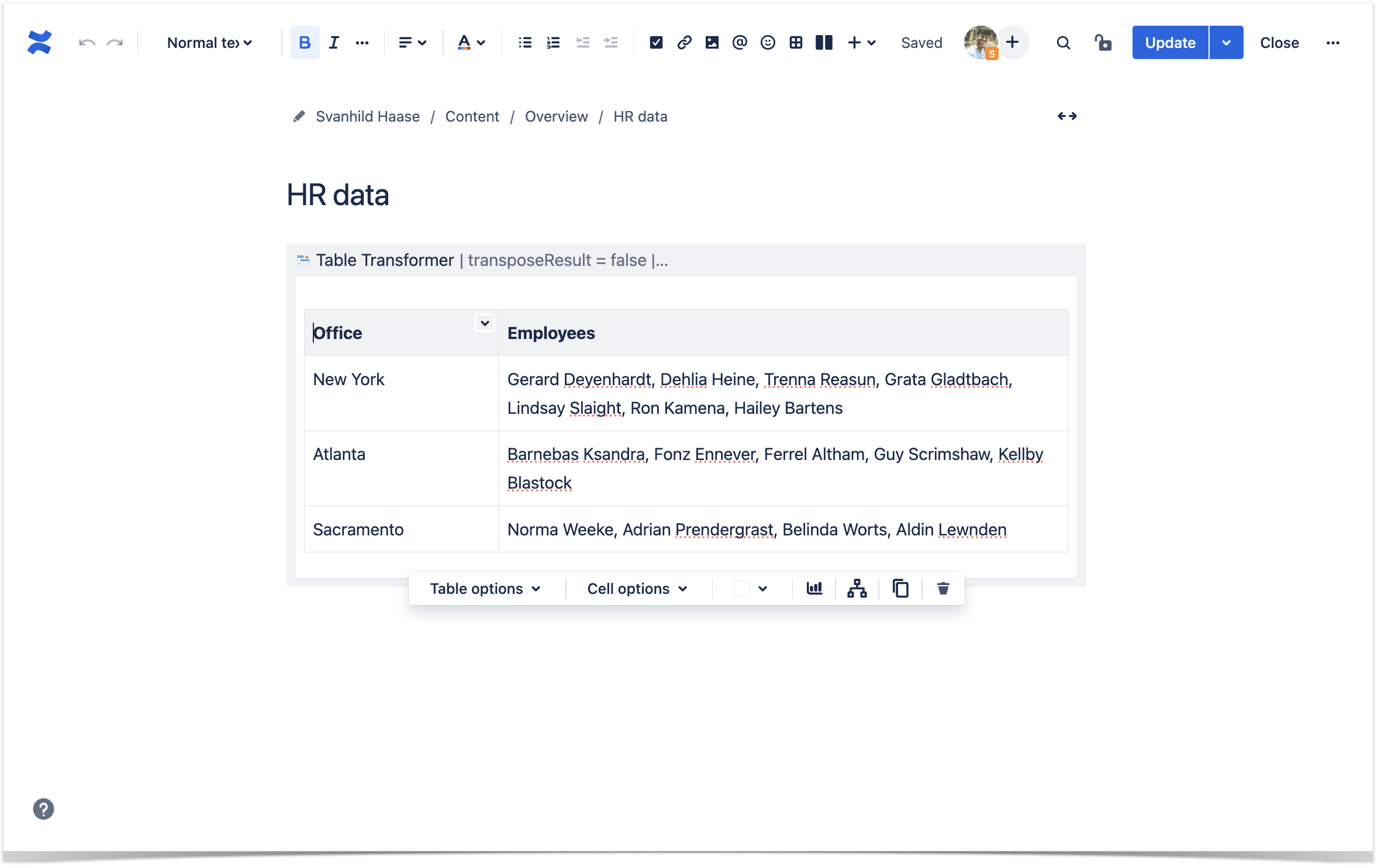
In the evolving landscape of data management, mastering the Confluence table transformer join is essential for efficient merging of structured datasets within Confluence environments. This technique ensures seamless integration, reducing errors and improving query performance when combining information from multiple sources.
