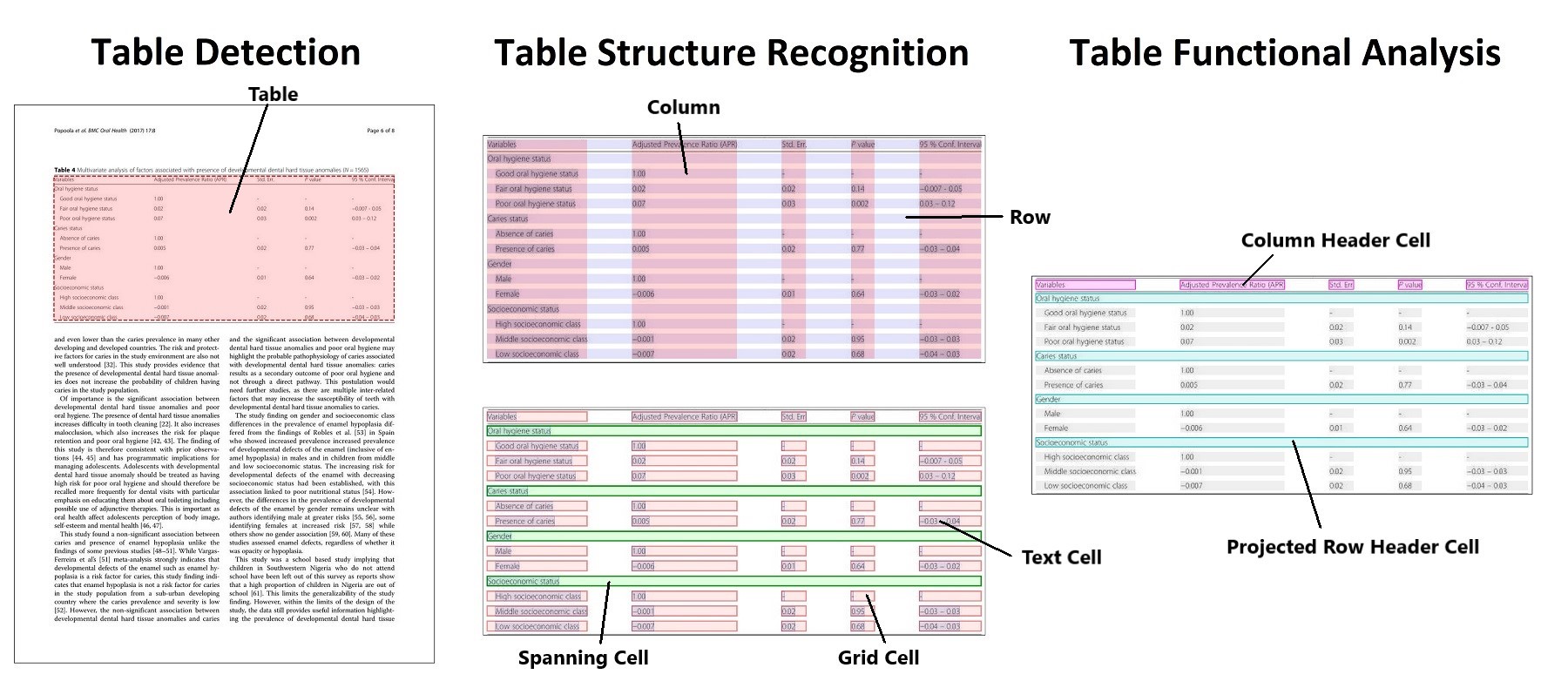
In the evolving landscape of artificial intelligence, transformer models have revolutionized natural language processing and beyond—but understanding the nuances between transformer tables and traditional transformers is critical for selecting the right tool. A transformer table typically refers to a structured, tabular implementation of transformer layers, emphasizing data organization and efficient matrix operations, ideal for tabular data like time-series or knowledge graphs. Traditional transformers, grounded in self-attention mechanisms, excel at sequential tasks such as text generation and translation. While both leverage encoder-decoder structures, transformer tables prioritize speed and scalability in structured data contexts, reducing memory overhead. In contrast, general transformers offer greater flexibility across diverse modalities. Choosing the right model depends on data type, task complexity, and performance needs. For structured datasets, transformer tables often outperform—delivering faster inference and optimized resource use—making them indispensable for modern AI applications. This distinction empowers developers and researchers to deploy smarter, more efficient solutions tailored to real-world demands.
