Have you ever wondered how modern systems efficiently manage database resources without constant overhead? The answer lies in table pooling, a powerful technique that optimizes performance and scalability. In this guide, we'll unravel the mystery of how table pool works and why it's essential for today's data-driven applications.

How Does Table Pool Work? Breaking Down the Core Mechanism
Table pooling is a resource management strategy primarily used in database systems to enhance performance and reduce the overhead associated with creating and destroying tables. Instead of instantiating new tables for each request, a pool of pre-initialized tables is maintained. When a request comes in, the system borrows a table from the pool, uses it, and returns it back to the pool after completion. This approach minimizes the time spent on table setup and teardown, significantly speeding up operations. The pool manager handles allocation and deallocation, ensuring that resources are reused efficiently without the need for repeated initialization.
The Benefits of Implementing a Table Pool System
Implementing a table pool offers several key advantages. Firstly, it drastically reduces latency by eliminating the time-consuming process of creating and configuring tables on the fly. This is particularly beneficial in high-traffic environments where every millisecond counts. Secondly, it conserves system resources, as the same tables are reused, leading to lower memory usage and faster response times. Additionally, table pooling improves scalability and stability, as the system can handle more concurrent requests without degrading performance. This makes it an ideal solution for applications requiring rapid data access, such as e-commerce platforms or real-time analytics systems.

Common Use Cases and Real-World Applications
Table pooling is widely applied in various domains. In cloud databases like Amazon RDS or Google Cloud SQL, table pools optimize the handling of multiple user requests by reusing connection resources. Web applications also leverage table pooling to manage sessions and user data efficiently, ensuring a seamless user experience. Another notable use case is in big data processing frameworks where temporary tables are frequently created and destroyed; pooling allows for rapid data transformations without the overhead of constant table creation. By adopting table pooling, organizations can achieve higher throughput and better resource utilization, making it a cornerstone of modern data infrastructure.
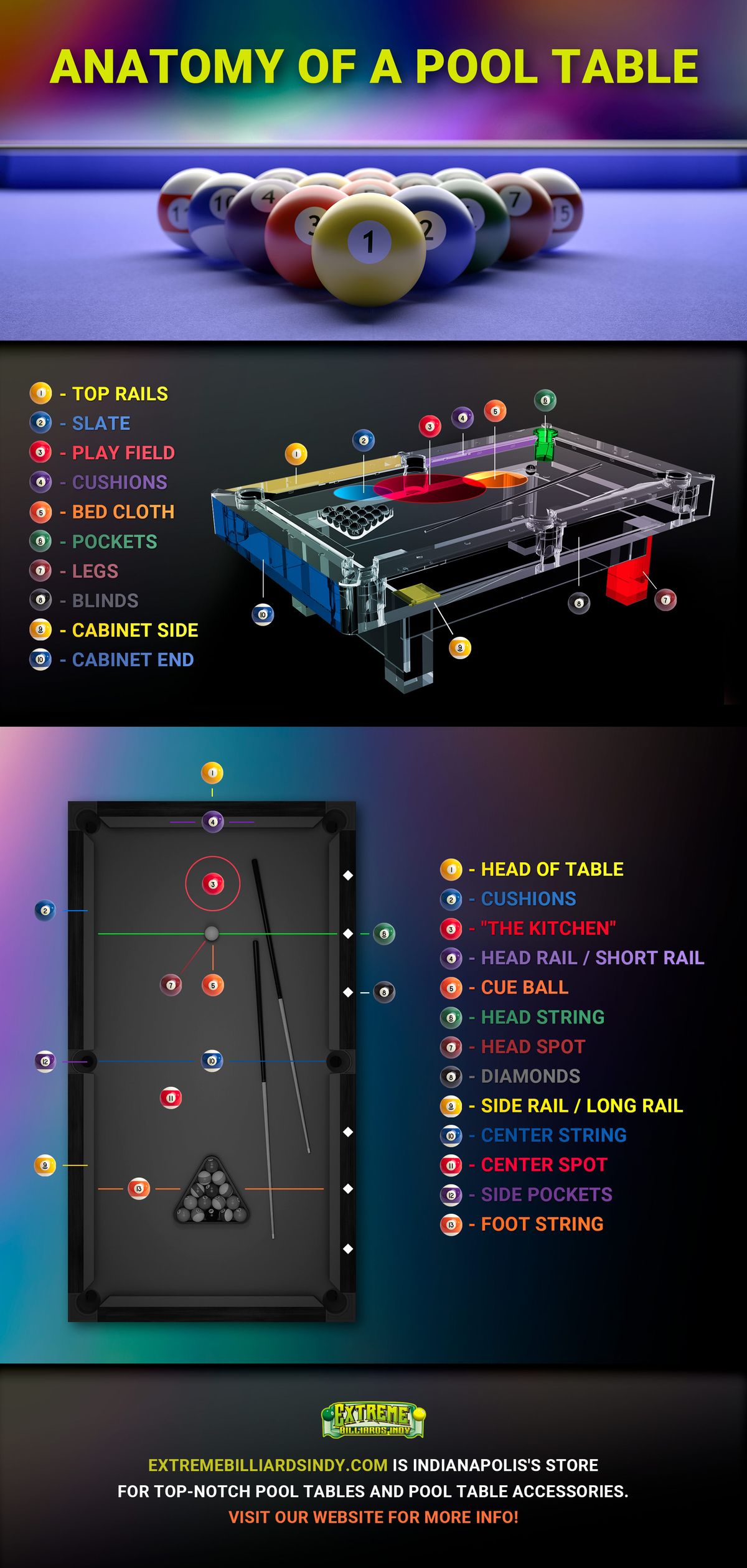
Understanding how table pool works is crucial for building efficient, scalable systems. By leveraging table pooling, you can enhance performance, reduce resource consumption, and handle increased workloads with ease. Ready to optimize your database operations? Start exploring table pooling techniques today and unlock the full potential of your data infrastructure.