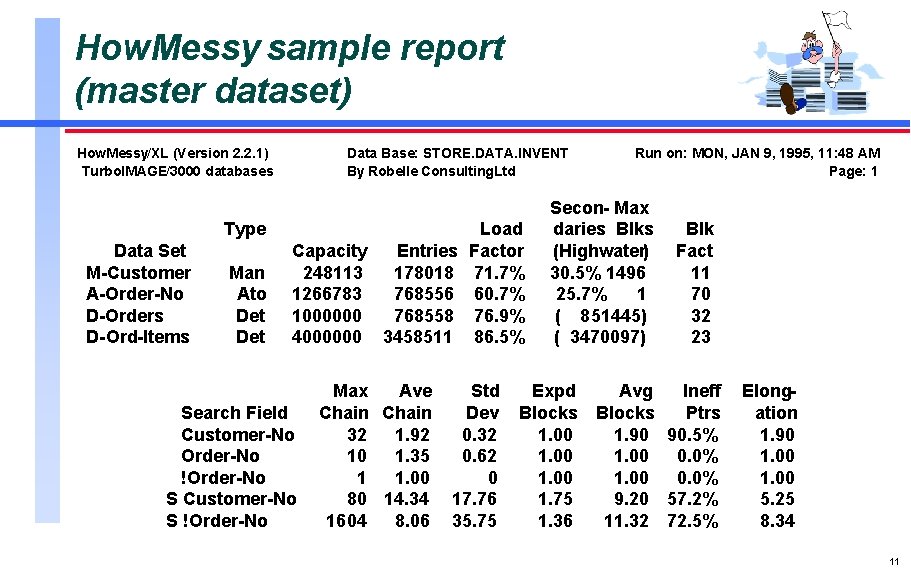
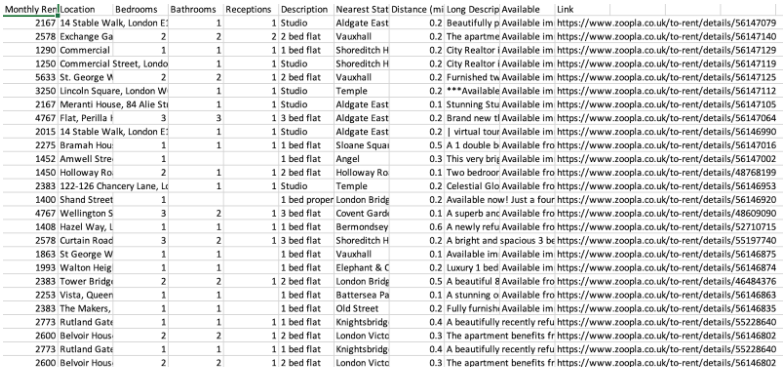
In today’s data-driven world, messy databases are not just common—they’re a silent productivity killer. The ultimate messy database embodies unstructured chaos that hinders analysis, slows operations, and breeds errors. Mastering its complexity is key to unlocking reliable insights.
