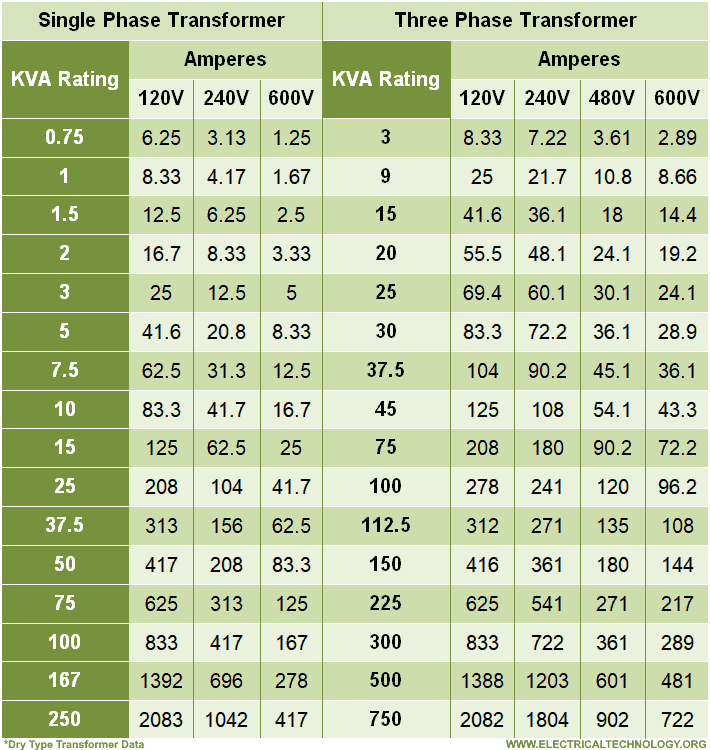
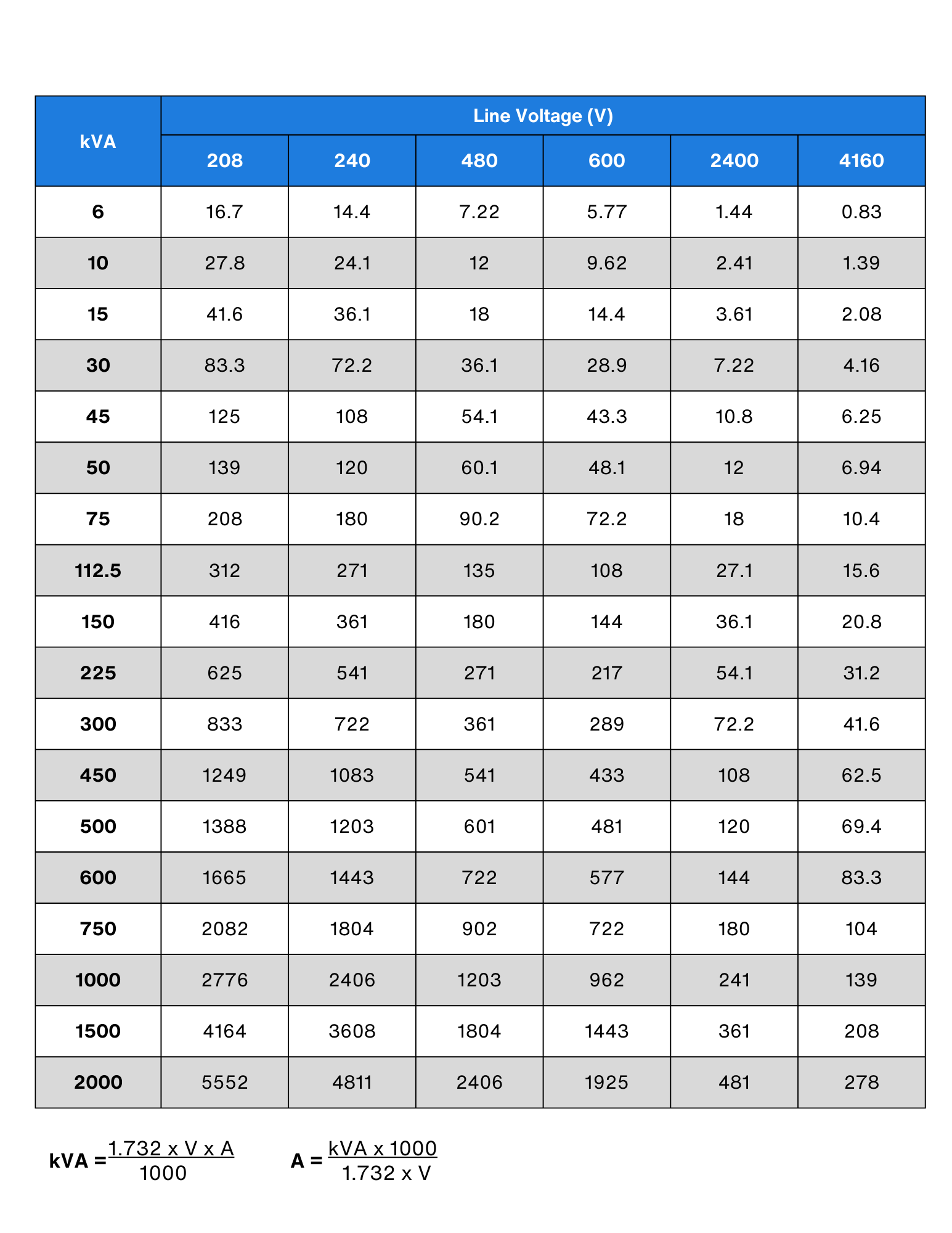
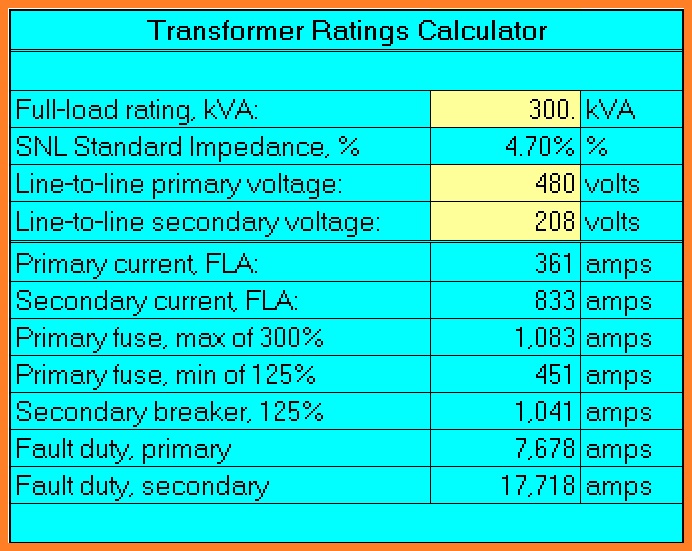
In the evolving landscape of artificial intelligence, understanding transformer architectures through precise calculation tables is crucial for optimizing model performance and efficiency.
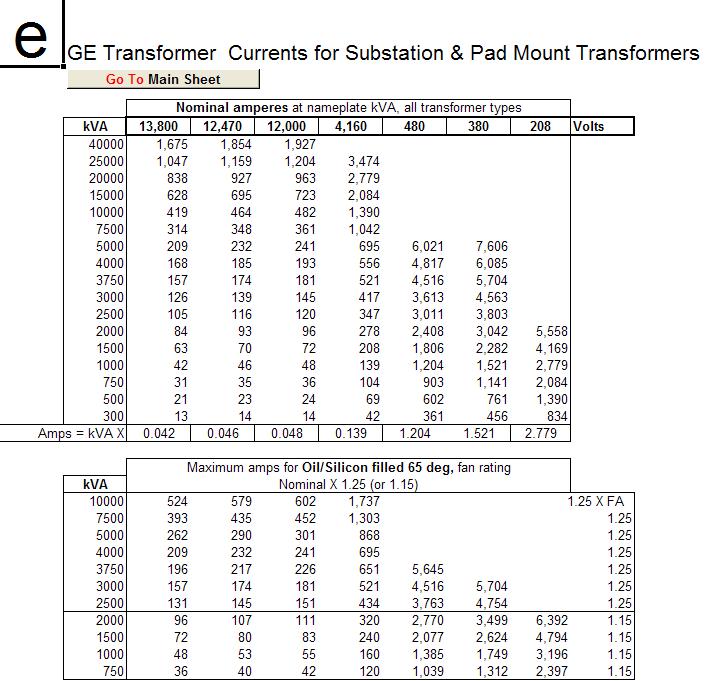
Transformer Calculation Table Overview
A transformer calculation table consolidates critical parameters such as the number of layers, attention heads per layer, hidden dimension size, and token processing capacity. This structured reference enables developers to benchmark and fine-tune models across tasks like translation, summarization, and sentiment analysis, ensuring maximum accuracy and resource efficiency.

Core Parameters Explained
The table typically includes layer depth, which impacts model depth and learning capacity; attention heads, determining parallel processing of input relationships; hidden size, affecting feature representation; and computational throughput, vital for real-time application deployment. Together, these metrics guide architectural decisions and performance expectations in production-grade transformers.
