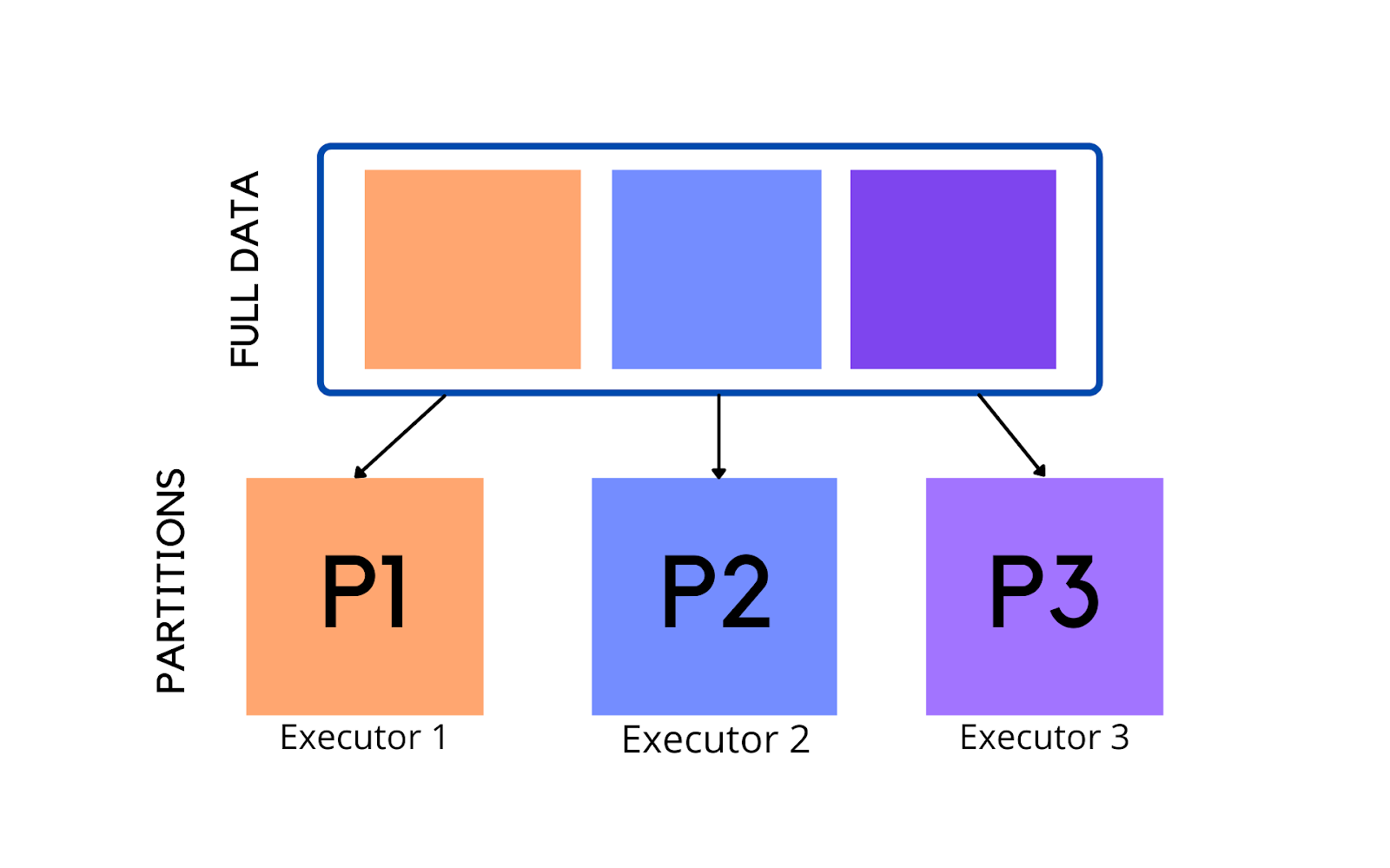
Default Number Of Partitions In Spark . Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. What is the default number of spark partitions and how can it be configured? Let's start with some basic default and desired spark configuration parameters. There is no default partitioning logic applied. I am trying to see the number of partitions that spark is creating by default. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. The default number of spark partitions can vary depending on the mode and environment, such as local. Default spark shuffle partitions — 200; A dataframe is partitioned dependent on the number of tasks that run to create it. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks.