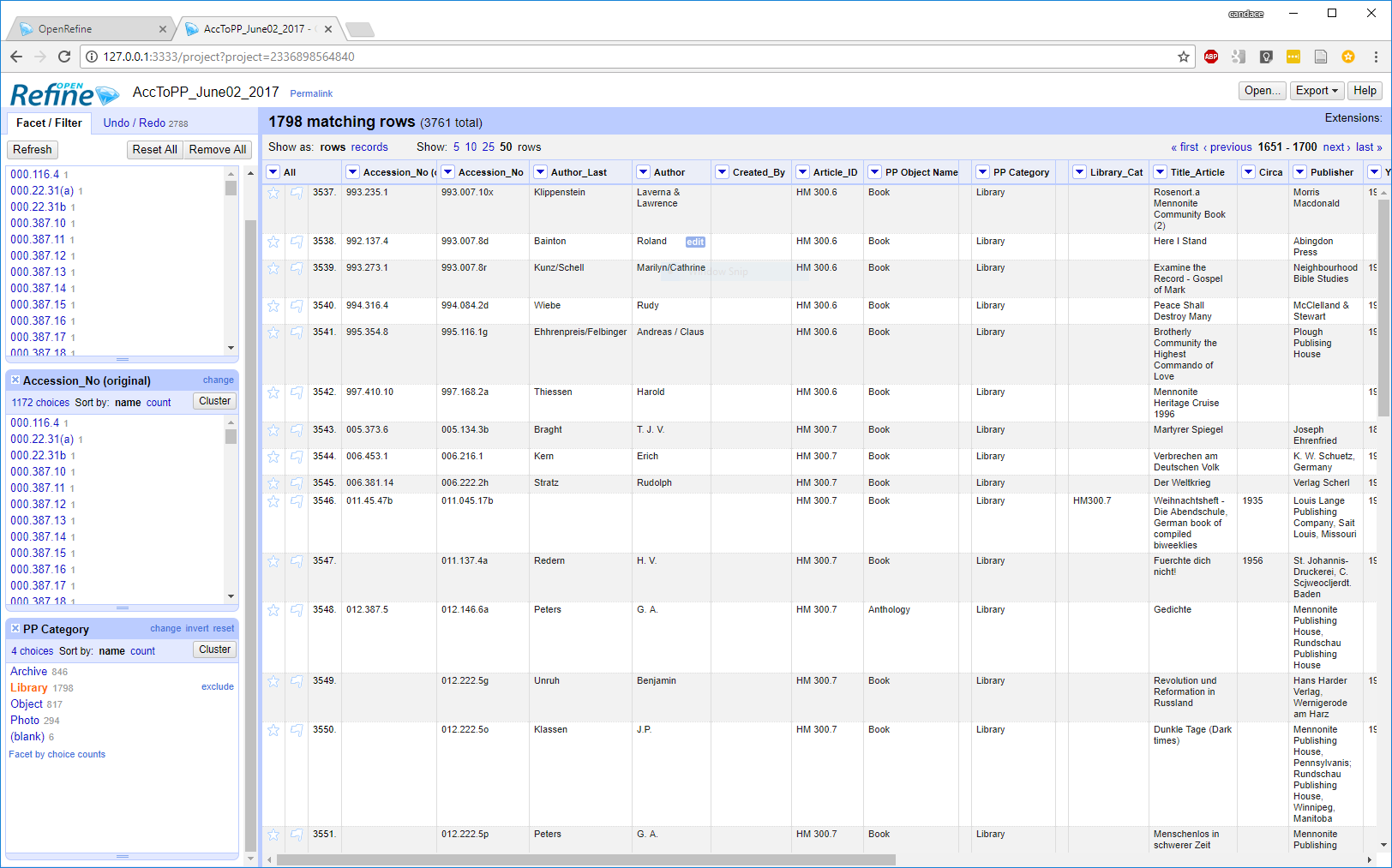
Understanding the Ultimate Messy Database
A messy database lacks consistent schema, contains duplicate or obsolete records, suffers from poor indexing, and often stores unvalidated user input. This disorder leads to unreliable queries, integration failures, and increased technical debt. Recognizing patterns—such as inconsistent naming, fragmented relationships, and corrupted entries—is the first step toward transformation.

Strategies to Clean and Organize
Overcoming messiness requires a structured approach: begin with comprehensive data audits to identify anomalies, apply normalization and deduplication techniques, enforce strict validation rules, and leverage automated ETL pipelines. Modern tools like schema validation frameworks and AI-driven cleansing platforms streamline cleanup, turning chaos into clean, actionable data.
Best Practices for Long-Term Data Health
Prevent future messiness by establishing clear data governance policies, enforcing consistent naming conventions, and scheduling regular maintenance cycles. Invest in training teams on data stewardship and adopt schema versioning. Pairing robust architecture with proactive oversight ensures lasting data integrity and scalability.

Taming the ultimate messy database is not a one-time fix—it’s a strategic commitment. By implementing disciplined cleaning, governance, and automation, organizations transform disarray into a powerful asset. Start today: audit, refine, and protect your data foundation for lasting success.