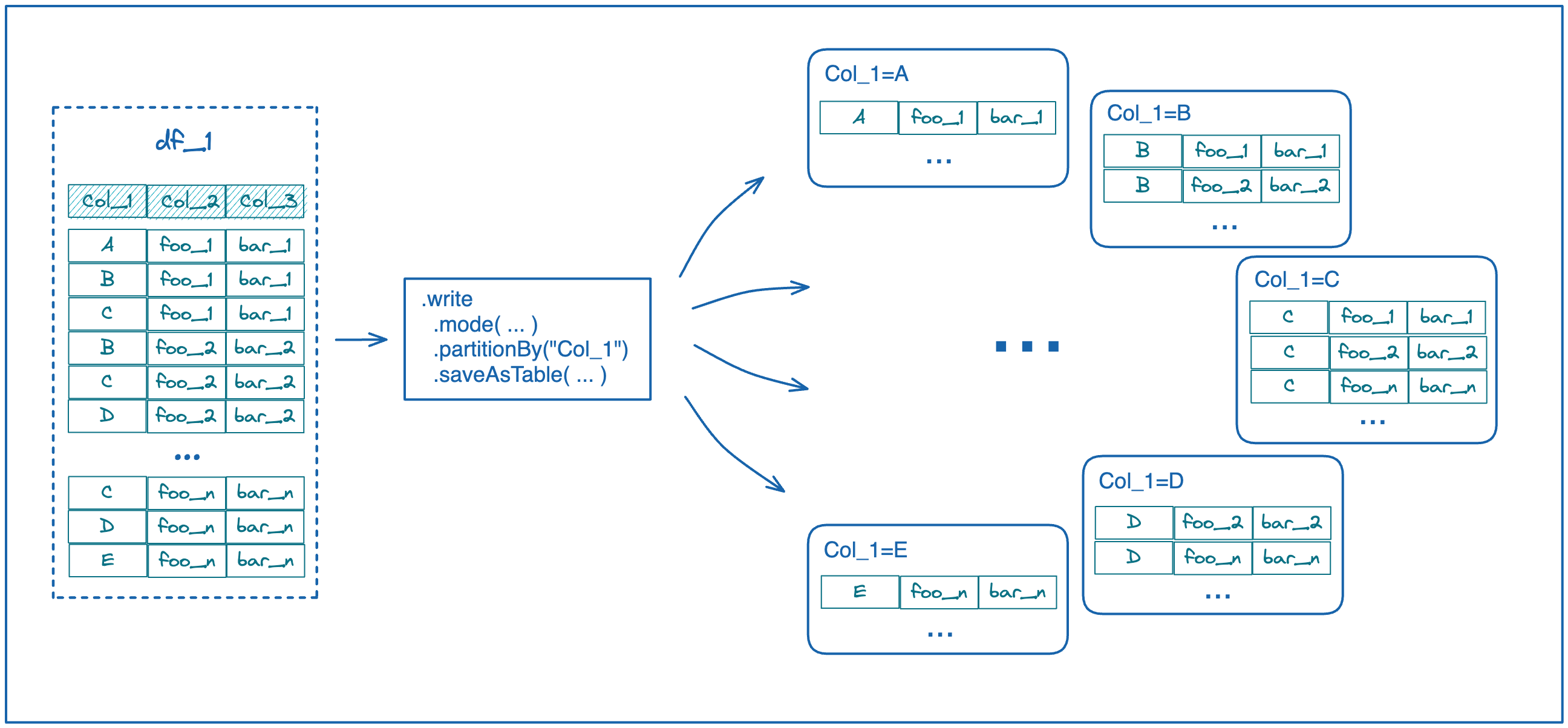
Bucketing Vs Partitioning Spark . The major difference between partitioning vs bucketing lives in the way how they split the data. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. Partitioning divides the data into. apache spark partitioning and bucketing. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe.
from www.newsletter.swirlai.com
in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. Partitioning divides the data into. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. The major difference between partitioning vs bucketing lives in the way how they split the data. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. apache spark partitioning and bucketing.
SAI 26 Partitioning and Bucketing in Spark (Part 1)
Bucketing Vs Partitioning Spark in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. apache spark partitioning and bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. The major difference between partitioning vs bucketing lives in the way how they split the data. Partitioning divides the data into. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs).
From pankajjagdale77.medium.com
Understanding Apache Spark Job Execution From Submission to Execution Bucketing Vs Partitioning Spark Partitioning divides the data into. The major difference between partitioning vs bucketing lives in the way how they split the data. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. hive partitioning vs bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Both partitioning. Bucketing Vs Partitioning Spark.