from www.projectpro.io
Let's start with some basic default and desired spark configuration parameters. The default number of spark partitions can vary depending on the mode and environment, such as local. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. There is no default partitioning logic applied. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. What is the default number of spark partitions and how can it be configured? I am trying to see the number of partitions that spark is creating by default. Default spark shuffle partitions — 200; When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. A dataframe is partitioned dependent on the number of tasks that run to create it.
How Data Partitioning in Spark helps achieve more parallelism?
Default Number Of Partitions In Spark Let's start with some basic default and desired spark configuration parameters. The default number of spark partitions can vary depending on the mode and environment, such as local. What is the default number of spark partitions and how can it be configured? Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. A dataframe is partitioned dependent on the number of tasks that run to create it. I am trying to see the number of partitions that spark is creating by default. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. There is no default partitioning logic applied.
From www.jowanza.com
Partitions in Apache Spark — Jowanza Joseph Default Number Of Partitions In Spark I am trying to see the number of partitions that spark is creating by default. A dataframe is partitioned dependent on the number of tasks that run to create it. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Default spark shuffle partitions — 200; There. Default Number Of Partitions In Spark.
From sparkbyexamples.com
Get the Size of Each Spark Partition Spark By {Examples} Default Number Of Partitions In Spark I am trying to see the number of partitions that spark is creating by default. The default number of spark partitions can vary depending on the mode and environment, such as local. What is the default number of spark partitions and how can it be configured? When spark reads data from a distributed storage system like hdfs or s3, it. Default Number Of Partitions In Spark.
From blogs.perficient.com
Spark Partition An Overview / Blogs / Perficient Default Number Of Partitions In Spark A dataframe is partitioned dependent on the number of tasks that run to create it. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Default spark shuffle partitions — 200; I am trying to see. Default Number Of Partitions In Spark.
From www.simplilearn.com
Spark Parallelize The Essential Element of Spark Default Number Of Partitions In Spark When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. A dataframe is partitioned dependent on the number of tasks that run to create it. What is the default number of spark partitions and how can it be configured? I am trying to. Default Number Of Partitions In Spark.
From www.youtube.com
How to find Data skewness in spark / How to get count of rows from each partition in spark Default Number Of Partitions In Spark There is no default partitioning logic applied. What is the default number of spark partitions and how can it be configured? Let's start with some basic default and desired spark configuration parameters. A dataframe is partitioned dependent on the number of tasks that run to create it. I am trying to see the number of partitions that spark is creating. Default Number Of Partitions In Spark.
From exokeufcv.blob.core.windows.net
Max Number Of Partitions In Spark at Manda Salazar blog Default Number Of Partitions In Spark When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. Default spark shuffle partitions — 200; Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. What is the default number of spark partitions and how can it be configured? I am. Default Number Of Partitions In Spark.
From leecy.me
Spark partitions A review Default Number Of Partitions In Spark When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. What is the default number of spark partitions and how can it be configured? When spark. Default Number Of Partitions In Spark.
From www.researchgate.net
Spark partition an LMDB Database Download Scientific Diagram Default Number Of Partitions In Spark Let's start with some basic default and desired spark configuration parameters. I am trying to see the number of partitions that spark is creating by default. There is no default partitioning logic applied. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. A dataframe is partitioned. Default Number Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Salesforce Engineering Blog Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. Default spark shuffle partitions — 200; The default number of spark partitions can vary depending on the mode and environment, such as local. There is no. Default Number Of Partitions In Spark.
From stackoverflow.com
How does Spark SQL decide the number of partitions it will use when loading data from a Hive Default Number Of Partitions In Spark Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. Default spark shuffle partitions — 200; When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. The default number of spark partitions can vary depending on the mode and environment, such as local. When you read. Default Number Of Partitions In Spark.
