
Gene set and pathway#
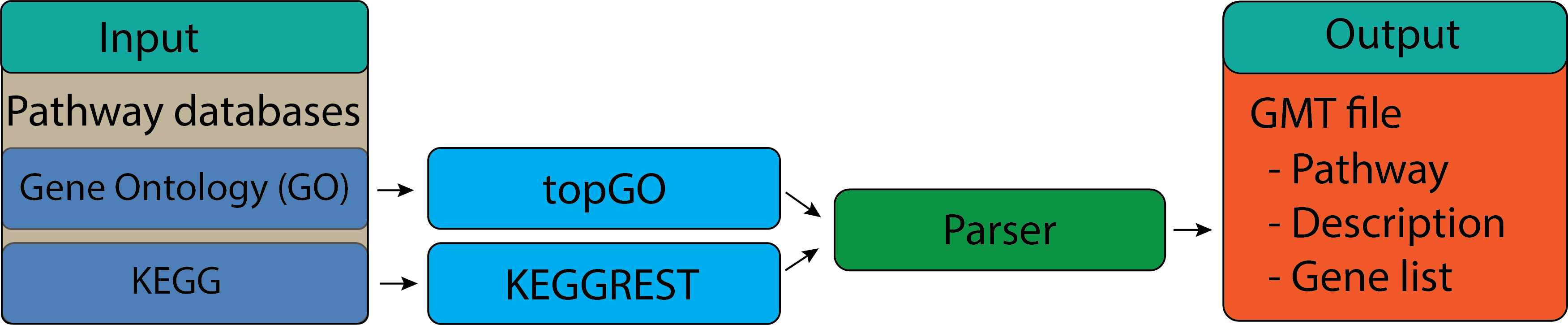
Differential expression (DE) analysis typically yields a list of genes or proteins. Our intention is to use such lists to gain novel insights about genes and proteins that may have roles in a given phenomenon, phenotype or disease progression. However, in many cases, gene lists generated from DE analysis are difficult to interpret due to their large size and lack of useful annotations. Hence, pathway analysis (also known as gene set analysis or over-representation analysis), aims to reduce the complexity of interpreting gene lists via mapping the listed genes to known (i.e. annotated) biological pathways, processes and functions. This learning submodule introduces common curated biological databases including Gene Ontology (GO) and the Kyoto Encyclopedia of Genes and Genomes (KEGG).
Learning Objectives:#
Introduction to Ontology and Gene Ontology.
Introduction to KEGG Pathway Database.
Download terms, pathway gene set from GO and KEGG.
Save results to GMT file format.
Ontology and Gene Ontology#
Overview#
In this section we will learn about the concept of gene ontology in Bioinformatics. Ontology is set of concepts and categories defined by a shared vocabulary to denote properties of the concepts, as well as the relationships between the concepts. Ontology plays an important role in the field of bioinformatics. Ontology enables unambiguous communication e.g., a way to understand different groups’ annotations of various genomes. Also, it allows the knowledge to be structured to perform automated analyses by computer programs.
The Gene Ontology (GO) database defines a structured, common, and controlled vocabulary to describe attributes of genes and gene products across organisms. Collaboration is key to build a consensus vocabulary. But the term gene ontology, or GO, is commonly used to refer to both the terms as well as the associations between genes, which is sometimes a source of potential confusion. In order to avoid this, here we will use the term “GO” to describe the set of terms and their hierarchical structure and “GO annotations” to describe the set of associations between genes and GO terms. The GO is divided into three categories to describe the genes and gene products from three different angles: Molecular Function, Biological Process, and Cellular Component.
