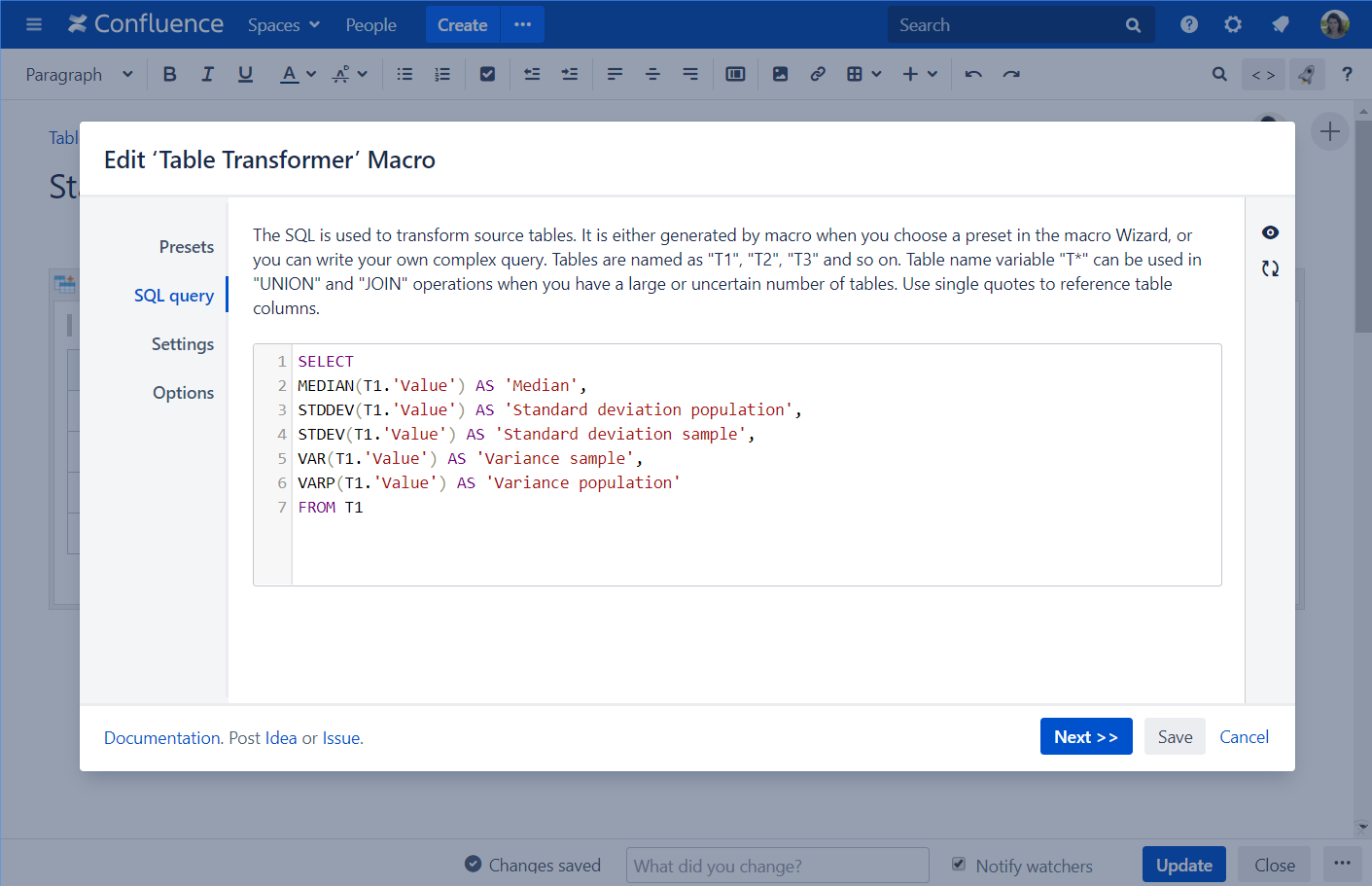
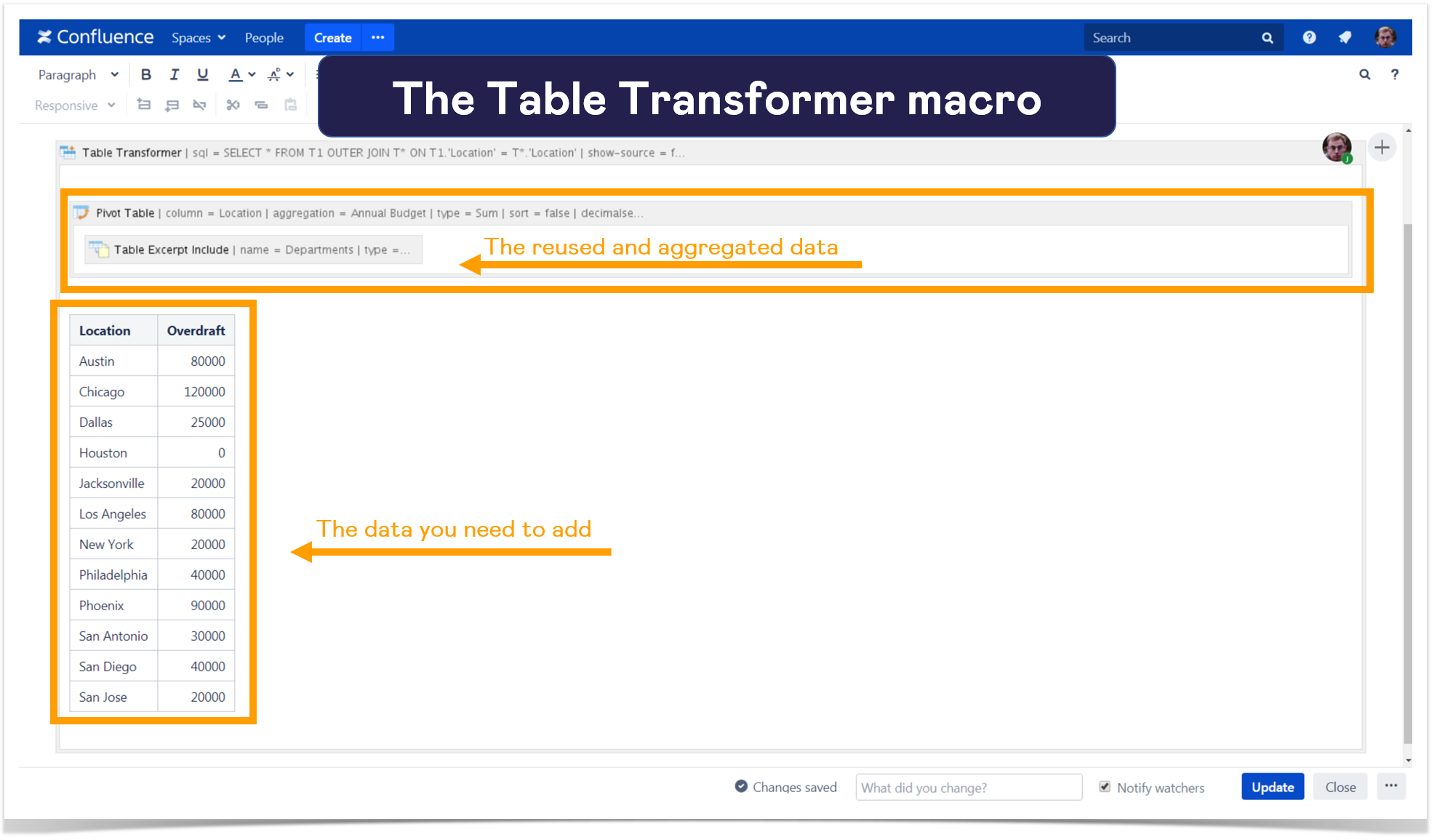
Efficiently transforming and querying Confluence table data is critical for maintaining seamless documentation workflows. The Confluence Table Transformer SQL Query enables precise data extraction and manipulation, empowering teams to harness structured content with minimal latency.