From medium.com
Partitioning vs Bucketing — In Apache Spark by Siddharth Ghosh Medium Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both partitioning and bucketing are techniques used to organize data in a spark. Bucketing Vs Partitioning Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Bucketing Vs Partitioning Spark apache spark partitioning and bucketing. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. Partitioning divides the data into. Both partitioning and bucketing in hive are used to improve performance by eliminating. Bucketing Vs Partitioning Spark.
From www.semanticscholar.org
Figure 1 from Partitioning and Bucketing Techniques to Speed up Query Bucketing Vs Partitioning Spark both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. both partitioning and bucketing are techniques used to organize data in a spark dataframe. Both partitioning and bucketing in hive are used to improve performance. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. hive partitioning vs bucketing. Partitioning divides the data into. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. both partitioning and bucketing are techniques used to organize data in a spark. Bucketing Vs Partitioning Spark.
From quadexcel.com
Partition vs bucketing Spark and Hive Interview Question Bucketing Vs Partitioning Spark The major difference between partitioning vs bucketing lives in the way how they split the data. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). hive partitioning vs bucketing. both partitioning and bucketing are techniques used to organize. Bucketing Vs Partitioning Spark.
From bigdatansql.com
Bucketing_With_Partitioning Big Data and SQL Bucketing Vs Partitioning Spark apache spark partitioning and bucketing. Partitioning divides the data into. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). hive partitioning vs bucketing. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark The major difference between partitioning vs bucketing lives in the way how they split the data. apache spark partitioning and bucketing. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both strategies aim to enhance performance and efficiency,. Bucketing Vs Partitioning Spark.
From www.youtube.com
Master Spark Partitioning and Bucketing Top Interview Questions Bucketing Vs Partitioning Spark both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. The major difference between. Bucketing Vs Partitioning Spark.
From medium.com
Apache Spark SQL Partitioning & Bucketing by Sandhiya M Medium Bucketing Vs Partitioning Spark hive partitioning vs bucketing. apache spark partitioning and bucketing. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. Partitioning divides the data into. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both strategies aim to enhance performance and efficiency, but they have. Bucketing Vs Partitioning Spark.
From medium.com
Partitioning vs Bucketing — In Apache Spark by Siddharth Ghosh Medium Bucketing Vs Partitioning Spark Partitioning divides the data into. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. both partitioning and bucketing are techniques used to organize data in a spark dataframe. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. Both partitioning and bucketing. Bucketing Vs Partitioning Spark.
From medium.com
Apache Spark Bucketing and Partitioning. by Jay Nerd For Tech Medium Bucketing Vs Partitioning Spark The major difference between partitioning vs bucketing lives in the way how they split the data. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning divides the data into. apache spark partitioning and bucketing. hive partitioning vs bucketing. both strategies aim to enhance performance and efficiency, but they. Bucketing Vs Partitioning Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. Both partitioning and bucketing. Bucketing Vs Partitioning Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Bucketing Vs Partitioning Spark Partitioning divides the data into. both partitioning and bucketing are techniques used to organize data in a spark dataframe. apache spark partitioning and bucketing. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. both strategies aim to enhance performance and efficiency, but they have distinct. Bucketing Vs Partitioning Spark.
From blog.det.life
Data Partitioning and Bucketing Examples and Best Practices by Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. The major difference between partitioning vs bucketing lives in the way how they. Bucketing Vs Partitioning Spark.
From datamasterylab.com
Partitioning Vs. Bucketing Key Characteristics And Differences Data Bucketing Vs Partitioning Spark The major difference between partitioning vs bucketing lives in the way how they split the data. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. apache spark partitioning and bucketing. Partitioning divides the data into. . Bucketing Vs Partitioning Spark.
From python.plainenglish.io
What is Partitioning vs Bucketing in Apache Hive? (Partitioning vs Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. The major difference between partitioning vs bucketing lives in the way how they split the data. apache spark partitioning and bucketing. in. Bucketing Vs Partitioning Spark.
From medium.com
Spark Partitioning vs Bucketing partitionBy vs bucketBy Medium Bucketing Vs Partitioning Spark in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. Partitioning divides the data into. apache spark partitioning and bucketing. The major difference between partitioning vs bucketing lives in the way how they split the. Bucketing Vs Partitioning Spark.