The structure of GO can be described in terms of into directed acyclic graphs (DAGs), where each GO term is a node, and the relationships between the terms are edges between the nodes. GO is loosely hierarchical, with ‘child’ terms being more specialized than their ‘parent’ terms, but unlike a strict hierarchy, a term may have more than one parent term (note that the parent/child model does not hold true for all types of relations). The structure of the controlled vocabularies are intended to reflect true, biological relationships. In contrast to strict hierarchies, DAGS allow multiple relationships between a more granular (child) term and a more general parent term. The relationship between terms affects how queries are made. For example,a query for all genes with binding activity would include transcription factors as well as genes with other types of binding activity (such as protein binding, ligand binding). The illustration of category and structure of GO is shown in the figure below:
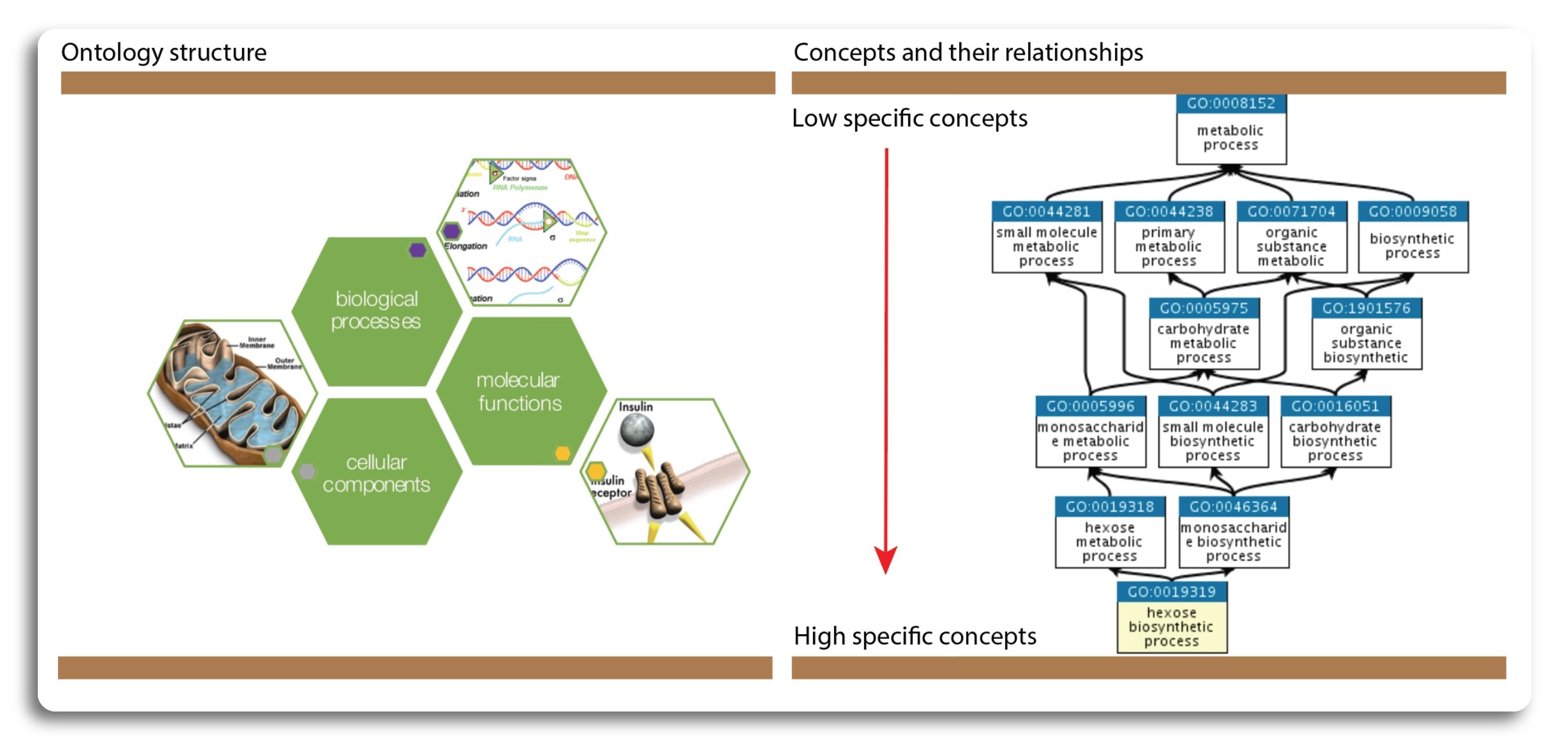 (Source: https://www.ebi.ac.uk/, http://geneontology.org/)
(Source: https://www.ebi.ac.uk/, http://geneontology.org/)
Gene ontology relationship#
In DAGs graph, terms are represented as nodes and relations (also known as object properties) between the terms are edges. There are commonly used relationships in GO such as is a (is a subtype of), part of, has part, regulates, negatively regulates and positively regulates. All terms (except from the root terms representing each aspect) have a sub-class relationship to another terms.