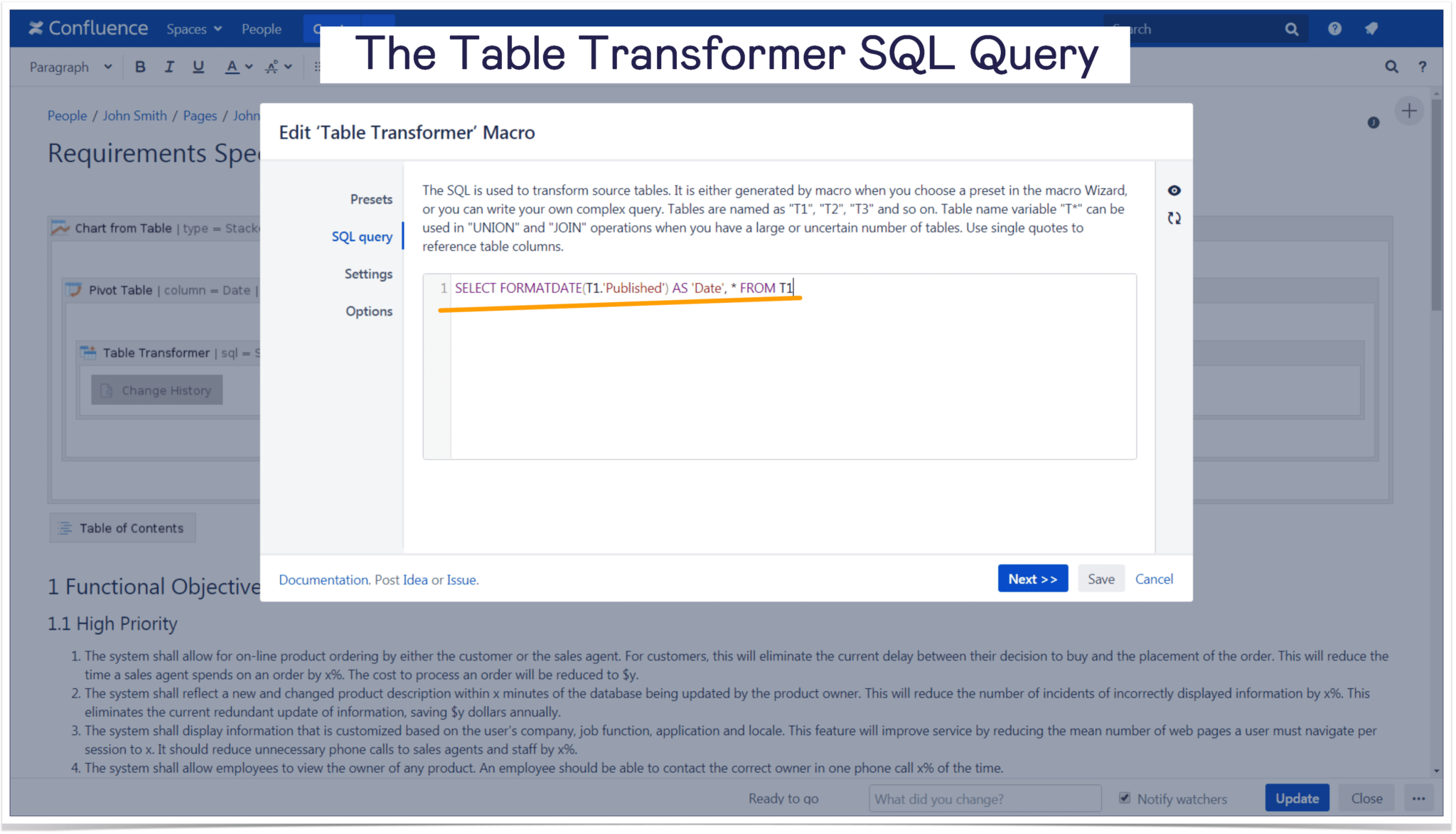
Core Components of the Query Pattern
Key elements include using UNNEST for array decomposition, COALESCE for handling nulls, and window functions for row-level analysis. Proper indexing on pivot columns ensures fast access, while modular query design supports reuse across documentation platforms.

Practical Applications and Best Practices
Implementing this query pattern accelerates content migration, cross-database synchronization, and report generation. Best practices include validating schema consistency, limiting result sets with pagination, and logging query performance metrics to identify bottlenecks.