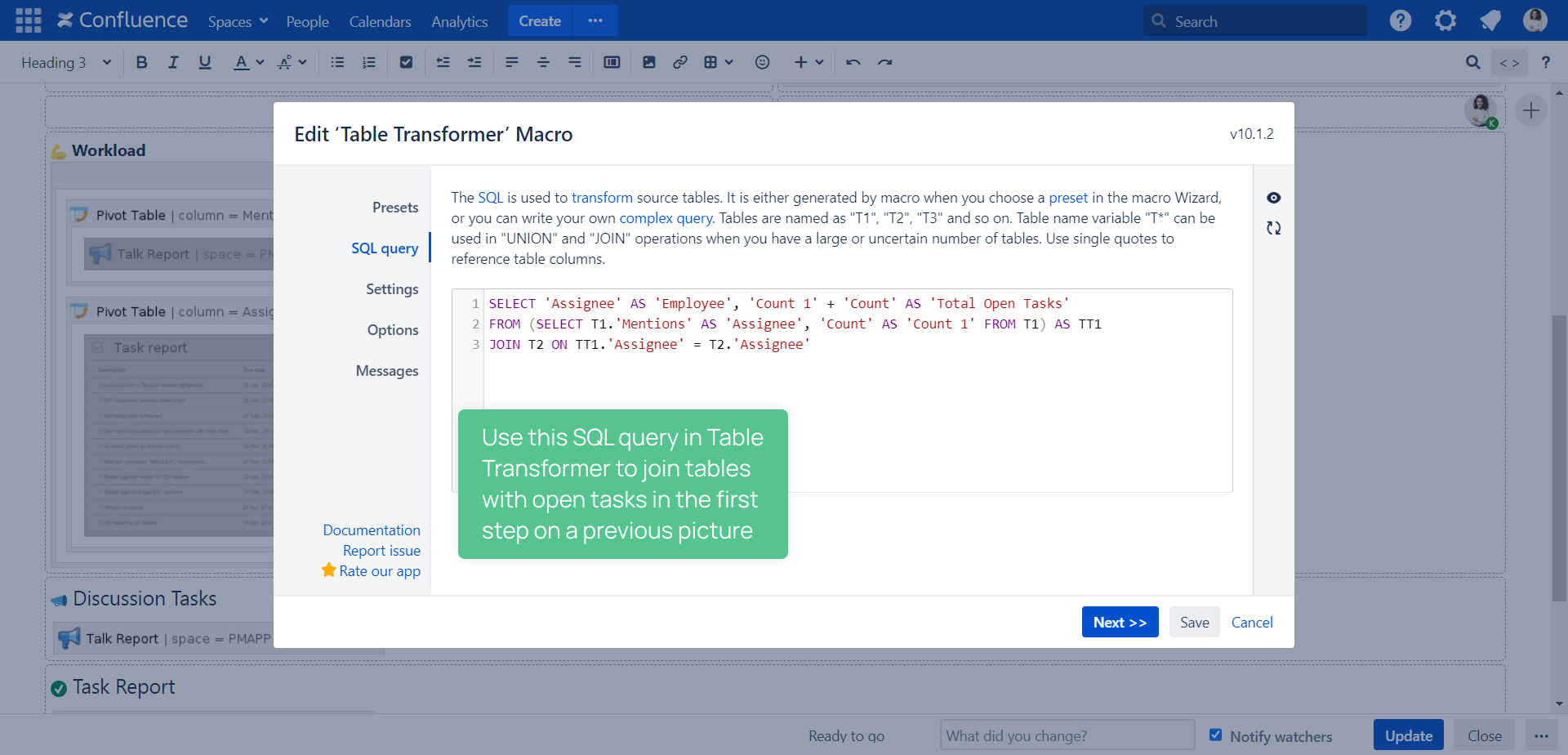
Understanding the Confluence Table Transformer Join
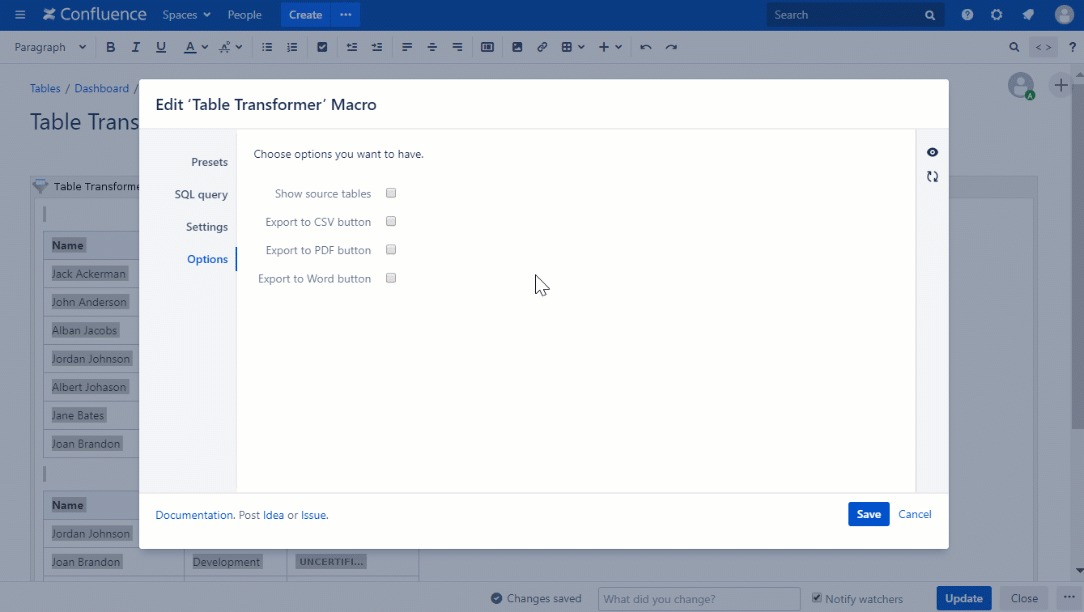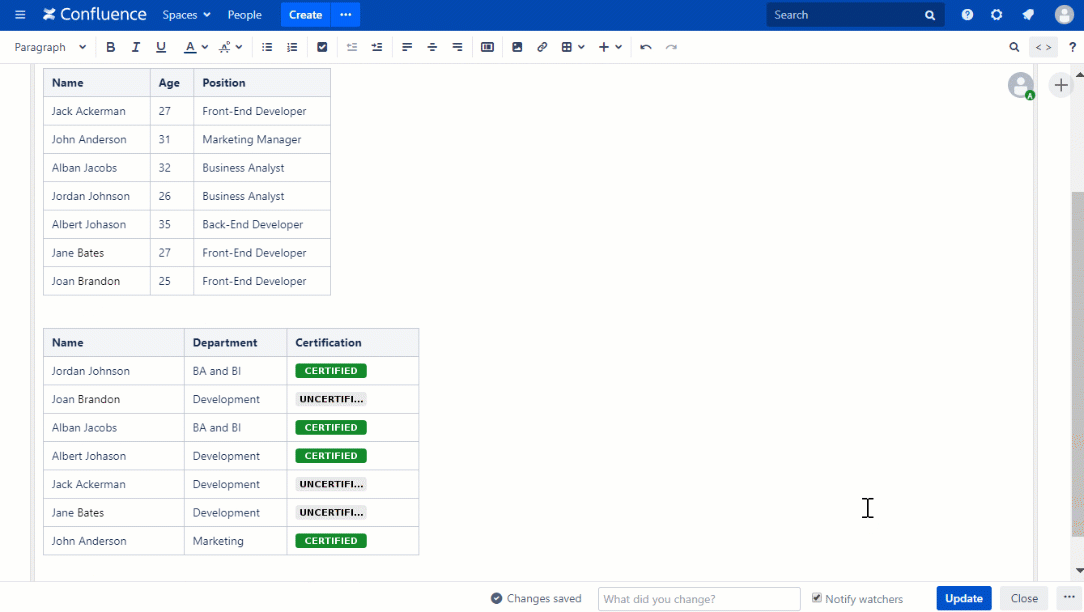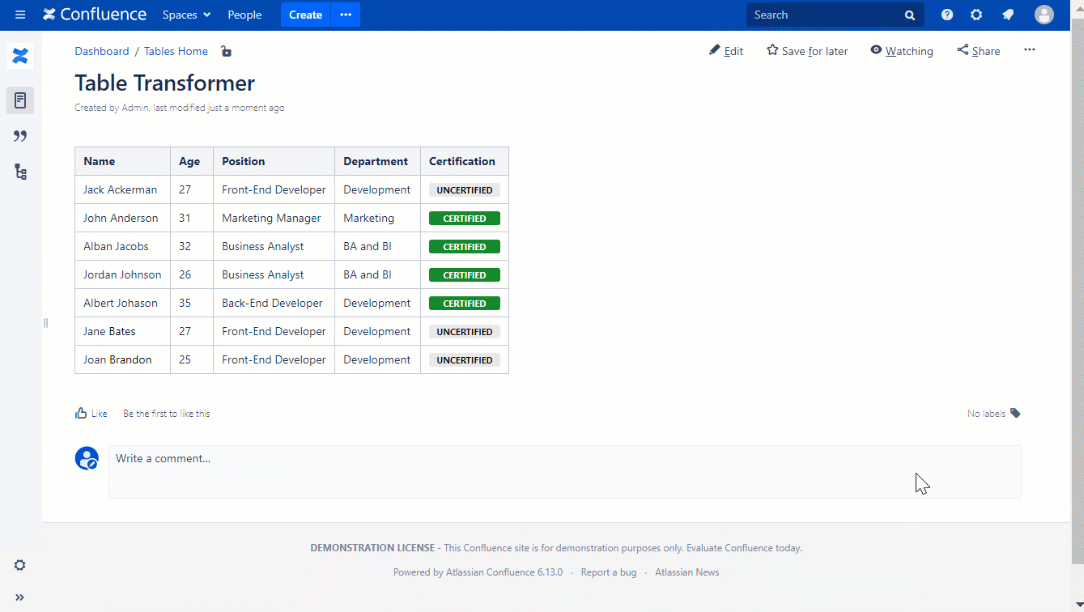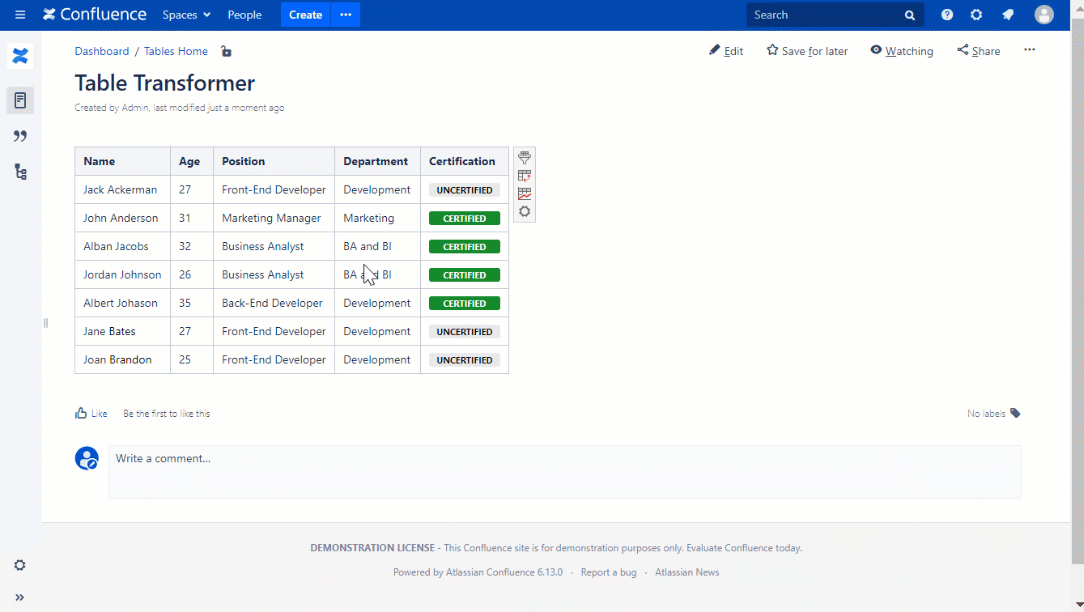
The Confluence table transformer join is a specialized SQL operation that combines rows from two or more tables based on defined matching keys, typically within Confluence’s relational data structures. Unlike standard joins, it leverages transformer logic to dynamically adapt field mappings, handle data type conversions, and apply transformation rules directly during the join process. This approach minimizes data inconsistency and enhances real-time data synchronization across platforms.