Examples:
The is a relation forms the basic structure of GO. If we say A is a B, we mean that node A is a subtype of node B
The part of relation is used to represent part-whole relationships. A part of relation would only be added between A and B if B is necessarily part of A: wherever B exists, it is as part of A, and the presence of the B implies the presence of A. However, given the occurrence of A, we cannot say for certain that B exists.
A relation that describes case in which one process directly affects the manifestation of another process or quality, i.e. the former regulates the latter.
A more specific case with more nodes and edges can be seen at the figure below:
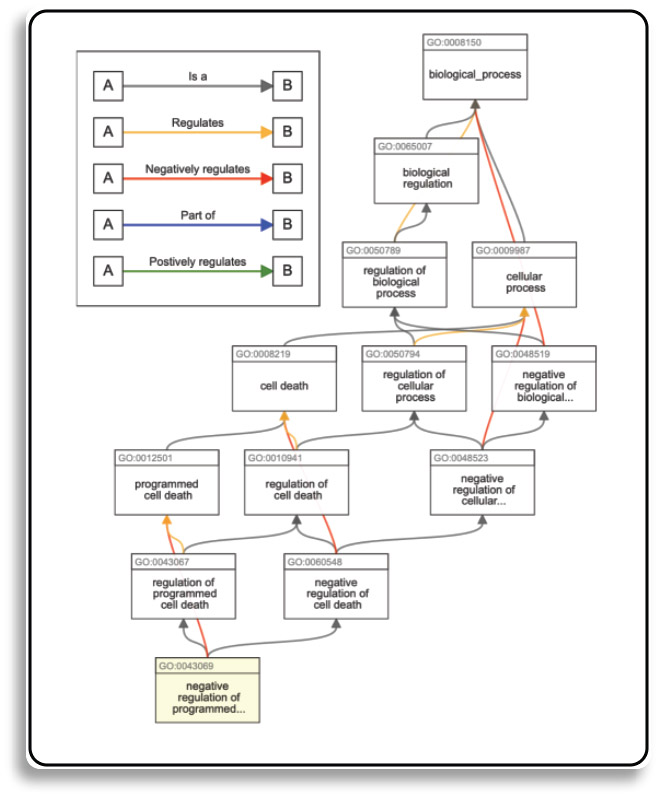 (Source: https://advaitabio.com/)
(Source: https://advaitabio.com/)
For more technical information about relations and their properties used in GO and other ontologies see the
OBO Relations Ontology (RO)
GO storage file formats#
GO terms are updated monthly in the following formats:
OBO 1.4 files are human-readable (in addition to machine-readable) and can be opened in any text editor.
OWL files can be read by Protégé text editor.
In this learning submodule, we will only use “.OBO” to obtain GO terms.The OBO file format is for representing ontologies and controlled vocabularies. The format itself attempts to achieve the following goals:
Human readability
Ease of parsing
Extensibility
Minimal redundancy
The file structure can is shown in the following figure.
