

An ideal music synthesizer should be both interactive and expressive, generating high-fidelity audio in realtime for arbitrary combinations of instruments and notes. Recent neural synthesizers have exhibited a tradeoff between domain-specific models that offer detailed control of only specific instruments, or raw waveform models that can train on any music but with minimal control and slow generation. In this work, we focus on a middle ground of neural synthesizers that can generate audio from MIDI sequences with arbitrary combinations of instruments in realtime. This enables training on a wide range of transcription datasets with a single model, which in turn offers note-level control of composition and instrumentation across a wide range of instruments. We use a simple two-stage process: MIDI to spectrograms with an encoder-decoder Transformer, then spectrograms to audio with a generative adversarial network (GAN) spectrogram inverter. We compare training the decoder as an autoregressive model and as a Denoising Diffusion Probabilistic Model (DDPM) and find that the DDPM approach is superior both qualitatively and as measured by audio reconstruction and Fréchet distance metrics. Given the interactivity and generality of this approach, we find this to be a promising first step towards interactive and expressive neural synthesis for arbitrary combinations of instruments and notes.
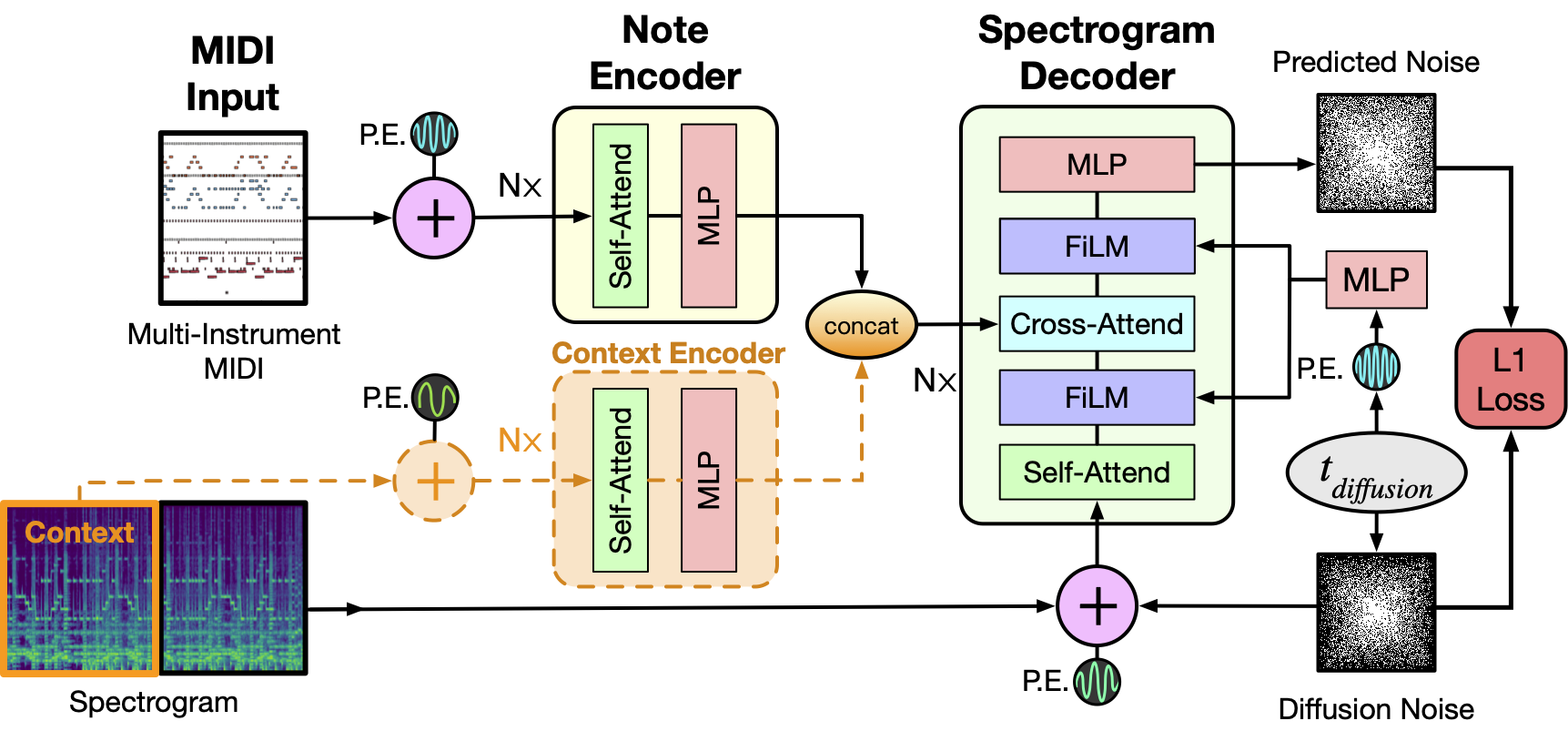
The model architecture is based on a T5-style encoder-decoder Transformer that takes a sequence of note events as input and outputs a spectrogram. We train the decoder stack as a Denoising Diffusion Probabilistic Model (DDPM), where the model learns to iteratively refine Gaussian noise into a target spectrogram. In order to condition decoder output on the diffusion noise time step, we add two FiLM layers before and after the cross-attention block. To keep compute and memory requirements reasonable, we generate ~5 second spectrogram segments, and to ensure a smooth transition between these segments we encode the previously generated segment in a second encoder stack. The outputs of the encoder stacks are concatenated together before being fed into the decoder cross-attend.
