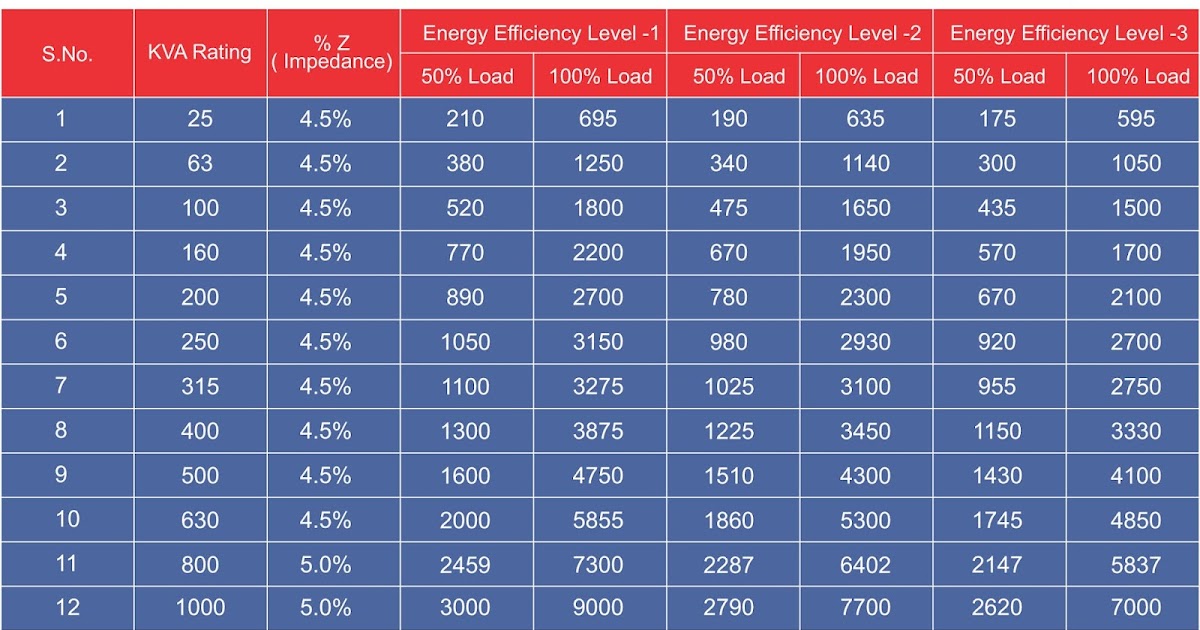
In modern natural language processing, understanding transformer losses is essential for optimizing model performance and training efficiency. This guide delivers a detailed transformer losses table to clarify common loss metrics and their roles in training.

Key Components in the Transformer Losses Table
The transformer losses table aggregates critical loss functions used during model training, including cross-entropy for classification, masked cross-entropy to prevent position leakage, and attention-based losses that refine token relevance. Each entry specifies mathematical formulation, use cases, and optimization implications, enabling developers to diagnose performance bottlenecks and tailor loss functions for specific tasks like machine translation or text summarization.

Common Loss Functions Explained
The transformer losses table typically includes cross-entropy loss—computed as the negative log-likelihood of predicted token probabilities against ground truth—essential for language modeling. Masked cross-entropy suppresses attention to future tokens during autoregressive generation, while perplexity and KL divergence metrics assess model calibration and uncertainty. These components collectively guide hyperparameter tuning and architecture refinement for state-of-the-art results.

Practical Application and Model Efficiency
By mapping loss trends in the transformer losses table, engineers identify underperforming layers, optimize learning rates, and mitigate overfitting. This data-driven approach accelerates convergence and ensures models achieve maximum accuracy with minimal computational overhead. Integrating loss visualization tools enhances transparency and enables precise adjustments during training cycles.
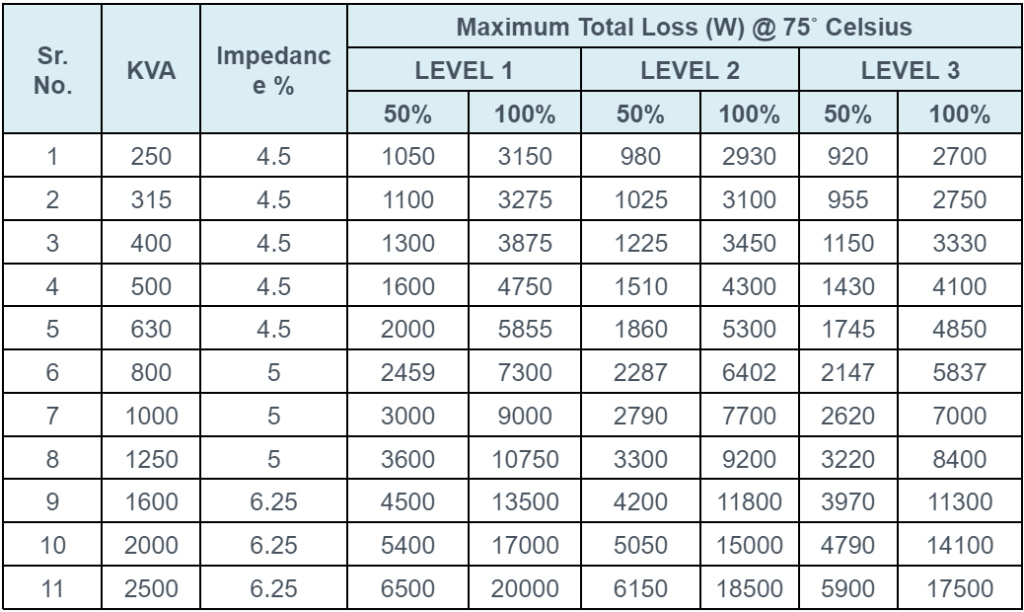
Conclusion and Call to Action
Mastering the transformer losses table empowers developers to fine-tune deep learning models with precision and confidence. Leverage this resource to optimize your NLP pipelines, reduce training time, and deliver superior performance. Begin optimizing your transformer models today—explore advanced loss combinations and training strategies to unlock peak efficiency.