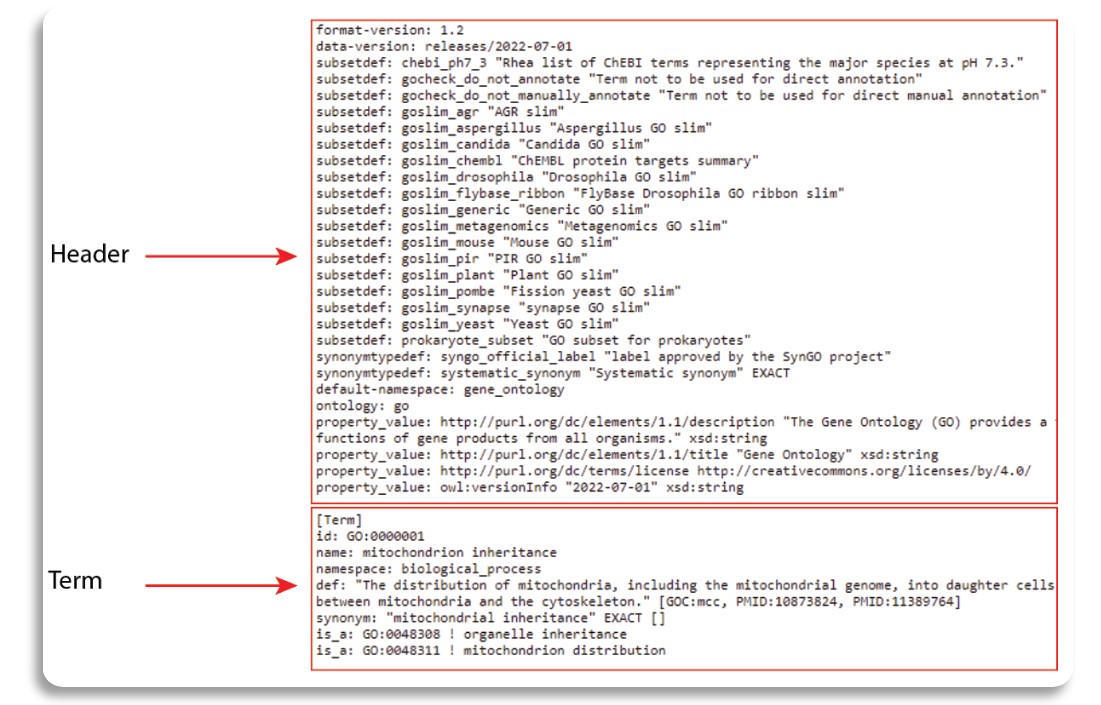
The OBO file has a header, which is an unlabeled section at the beginning of the document. The header ends when the first term is encountered. Next, term is represented in labeled section with the tag [Term]. Under each term, we can find other information such as term ID, official name, category (namespace), term definition, synonym and relation to other GO terms.
At this step, we still don’t know what genes are related to which GO terms. In order to retrieve custom sets of gene ontology annotations for any list of genes from organisms, NCBI has published a Gene2GO database that obtain GO terms and the entrez gene ids related to those go terms. The database can be retrieve from here text editor. The Gene2GO database can be viewed using text editor, the file structure is presented in the figure below:
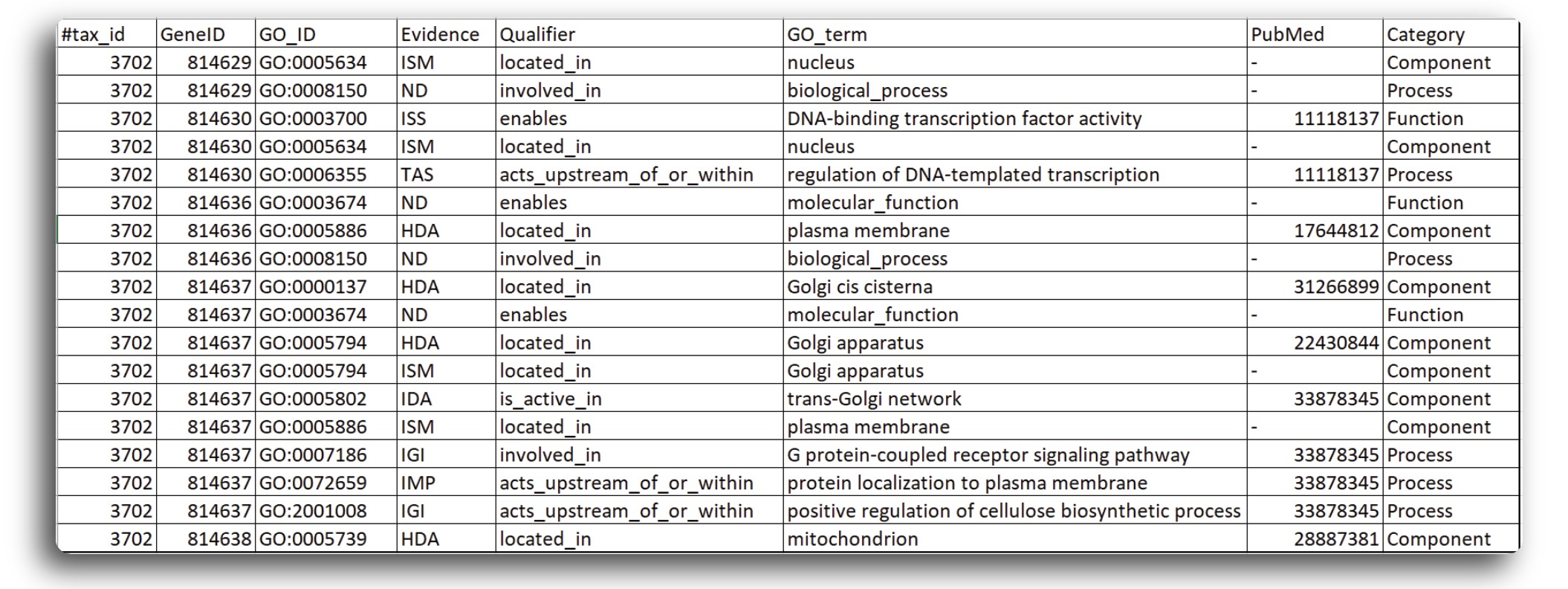
The OBO and Gene2GO databases will be used in combination to obtain GO term and related genes for enrichment analysis.
Retrieving GO terms from DE gene list#
This section focuses on downloading related GO terms based on the DE genelist obtained from the DE analysis in the previous section.
Here, we will use topGO and hgu133plus2.db R packages to obtain GO terms. The topGO package has built-in functions that use Gene2GO databases to retrieve GO terms from the gene ID give by DE analysis. Since the dataset we used in submodule 02 was generated for human, we will use hgu133plus2.db database to map probeIDs to gene symbols.
The installation process of two package can be done by the script below:
# Installation of topGO and hgu133plus2.db package
suppressMessages({if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
suppressWarnings(BiocManager::install("topGO", update = F))
suppressWarnings(BiocManager::install("hgu133plus2.db", update = F))
suppressWarnings(BiocManager::install("AnnotationDbi", update = F))