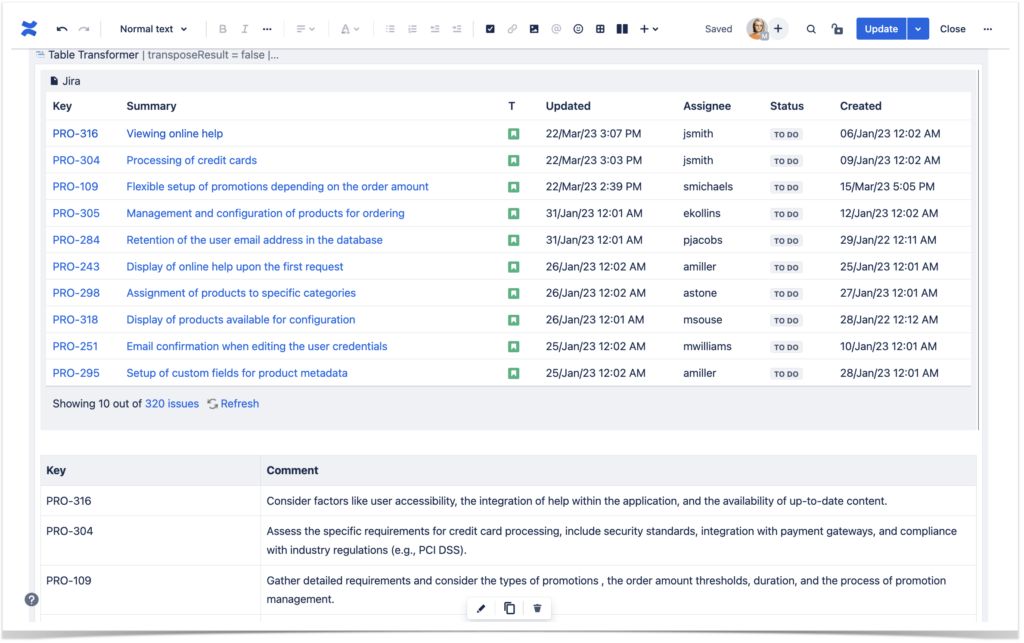
Implementing Joins Effectively in Confluence
To execute a Confluence table transformer join, start by identifying primary and secondary tables using unique identifiers such as IDs or timestamps. Use lightweight transformations—like type casting, truncation, or regex matching—to align schema differences. Apply WHERE clauses to filter relevant matches and ORDER BY clauses to ensure consistent result ordering. Proper indexing and pre-aggregation further optimize performance, especially when dealing with large datasets. Testing with sample data ensures accuracy before full deployment.

Best Practices for High-Performance Joins
Prioritize indexing on join keys to drastically reduce query latency. Avoid over-transforming data to prevent unnecessary processing overhead. Use aliases consistently to maintain clarity and reduce join ambiguity. Monitor join execution plans regularly and adjust indexes or queries as data patterns evolve. Leveraging Confluence’s built-in query APIs ensures compatibility and stability, while integrating transformation logic within the join scope boosts both speed and data integrity.