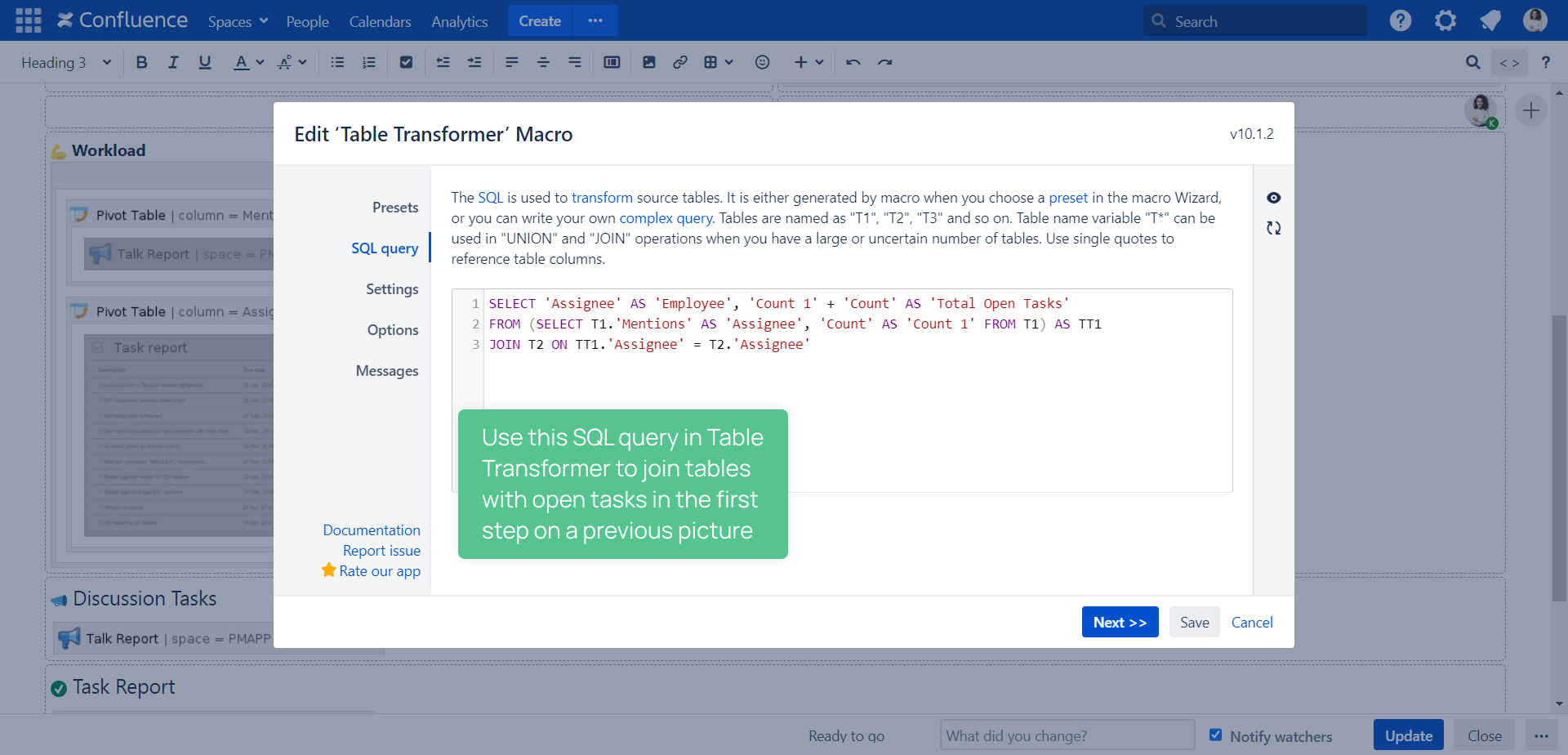
Conclusion: Boost Confluence Data Workflows with SQL Precision
Adopting the Confluence Table Transformer SQL Query transforms raw data into actionable insights with speed and reliability. Optimize your Confluence integrations today—experiment with query patterns, monitor results, and unlock new efficiencies in documentation management.