In today’s data-driven landscape, efficiently transforming structured and semi-structured data is critical for building robust AI models and analytics pipelines. The Table Transformer GitHub ecosystem offers powerful open-source tools that simplify the process of reshaping, cleaning, and converting tabular data for machine learning and business intelligence.
This section explores how developers and data scientists leverage Table Transformer GitHub projects to automate data transformation workflows. Key repositories include transformers for schema mapping, format conversion (CSV, JSON, SQL), and intelligent auto-syncing with dynamic source data. These tools eliminate manual data wrangling, reduce errors, and accelerate model training cycles.
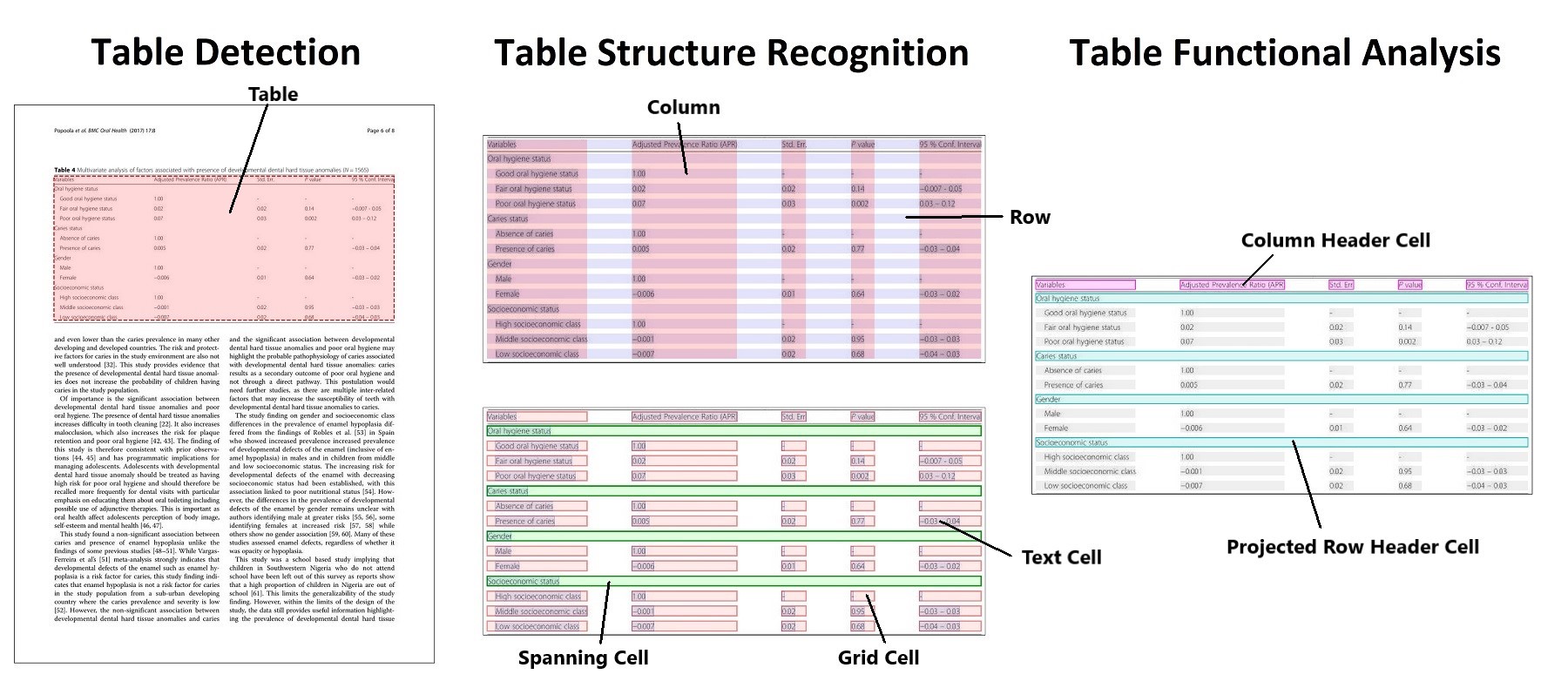
A standout feature in many Table Transformer GitHub projects is their support for custom pipelines—allowing users to define reusable transformation logic, integrate with cloud storage, and apply transformations in real time. Examples include auto-parsing heterogeneous datasets, normalizing values, and generating feature-engineered output tailored for ML frameworks.
For practitioners seeking to implement scalable data preparation, the Table Transformer GitHub offers a growing collection of tested, community-vetted solutions. Whether building internal data pipelines or powering AI dashboards, these open-source tools deliver flexibility, version control, and seamless integration with Python and cloud environments.

Conclusion: Harness the power of Table Transformer GitHub to streamline your data workflows, reduce development time, and enhance model accuracy. Start exploring top-tier open-source projects today and transform raw data into actionable insights with confidence.
Unlock the full potential of your data with Table Transformer GitHub—where open-source innovation meets practical data transformation. Start building smarter workflows today, reduce manual effort, and accelerate your AI initiatives with community-backed tools designed for real-world impact.
