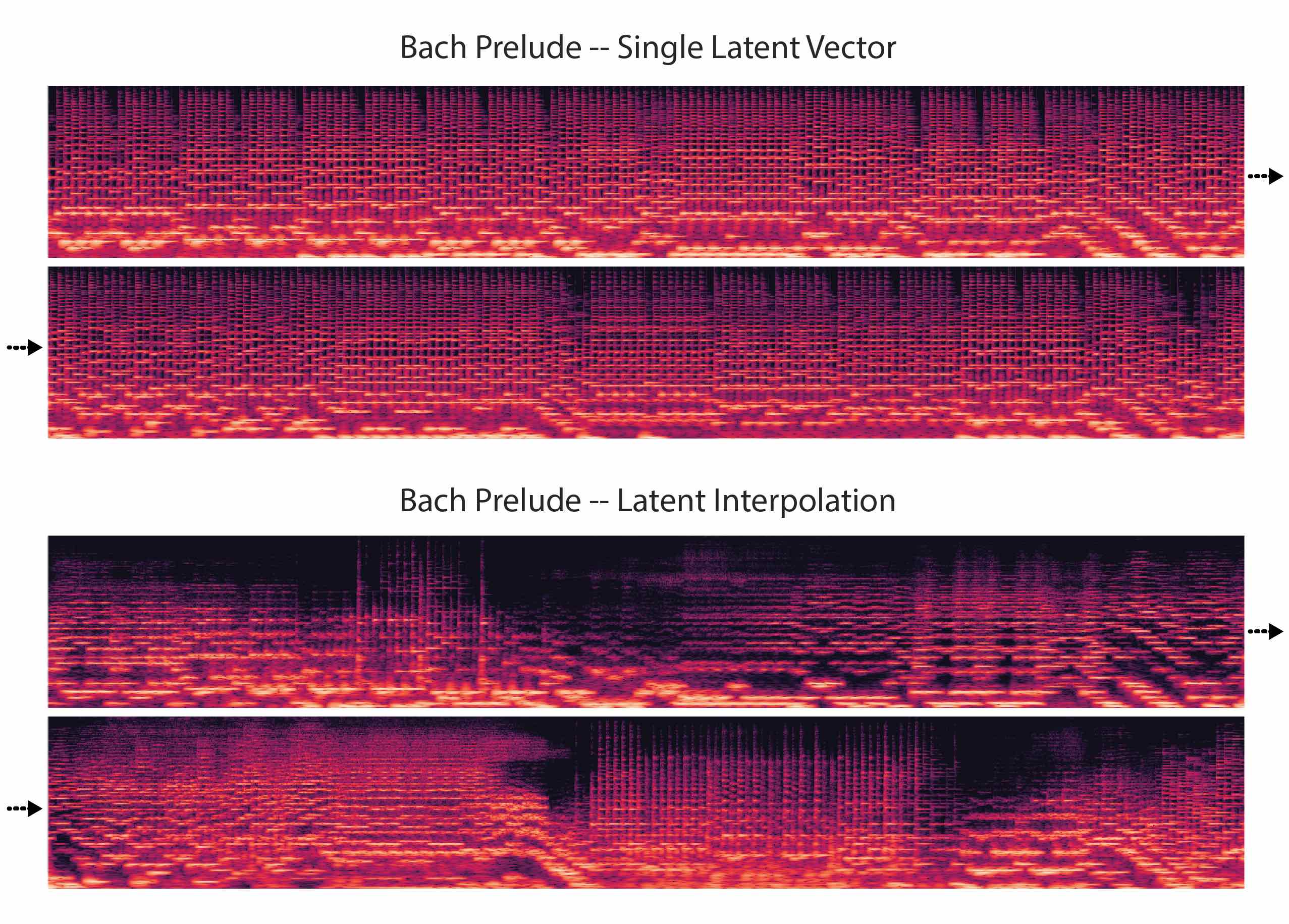
GANSynth learns to produce individual instrument notes like the NSynth Dataset. With pitch provided as a conditional attribute, the generator learns to use its latent space to represent different instrument timbres. This allows us to synthesize performances from MIDI files, either keeping the timbre constant, or interpolating between instruments over time.
| Consistent Timbre | Interpolation | |
| Bach's Prelude Suite No. 1 in G major MIDI | ||
We compare our best performing GANSynth models across a range of pitches with real samples and a pitch-conditional WaveNet and WaveGAN baselines. While the baselines are state-of-the-art, they have high bias and fail to capture the diversity of pitches and timbres in the dataset, while GANSynth produces high quality samples similar to the real data. To help qualitative evalution, we show models only trained on the subset of acoustic instruments. Samples were hand selected to try and best reflect the diversity and quality of samples from each model. Quantitative comparisons can be found in the paper.
| Real Data | GANSynth | WaveNet | WaveGAN |
|---|---|---|---|
| Pitch 36 | |||
| Pitch 48 | |||
| Pitch 60 | |||
| Pitch 72 | |||
| Pitch 84 | |||
We compare interpolations for GANSynth with a WaveNet Autoencoder from the original NSynth paper. Inital and target timbres are chosen from GANSynth samples because it lacks an encoder. GANSynth conditions on a single global latent vector, while the WaveNet AE uses a temporally-distributed latent code. This leads the GANSynth interpolations to all sound like reasonable instruments, as interpolations were seen during training, while the WaveNet AE wanders off the data manifold by mixing in time, leading to unrealistic sounds.