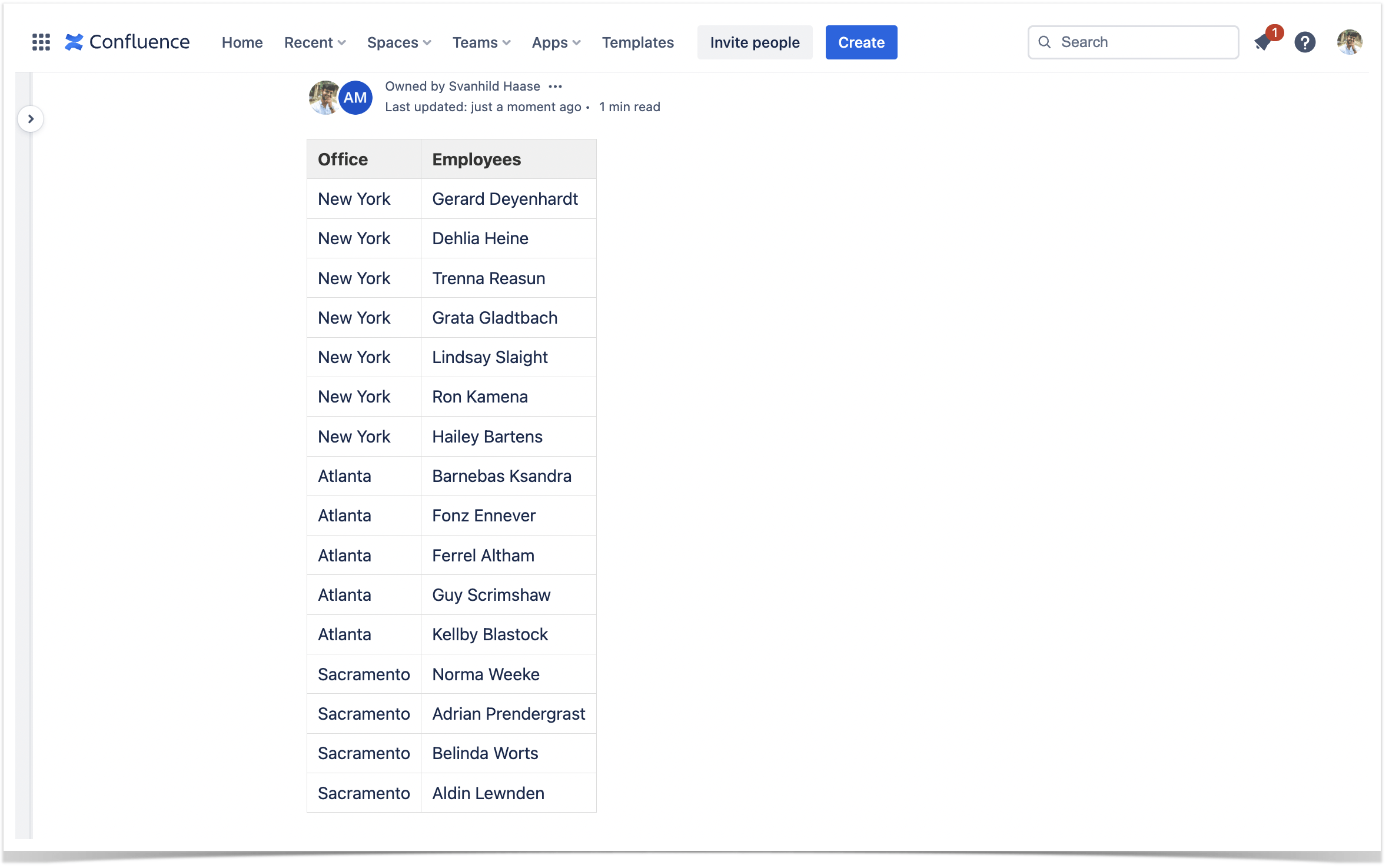
The Confluence table transformer join empowers developers and data architects to unify disparate datasets with precision and efficiency. By mastering this technique, teams unlock faster insights, stronger data governance, and improved system interoperability. Begin optimizing your Confluence data workflows today—transforming joins from a technical hurdle into a strategic advantage.