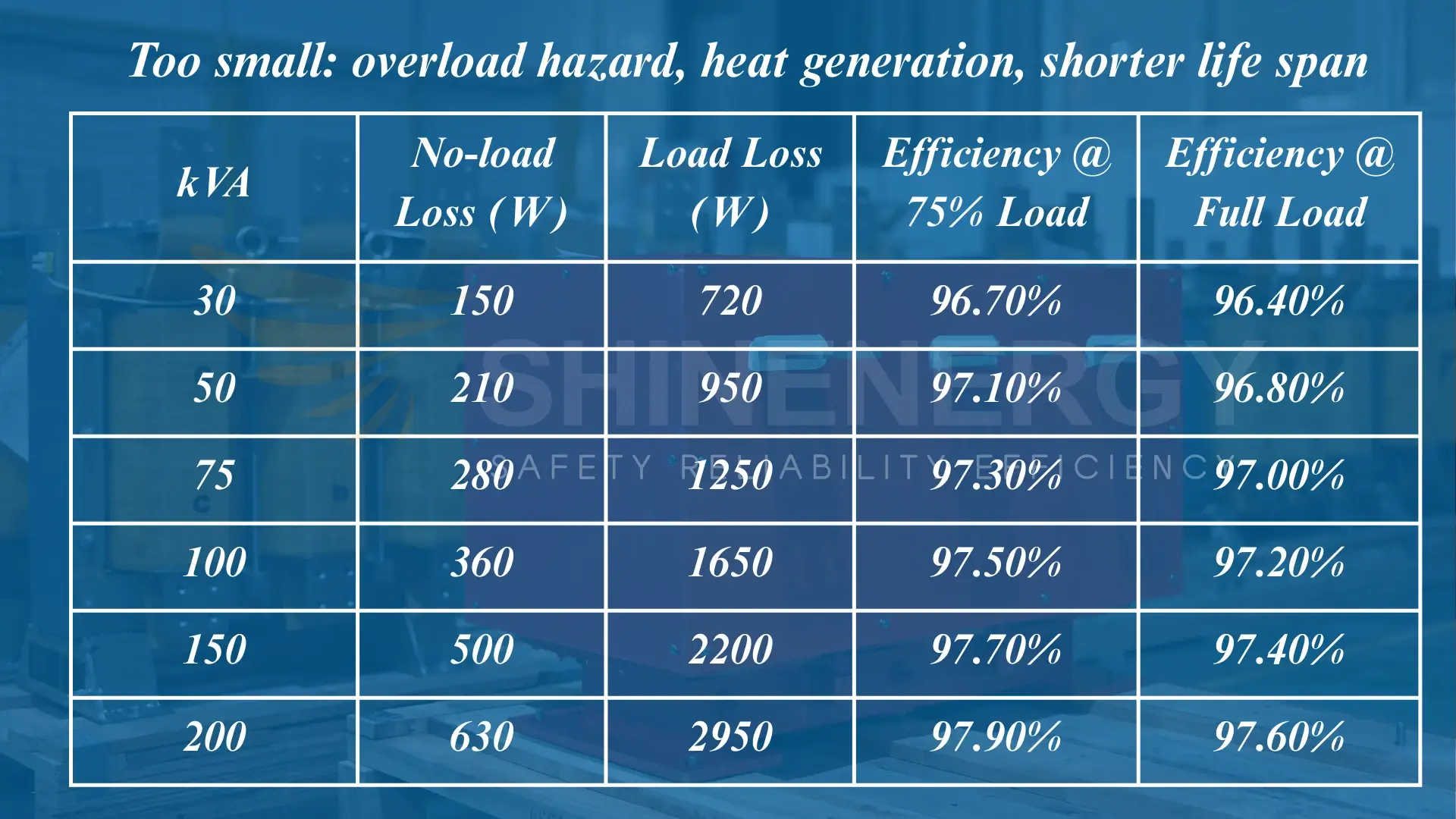
Practical Applications of the Calculation Table
Engineers and data scientists leverage this table during hyperparameter tuning, model selection, and scalability planning. By analyzing trade-offs between model size, inference speed, and accuracy—visualized through clear numerical benchmarks—teams can deploy optimized transformers tailored to specific use cases, from mobile NLP apps to large-scale enterprise systems.

Mastering the transformer calculation table empowers practitioners to build smarter, faster, and more efficient AI models. Use this resource to accelerate development, reduce trial-and-error, and achieve superior performance—start optimizing today for peak transformer intelligence.