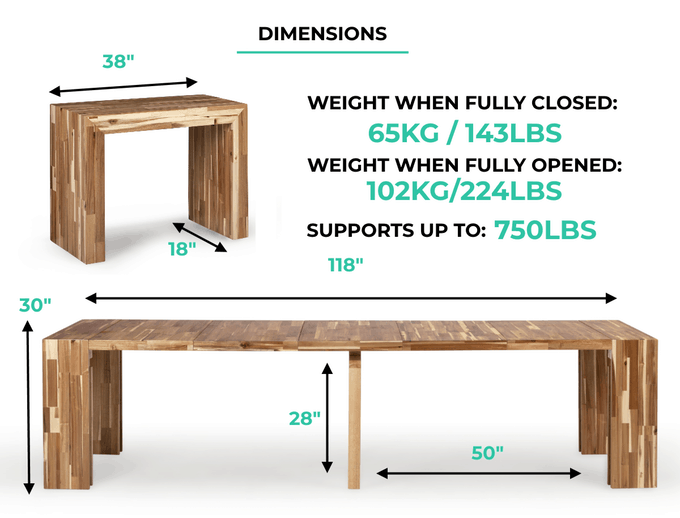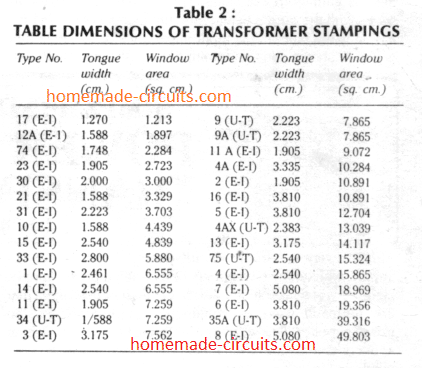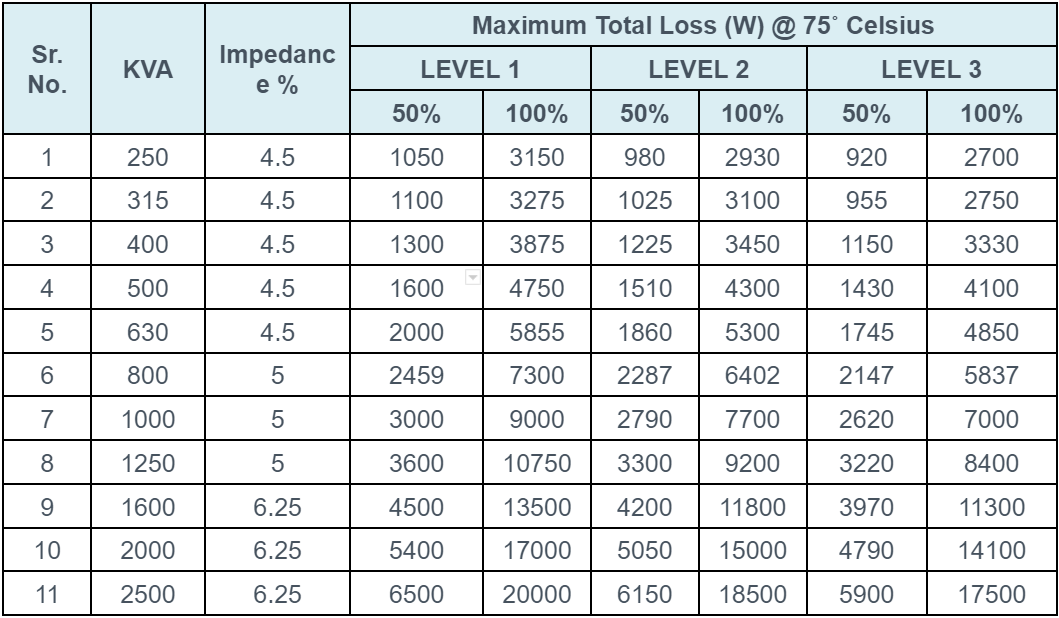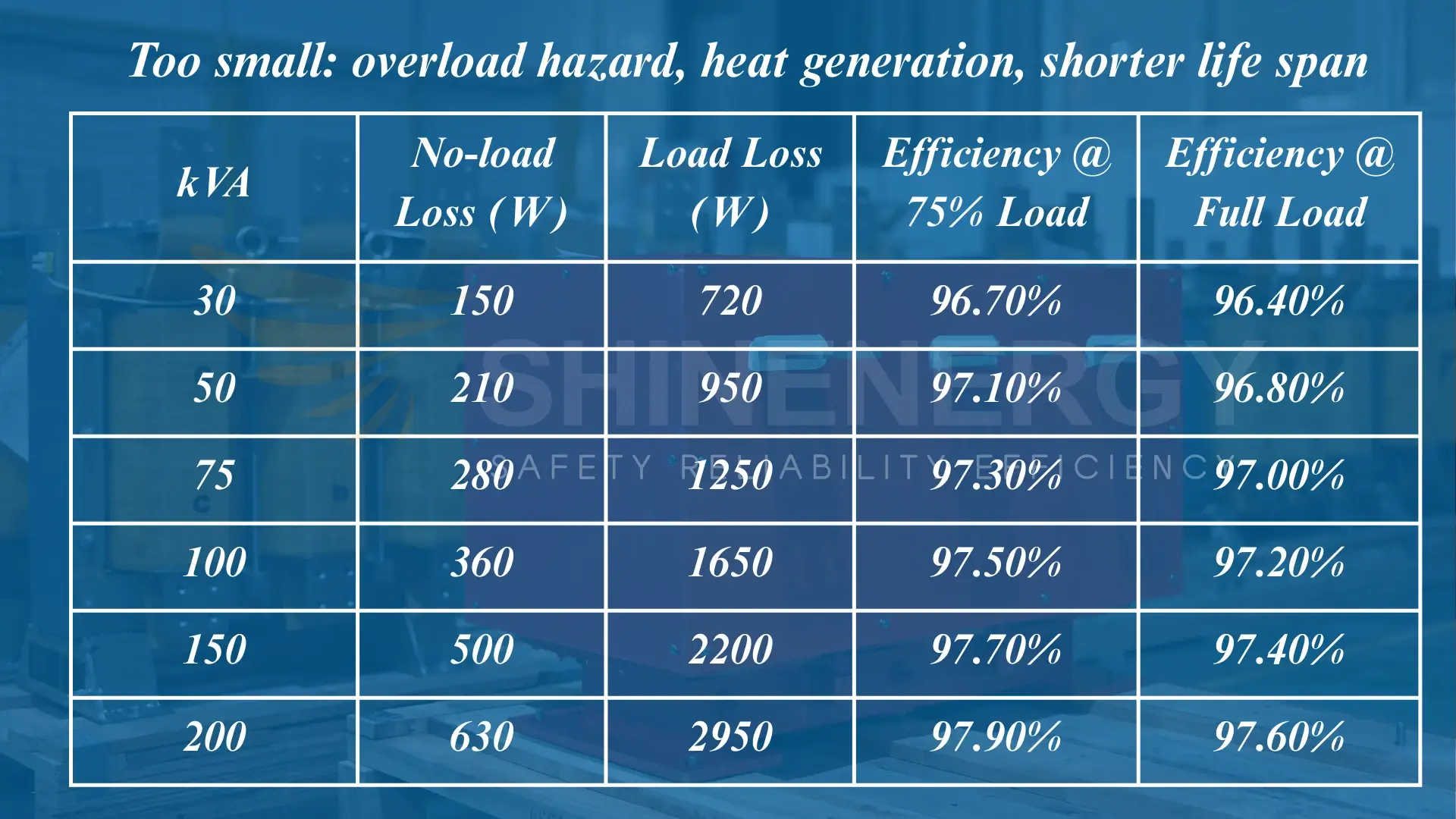
In modern AI applications, transformer table size—referring to the dimensionality and structural scale of model tables or attention matrices—plays a critical role in balancing performance and resource demands. Larger transformer tables enable deeper contextual understanding and improved accuracy, especially in language models processing complex queries. However, increased size directly affects memory consumption, inference speed, and deployment feasibility on edge devices. To optimize, developers must evaluate ideal table dimensions based on use case: smaller tables suit lightweight applications, while larger tables excel in high-precision scenarios. Techniques like quantization, pruning, and knowledge distillation help maintain efficiency without sacrificing model quality. Understanding transformer table size is essential for scaling AI solutions that are both powerful and practical.

Transformer table size variations influence how models handle attention mechanisms and parameter density. A larger table supports more nuanced relationships between input tokens, enhancing comprehension in tasks like translation or summarization. Yet, this comes at the cost of higher computational load and memory footprint. Conversely, compact tables reduce latency and deployment barriers but may limit contextual depth. Striking the right balance ensures models remain scalable across devices—from cloud servers to mobile platforms. Practical strategies include benchmarking different sizes, leveraging efficient architectures, and integrating hardware-aware optimizations.

Ultimately, selecting the optimal transformer table size requires aligning model capacity with real-world constraints. By prioritizing efficient design and adaptive scaling, teams can build AI systems that deliver peak performance while staying accessible and sustainable in production environments.