})
# Loading the library
suppressPackageStartupMessages({
suppressWarnings(library("topGO"))
suppressWarnings(library("hgu133plus2.db"))
suppressWarnings(library("AnnotationDbi"))
})
groupGOTerms: GOBPTerm, GOMFTerm, GOCCTerm environments built.
Load the DE genelist generated from the DE analysis using limma.
# Loading the DE result
data = readRDS("./data/DE_genes.rds")
By default, the DE analysis performed by limma contains multiple features. However, adjusted p-value and gene ID are the most important features for enrichment analysis. We can use the following code to list of gene IDs and their p-value.
# Get p-value from DE results
genelist <- data$adj.P.Val
# Assign gene IDs to associated p-values
names(genelist) <- data$PROBEID
After successfully obtaining the genelist, we need to map the gene IDs to the gene symbols using hgu133plus2.db.
# Map gene IDs to gene symbols
gene <- suppressMessages(AnnotationDbi::select(hgu133plus2.db, names(genelist), "SYMBOL"))
# Remove duplicated gene IDs
gene <- gene[!duplicated(gene[,1]),]
# Assign result to a new genlist with gene symbols
geneList2 <- genelist
names(geneList2) <- gene[,2]
Now, we can search for related GO terms based on the new gene list using topGO package. First, we need to create a topGOdata
object.
# Retrieve all the GO terms related to the genelist obtained from the expression matrix
GOdata <- new("topGOdata", description = "",ontology = "BP",
allGenes = geneList2, geneSel = function(x)x, nodeSize = 10,
annot = annFUN.org, ID = "alias", mapping = "org.Hs.eg")
Building most specific GOs .....
( 12457 GO terms found. )
Build GO DAG topology ..........
( 15840 GO terms and 35901 relations. )
Annotating nodes ...............
( 16332 genes annotated to the GO terms. )
We can search for related GO terms using geneInTerm function and view the term with associated genes.