From stackoverflow.com
optimization Spark AQE drastically reduces number of partitions Stack Overflow Default Number Of Partitions In Spark Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. The default number of spark partitions can vary depending on the mode and environment, such as local. I am trying to see. Default Number Of Partitions In Spark.
From statusneo.com
Everything you need to understand Data Partitioning in Spark StatusNeo Default Number Of Partitions In Spark I am trying to see the number of partitions that spark is creating by default. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. A dataframe is partitioned dependent on the number of tasks that run to create it. Let's start with some basic default and. Default Number Of Partitions In Spark.
From pedropark99.github.io
Introduction to pyspark 3 Introducing Spark DataFrames Default Number Of Partitions In Spark The default number of spark partitions can vary depending on the mode and environment, such as local. Default spark shuffle partitions — 200; There is no default partitioning logic applied. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for. Default Number Of Partitions In Spark.
From www.youtube.com
Apache Spark Data Partitioning Example YouTube Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. The default number of spark partitions can vary depending on the mode and environment, such as local. Default spark shuffle partitions — 200; A dataframe is partitioned dependent on the number of tasks that run to create. Default Number Of Partitions In Spark.
From techvidvan.com
Apache Spark Partitioning and Spark Partition TechVidvan Default Number Of Partitions In Spark Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. What is the default number of spark partitions and how can it be configured? When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. A dataframe. Default Number Of Partitions In Spark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Default Number Of Partitions In Spark What is the default number of spark partitions and how can it be configured? When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. The default number of spark partitions can vary depending on the mode and environment, such as local. Val rdd1 = sc.parallelize(1 to 10). Default Number Of Partitions In Spark.
From exoocknxi.blob.core.windows.net
Set Partitions In Spark at Erica Colby blog Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. I am trying to see the number of partitions that spark is creating by default. Default spark shuffle partitions — 200; Let's start with some basic default and desired spark configuration parameters. What is the default number. Default Number Of Partitions In Spark.
From naifmehanna.com
Efficiently working with Spark partitions · Naif Mehanna Default Number Of Partitions In Spark Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. A dataframe is partitioned dependent on the number of tasks that run to create it. There is no default partitioning logic applied. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks.. Default Number Of Partitions In Spark.
From cookinglove.com
Spark partition size limit Default Number Of Partitions In Spark I am trying to see the number of partitions that spark is creating by default. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. The default number of spark partitions can vary depending on the mode and environment, such as local. When. Default Number Of Partitions In Spark.
From www.projectpro.io
How Data Partitioning in Spark helps achieve more parallelism? Default Number Of Partitions In Spark When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. A dataframe is partitioned dependent on the number of tasks that run to create it. I am trying to see the number of partitions that spark is creating by default. The default number. Default Number Of Partitions In Spark.
From toien.github.io
Spark 分区数量 Kwritin Default Number Of Partitions In Spark Let's start with some basic default and desired spark configuration parameters. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. There is no default partitioning logic applied. A dataframe is partitioned dependent on the number of tasks that run to create it. When you read data from a source (e.g., a text file, a csv file, or a. Default Number Of Partitions In Spark.
From www.youtube.com
How to partition and write DataFrame in Spark without deleting partitions with no new data Default Number Of Partitions In Spark Let's start with some basic default and desired spark configuration parameters. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Default spark shuffle partitions — 200; A dataframe is partitioned dependent on the number of tasks that run to create it. What is the default number. Default Number Of Partitions In Spark.
From www.youtube.com
Spark Application Partition By in Spark Chapter 2 LearntoSpark YouTube Default Number Of Partitions In Spark There is no default partitioning logic applied. A dataframe is partitioned dependent on the number of tasks that run to create it. What is the default number of spark partitions and how can it be configured? The default number of spark partitions can vary depending on the mode and environment, such as local. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions). Default Number Of Partitions In Spark.