From www.youtube.com
Bucketing in Hive with Example Hive Partitioning with Bucketing Bucketing Vs Partitioning Spark both partitioning and bucketing are techniques used to organize data in a spark dataframe. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system. Bucketing Vs Partitioning Spark.
From www.youtube.com
Partitioning and bucketing in Spark Lec9 Practical video YouTube Bucketing Vs Partitioning Spark apache spark partitioning and bucketing. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. The major difference between partitioning vs bucketing lives in the way how they split the data. hive partitioning vs bucketing. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different. Bucketing Vs Partitioning Spark.
From medium.com
What All About Bucketing and Partitioning in Spark by Ankush Singh Bucketing Vs Partitioning Spark hive partitioning vs bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. The major difference between partitioning vs bucketing lives in the way how they split the data. in pyspark, databricks, and similar big. Bucketing Vs Partitioning Spark.
From www.newsletter.swirlai.com
SAI 26 Partitioning and Bucketing in Spark (Part 1) Bucketing Vs Partitioning Spark Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. partitioning and bucketing in pyspark refer to two different techniques for. Bucketing Vs Partitioning Spark.
From www.analyticsvidhya.com
Partitioning And Bucketing in Hive Bucketing vs Partitioning Bucketing Vs Partitioning Spark Partitioning divides the data into. both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios.. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). apache spark partitioning and bucketing. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. partitioning and bucketing. Bucketing Vs Partitioning Spark.
From medium.com
Partitioning vs Bucketing — In Apache Spark by Siddharth Ghosh Medium Bucketing Vs Partitioning Spark both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Partitioning divides the data into. apache spark partitioning and bucketing. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark hive partitioning vs bucketing. in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. Partitioning divides the data into. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. The major difference between partitioning vs bucketing lives in the way how they split the data.. Bucketing Vs Partitioning Spark.
From sparkbyexamples.com
Hive Partitioning vs Bucketing with Examples? Spark By {Examples} Bucketing Vs Partitioning Spark both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. apache spark partitioning and bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. Both partitioning and. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). both strategies aim to enhance performance and efficiency, but they have distinct characteristics. Bucketing Vs Partitioning Spark.
From www.vrogue.co
Hive Partitioning Vs Bucketing Advantages And Disadva vrogue.co Bucketing Vs Partitioning Spark apache spark partitioning and bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. Partitioning divides the data into. Both partitioning and bucketing in hive are used to improve performance by eliminating table. Bucketing Vs Partitioning Spark.
From medium.com
When to use Hive Partitioning and Bucketing? by Naveen Nelamali Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. The major difference between partitioning vs bucketing lives in. Bucketing Vs Partitioning Spark.
From sparkbyexamples.com
Spark Partitioning & Partition Understanding Spark By {Examples} Bucketing Vs Partitioning Spark in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different scenarios. hive partitioning vs bucketing. The major difference between partitioning vs bucketing lives in the way how they split the data. Partitioning divides the data into.. Bucketing Vs Partitioning Spark.
From medium.com
Partitioning vs Bucketing in Spark and Hive by Shivani Panchiwala Bucketing Vs Partitioning Spark partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. hive partitioning vs bucketing. Partitioning divides the data into. both strategies aim to enhance performance and efficiency, but they have distinct characteristics that cater to different. Bucketing Vs Partitioning Spark.
From kontext.tech
Spark Bucketing and Bucket Pruning Explained Bucketing Vs Partitioning Spark hive partitioning vs bucketing. partitioning and bucketing in pyspark refer to two different techniques for organizing data in a dataframe. both partitioning and bucketing are techniques used to organize data in a spark dataframe. apache spark partitioning and bucketing. Partitioning divides the data into. both strategies aim to enhance performance and efficiency, but they have. Bucketing Vs Partitioning Spark.
From blog.det.life
Data Partitioning and Bucketing Examples and Best Practices by Bucketing Vs Partitioning Spark apache spark partitioning and bucketing. hive partitioning vs bucketing. Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. both partitioning and bucketing. Bucketing Vs Partitioning Spark.
From realha.us.to
Hive Partitioning vs Bucketing Advantages and Disadvantages DataFlair Bucketing Vs Partitioning Spark Both partitioning and bucketing in hive are used to improve performance by eliminating table scans when dealing with a large set of data on a hadoop file system (hdfs). in pyspark, databricks, and similar big data processing platforms, partitioning and bucketing are techniques. hive partitioning vs bucketing. apache spark partitioning and bucketing. Partitioning divides the data into.. Bucketing Vs Partitioning Spark.