# Obtain a list of genes for each GO term
allGO = genesInTerm(GOdata)
allGO[1:5]
- $`GO:0000002`
-
- 'AKT3'
- 'DNA2'
- 'DNAJA3'
- 'ENDOG'
- 'FLCN'
- 'LIG3'
- 'LONP1'
- 'MDP1'
- 'MEF2A'
- 'METTL4'
- 'MGME1'
- 'MPV17'
- 'OPA1'
- 'PARP1'
- 'PIF1'
- 'PIM1'
- 'POLB'
- 'POLG'
- 'POLG2'
- 'PPARGC1A'
- 'PRIMPOL'
- 'RRM1'
- 'RRM2B'
- 'SESN2'
- 'SLC25A33'
- 'SLC25A36'
- 'SLC25A4'
- 'SSBP1'
- 'STOML2'
- 'STOX1'
- 'TOP3A'
- 'TP53'
- 'TWNK'
- 'TYMP'
- $`GO:0000003`
-
- 'A1CF'
- 'A2M'
- 'AAAS'
- 'ABAT'
- 'ABCC8'
- 'ABHD2'
- 'ACE'
- 'ACE2'
- 'ACOD1'
- 'ACOX1'
- 'ACR'
- 'ACRBP'
- 'ACRV1'
- 'ACSBG1'
- 'ACSBG2'
- 'ACSL4'
- 'ACTL7A'
- 'ACTL9'
- 'ACTR2'
- 'ACTR3'
- 'ACVR1'
- 'ACVR1B'
- 'ACVR1C'
- 'ACVR2A'
- 'ADA'
- 'ADAD1'
- 'ADAD2'
- 'ADAM15'
- 'ADAM18'
- 'ADAM2'
- 'ADAM20'
- 'ADAM21'
- 'ADAM28'
- 'ADAM29'
- 'ADAM32'
- 'ADAM5'
- 'ADAMTS1'
- 'ADAMTS16'
- 'ADAMTS2'
- 'ADCY10'
- 'ADCY3'
- 'ADCY7'
- 'ADCYAP1'
- 'ADCYAP1R1'
- 'ADGRG1'
- 'ADGRG2'
- 'ADIG'
- 'ADM'
- 'ADNP'
- 'ADRA2A'
- 'ADRA2B'
- 'AFF4'
- 'AFP'
- 'AGFG1'
- 'AGO2'
- 'AGO4'
- 'AGRP'
- 'AGT'
- 'AKAP3'
- 'AKAP4'
- 'AKR1C3'
- 'AKT1'
- 'ALDOA'
- 'ALKBH5'
- 'ALOX15B'
- 'ALPL'
- 'AMBP'
- 'AMD1'
- 'AMH'
- 'AMHR2'
- 'ANAPC1'
- 'ANAPC10'
- 'ANAPC11'
- 'ANAPC13'
- 'ANAPC15'
- 'ANAPC16'
- 'ANAPC2'
- 'ANAPC4'
- 'ANAPC5'
- 'ANAPC7'
- 'ANG'
- 'ANGPT2'
- 'ANKLE1'
- 'ANKRD31'
- 'ANKRD49'
- 'ANTXR1'
- 'ANXA1'
- 'AP3B1'
- 'APC2'
- 'APELA'
- 'APLF'
- 'APOB'
- 'APOL2'
- 'APOL3'
- 'APP'
- 'AQP4'
- 'AR'
- 'AREG'
- 'ARG1'
- 'ARHGDIB'
- 'ARID4A'
- 'ARID4B'
- 'ARID5B'
- 'ARMC12'
- 'ARMC2'
- 'ARRB2'
- 'ASB1'
- 'ASF1B'
- 'ASH1L'
- 'ASPM'
- 'ASZ1'
- 'ATAT1'
- 'ATM'
- 'ATN1'
- 'ATP1A1'
- 'ATP1A4'
- 'ATP2B2'
- 'ATP2B4'
- 'ATP7A'
- 'ATP8B3'
- 'ATR'
- 'ATRX'
- 'AURKA'
- 'AURKC'
- 'AVP'
- 'AVPR1A'