From medium.com
Spark’s structured API’s. Although we can access Spark from a… by ravi g Medium Default Number Of Partitions In Spark Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. What is the default number of spark partitions and how can it be configured? The default number of spark partitions can vary depending on the mode and environment, such as local. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition. Default Number Of Partitions In Spark.
From spaziocodice.com
Spark SQL Partitions and Sizes SpazioCodice Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. I am trying to see the number of partitions that spark is creating by default. There is no default partitioning logic applied. Default spark shuffle partitions — 200; The default number of spark partitions can vary depending. Default Number Of Partitions In Spark.
From cloud-fundis.co.za
Dynamically Calculating Spark Partitions at Runtime Cloud Fundis Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. There is no default partitioning logic applied. Default spark shuffle partitions — 200; I am trying to see the number of partitions that spark is creating. Default Number Of Partitions In Spark.
From stackoverflow.com
apache spark How many partitions does pyspark create while reading a csv of a relatively small Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Default spark shuffle partitions — 200; When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. A dataframe is partitioned. Default Number Of Partitions In Spark.
From blog.csdn.net
spark基本知识点之Shuffle_separate file for each media typeCSDN博客 Default Number Of Partitions In Spark What is the default number of spark partitions and how can it be configured? There is no default partitioning logic applied. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. A dataframe is partitioned dependent. Default Number Of Partitions In Spark.
From klaojgfcx.blob.core.windows.net
How To Determine Number Of Partitions In Spark at Troy Powell blog Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. The default number of spark partitions can vary depending on the mode and environment, such as local. I am trying to see the number of partitions that spark is creating by default. What is the default number. Default Number Of Partitions In Spark.
From engineering.salesforce.com
How to Optimize Your Apache Spark Application with Partitions Salesforce Engineering Blog Default Number Of Partitions In Spark There is no default partitioning logic applied. Let's start with some basic default and desired spark configuration parameters. What is the default number of spark partitions and how can it be configured? The default number of spark partitions can vary depending on the mode and environment, such as local. Default spark shuffle partitions — 200; I am trying to see. Default Number Of Partitions In Spark.
From www.youtube.com
Number of Partitions in Dataframe Spark Tutorial Interview Question YouTube Default Number Of Partitions In Spark What is the default number of spark partitions and how can it be configured? There is no default partitioning logic applied. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. The default number of spark. Default Number Of Partitions In Spark.
From www.projectpro.io
DataFrames number of partitions in spark scala in Databricks Default Number Of Partitions In Spark There is no default partitioning logic applied. Default spark shuffle partitions — 200; A dataframe is partitioned dependent on the number of tasks that run to create it. I am trying to see the number of partitions that spark is creating by default. The default number of spark partitions can vary depending on the mode and environment, such as local.. Default Number Of Partitions In Spark.
From best-practice-and-impact.github.io
Managing Partitions — Spark at the ONS Default Number Of Partitions In Spark When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data. There is no default partitioning logic applied. When you read data from a source (e.g., a text file, a csv file, or a parquet file), spark automatically creates partitions based on the file blocks. I am trying. Default Number Of Partitions In Spark.
From sparkbyexamples.com
Spark Get Current Number of Partitions of DataFrame Spark By {Examples} Default Number Of Partitions In Spark There is no default partitioning logic applied. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. Let's start with some basic default and desired spark configuration parameters. What is the default number of spark partitions and how can it be configured? When you read data from a source (e.g., a text file, a csv file, or a parquet. Default Number Of Partitions In Spark.
From stackoverflow.com
scala Apache spark Number of tasks less than the number of partitions Stack Overflow Default Number Of Partitions In Spark A dataframe is partitioned dependent on the number of tasks that run to create it. Val rdd1 = sc.parallelize(1 to 10) println(rdd1.getnumpartitions) // ==> result is. Let's start with some basic default and desired spark configuration parameters. When spark reads data from a distributed storage system like hdfs or s3, it typically creates a partition for each block of data.. Default Number Of Partitions In Spark.