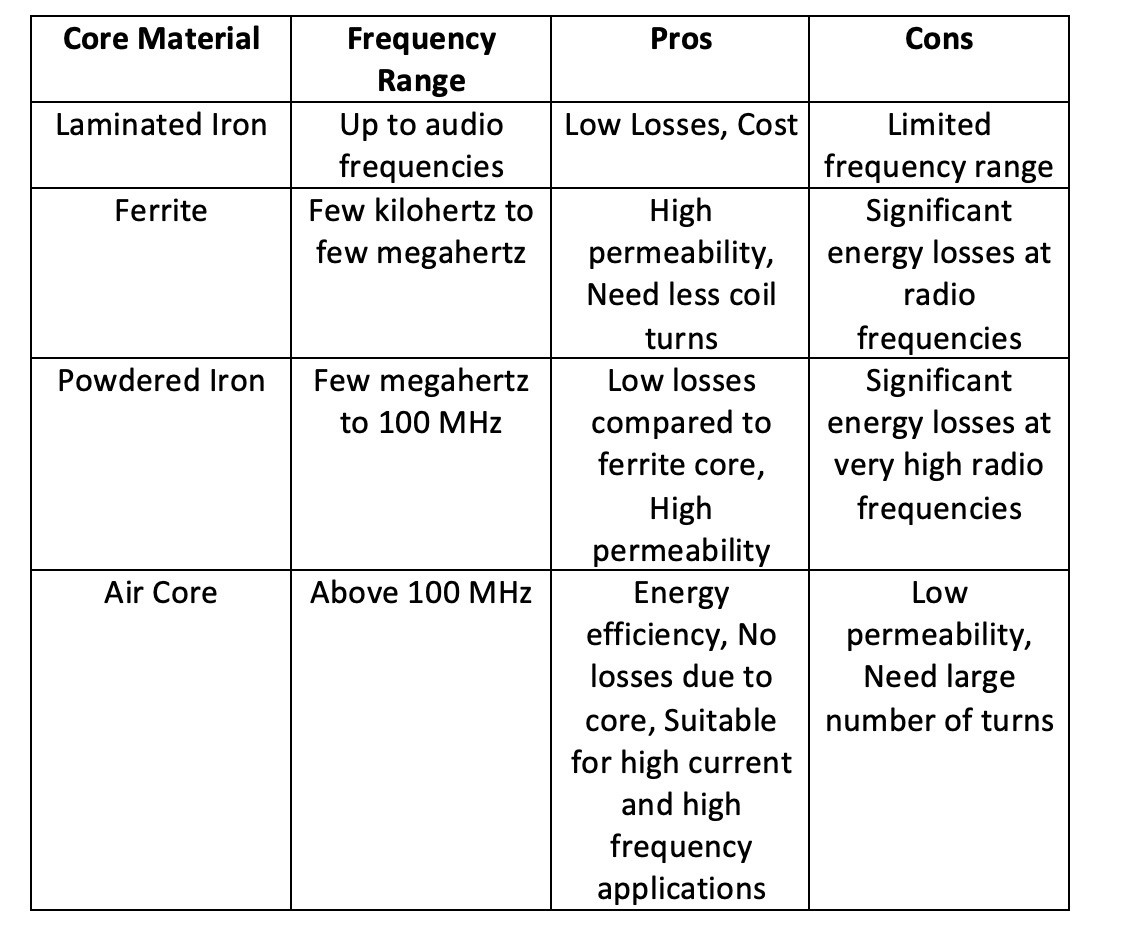
Choosing between transformer table and transformer depends on data nature and use case. For structured, tabular workloads, transformer tables deliver superior performance and efficiency. For dynamic, sequential tasks, traditional transformers remain unmatched. Understanding these differences empowers smarter AI design—so select wisely, test rigorously, and future-proof your models.