- 'AXL'
- 'AZI2'
- 'AZIN2'
- 'B4GALNT1'
- 'B4GALT1'
- 'BACH1'
- 'BAD'
- 'BAG6'
- 'BAK1'
- 'BAP1'
- 'BASP1'
- 'BAX'
- 'BBS1'
- 'BBS2'
- 'BBS4'
- 'BCAP31'
- 'BCL2'
- 'BCL2L1'
- 'BCL2L10'
- 'BCL2L11'
- 'BCL2L2'
- 'BCL6'
- 'BIK'
- 'BIRC3'
- 'BMAL1'
- 'BMP15'
- 'BMP4'
- 'BMP5'
- 'BMP6'
- 'BMP7'
- 'BMPR1A'
- 'BMPR1B'
- 'BMPR2'
- 'BNC1'
- 'BOK'
- 'BOLL'
- 'BPY2'
- 'BRCA2'
- 'BRD2'
- 'BRDT'
- 'BRINP1'
- 'BRIP1'
- 'BRME1'
- 'BSG'
- 'BTBD18'
- 'BUB1'
- 'BUB1B'
- 'BUB3'
- 'C11orf80'
- 'C14orf39'
- 'C16orf92'
- 'C1QBP'
- 'C2CD6'
- 'C3'
- 'C3orf62'
- 'C9orf24'
- 'CABS1'
- 'CABYR'
- 'CACNA1H'
- 'CACNA1I'
- 'CAD'
- 'CADM1'
- 'CALCA'
- 'CALR'
- 'CALR3'
- 'CAPN2'
- 'CASP2'
- 'CASP3'
- 'CASP8'
- 'CATSPER1'
- 'CATSPER2'
- 'CATSPER3'
- 'CATSPERB'
- 'CATSPERD'
- ⋯
- 'TBC1D21'
- 'TBPL1'
- 'TBX3'
- 'TCF21'
- 'TCFL5'
- 'TCP1'
- 'TCP11'
- 'TCTE1'
- 'TDRD1'
- 'TDRD10'
- 'TDRD12'
- 'TDRD5'
- 'TDRD6'
- 'TDRD7'
- 'TDRD9'
- 'TDRKH'
- 'TDRP'
- 'TEAD3'
- 'TEAD4'
- 'TEKT2'
- 'TEKT3'
- 'TEP1'
- 'TERB1'
- 'TERB2'
- 'TERF1'
- 'TESC'
- 'TESK1'
- 'TESK2'
- 'TESMIN'
- 'TEX101'
- 'TEX11'
- 'TEX12'
- 'TEX14'
- 'TEX15'
- 'TEX19'
- 'TEX43'
- 'TFAP2C'
- 'TFPT'
- 'TGFB2'
- 'TGFB3'
- 'TGFBR1'
- 'TGFBR2'
- 'TGS1'
- 'TH'
- 'THBD'
- 'THEG'
- 'THRA'
- 'THRB'
- 'TIAL1'
- 'TIFAB'
- 'TIMP1'
- 'TIMP4'
- 'TIPARP'
- 'TLE6'
- 'TLR3'
- 'TLR9'
- 'TMED2'
- 'TMEM119'
- 'TMEM203'
- 'TMEM95'
- 'TMF1'
- 'TMPRSS12'
- 'TNC'
- 'TNFAIP6'
- 'TNFSF10'
- 'TNP1'
- 'TNP2'
- 'TOB2'
- 'TOP2A'
- 'TOP2B'
- 'TOP3A'
- 'TP63'
- 'TPGS1'
- 'TPPP2'
- 'TPPP3'
- 'TRAC'
- 'TRIM27'
- 'TRIM28'
- 'TRIM36'
- 'TRIP13'
- 'TRO'
- 'TRPC3'
- 'TRPC6'
- 'TRPC7'
- 'TRPM2'
- 'TSGA10'
- 'TSNAX'
- 'TSNAXIP1'
- 'TSPAN8'
- 'TSPY1'
- 'TSSK1B'
- 'TSSK2'
- 'TSSK3'
- 'TSSK4'
- 'TSSK6'
- 'TTC12'
- 'TTC21A'
- 'TTC26'