| Example 1 | Example 2 | ||
| Initial Timbre | Target Timbre | Initial Timbre | Target Timbre |
|---|---|---|---|
| GANSynth | WaveNet AE | GANSynth | WaveNet AE |

Since GANSynth uses global latent and pitch conditioning, it is possible to hold the latent vector fixed and maintain consistent timbre across a large range of pitches.
| Example 1 | Example 2 | Example 3 | Example 4 |
|---|---|---|---|
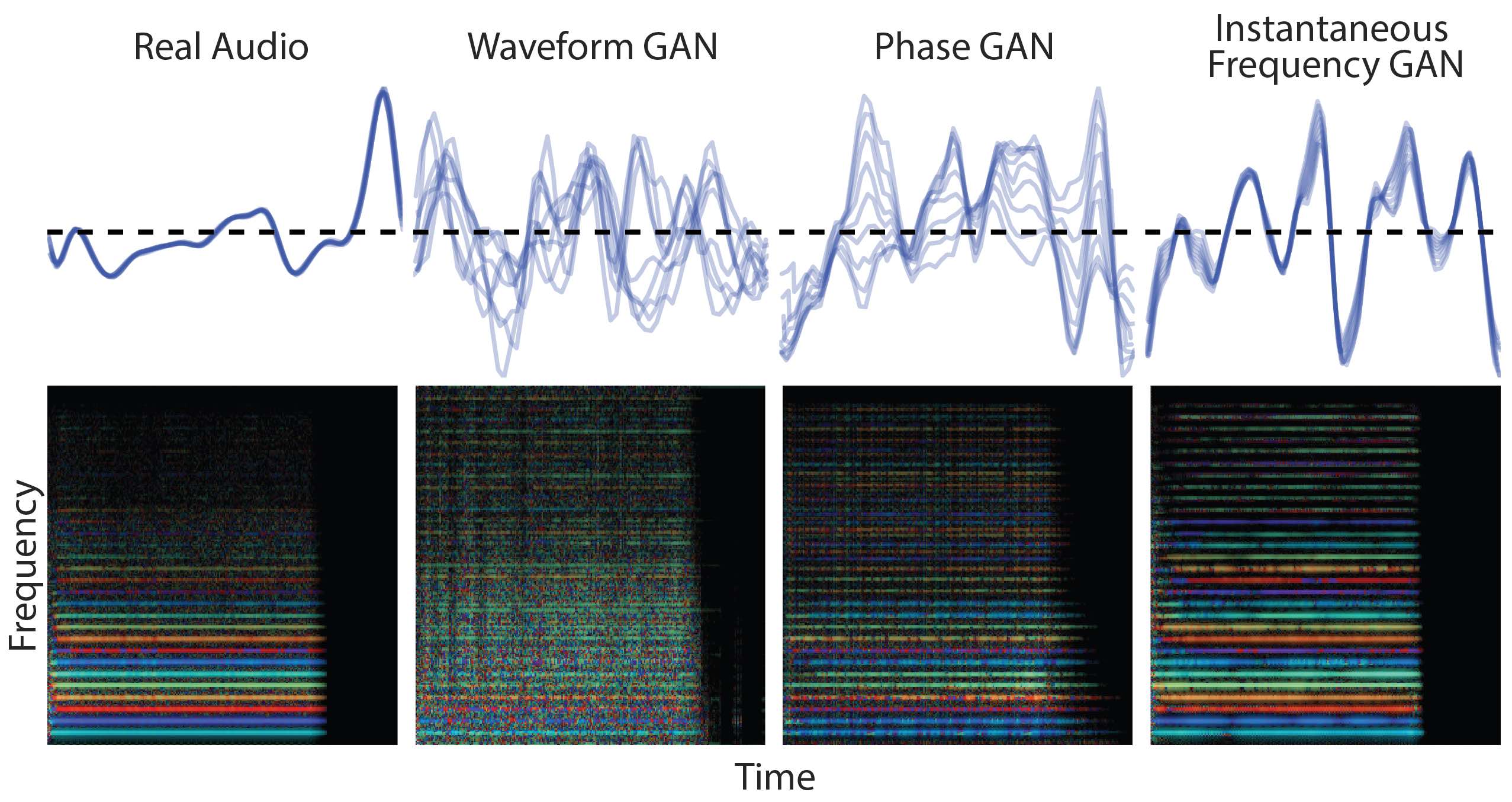
We generate audio using image-style GAN generators and discriminators. This approach works better for some audio representations than others. We experiment with mel scaling for spectrograms (Mel) instead of linear scaling, instantaneous frequency (IF) instead of raw phase (Phase), and increased frequency resolution (H) of the spectrograms. Quantiatively, each modification helps with the quality and diversity of genearted outputs, with instantaneous frequency helping the most for the highly periodic waveforms of musical instruments.
| IF + Mel + H | IF + Mel | IF | Phase |
|---|---|---|---|
| Pitch 36 | |||
| Pitch 48 | |||
| Pitch 60 | |||
| Pitch 72 | |||
| Pitch 84 | |||