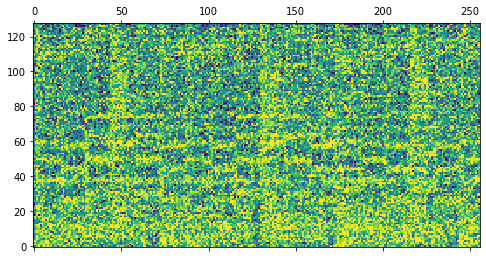
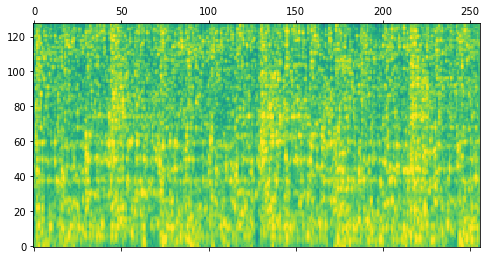
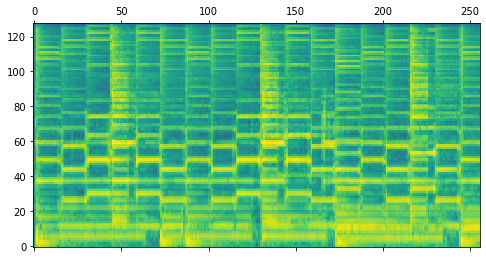
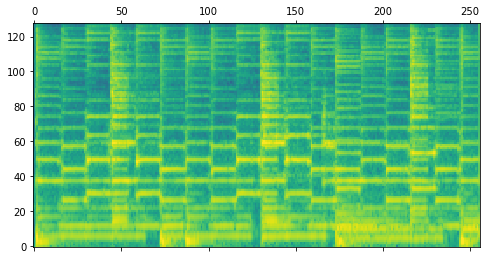
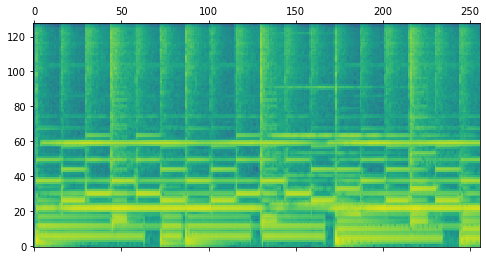
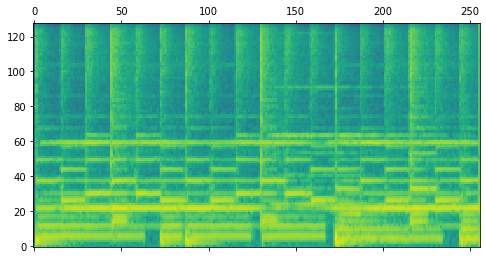
Our decoder stack is trained as a Denoising Diffusion Probabilistic Model (DDPM). The model starts with Gaussian noise as input and is trained to iteratively refine that noise toward a target, conditioned on a sequence of note events and the spectrogram of the previously rendered segment. The following table illustrates this diffusion process for one example segment.
Note that the audio version of the first few steps can sound quite harsh, so you might want to turn down the volume before listening.
| Step | Model Output | Audio after Spectrogram Inversion |
| 1000 | |
|
| 750 | |
|
| 500 | |
|
| 250 | |
|
| 0 | |
|
| Target | |
|
As an example of the flexibility of the model, here is an example of rendering an "out of domain" MIDI file not from any of the training datasets. For these examples, we use a MIDI file of the "Allegro moderato" movement from Beethoven's "Trio for piano, violin and cello in E-flat major, WoO. 38".
Original orchestration:
Swapped piano and cello parts:
Electric piano, trumpet, and oboe:
Here we show the same MIDI inputs (from the Slakh2100 validation set) rendered by each of the models.
Here are several example outputs from our "Base with Context" model. All examples were conditioned on MIDI drawn from either the test or validation (when test was not available) splits.
Ground Truth Encoded is the ground truth for these MIDI outputs encoded by the spectrogram inverter and represents an upper bound on output quality. Ground Truth Raw is the unprocessed target audio.
| Datasets from recorded audio | ||||
| Dataset | Description | MIDI Synthesis | Ground Truth Encoded | Ground Truth Raw |
| MAESTROv3 | Solo piano | |||
| MusicNet | Orchestral | |||
| URMP | Orchestral | |||
| Guitarset | Solo guitar | |||
| Datasets from synthetic audio | ||||
| Dataset | Description | MIDI Synthesis | Ground Truth | Ground Truth Raw |
| Slakh | Multi-instrument | |||
| Cerberus4 | Multi-instrument | |||