We must compute all the values of. Back Propagation Neural Network Algorithm Pdf.