- 'TTF1'
- 'TTK'
- 'TTLL1'
- 'TTLL3'
- 'TTLL9'
- 'TUBG1'
- 'TUBG2'
- 'TUBGCP2'
- 'TUBGCP3'
- 'TUBGCP4'
- 'TUBGCP5'
- 'TUBGCP6'
- 'TUT4'
- 'TUT7'
- 'TXNDC2'
- 'TXNDC8'
- 'TXNRD3'
- 'TYRO3'
- 'UBAP2L'
- 'UBB'
- 'UBE2B'
- 'UBE2J1'
- 'UBE2Q1'
- 'UBE3A'
- 'UBR2'
- 'UBXN8'
- 'UCHL1'
- 'UCN'
- 'UCP2'
- 'UMODL1'
- 'UMPS'
- 'UNC13B'
- 'UNC5C'
- 'USP42'
- 'USP9X'
- 'USP9Y'
- 'UTF1'
- 'UTP14C'
- 'VDAC2'
- 'VDR'
- 'VEGFA'
- 'VGF'
- 'VIP'
- 'VIPAS39'
- 'VMP1'
- 'VPS13A'
- 'VPS13B'
- 'VPS54'
- 'WASHC5'
- 'WBP2NL'
- 'WDR19'
- 'WDR33'
- 'WDR48'
- 'WDR77'
- 'WFDC2'
- 'WIPF3'
- 'WNT2B'
- 'WNT3'
- 'WNT4'
- 'WNT5A'
- 'WNT7A'
- 'WNT9B'
- 'WT1'
- 'XDH'
- 'XKRY'
- 'XRCC2'
- 'XRN2'
- 'YBX2'
- 'YBX3'
- 'YTHDC1'
- 'YTHDC2'
- 'YTHDF2'
- 'YTHDF3'
- 'YY1'
- 'ZAN'
- 'ZBTB16'
- 'ZCWPW1'
- 'ZFP41'
- 'ZFP42'
- 'ZFPM2'
- 'ZFY'
- 'ZGLP1'
- 'ZMIZ1'
- 'ZMYND15'
- 'ZNF148'
- 'ZNF225'
- 'ZNF296'
- 'ZNF318'
- 'ZNF32'
- 'ZNF35'
- 'ZNF449'
- 'ZNF541'
- 'ZNF628'
- 'ZNF830'
- 'ZP1'
- 'ZP2'
- 'ZP4'
- 'ZPBP'
- 'ZPBP2'
- 'ZSCAN2'
- 'ZSCAN21'
- 'ZW10'
- $`GO:0000012`
-
- 'APLF'
- 'APTX'
- 'ERCC6'
- 'ERCC8'
- 'LIG4'
- 'PARP1'
- 'SIRT1'
- 'TDP1'
- 'TERF2'
- 'TNP1'
- 'XNDC1N'
- 'XRCC1'
- $`GO:0000018`
-
- 'ACTB'
- 'ACTL6A'
- 'ACTR2'
- 'ALYREF'
- 'ANKLE1'
- 'APLF'
- 'ARID2'
- 'ATAD5'
- 'BCL6'
- 'BLM'
- 'BRD8'
- 'CD28'
- 'CD40'
- 'CFL1'
- 'CGAS'
- 'CHEK1'
- 'CLC'
- 'CLCF1'
- 'DMAP1'
- 'EAF2'
- 'EP400'
- 'EPC1'
- 'EPC2'
- 'ERCC2'
- 'ERCC6'
- 'EXOSC3'
- 'EXOSC6'
- 'FANCB'
- 'FBH1'
- 'FIGNL1'
- 'FOXP3'
- 'FUS'
- 'H1-0'
- 'H1-1'
- 'H1-10'
- 'H1-2'
- 'H1-3'
- 'H1-4'
- 'H1-5'
- 'H1-6'
- 'H1-8'
- 'H1-9P'
- 'HDGFL2'
- 'HELB'
- 'HELQ'
- 'HMCES'
- 'IL10'
- 'IL2'
- 'IL27RA'
- 'IL4'
- 'IL7R'
- 'ING2'
- 'ING3'
- 'KAT5'
- 'KDM1A'
- 'KHDC3L'
- 'KLHL15'
- 'KMT5B'
- 'KMT5C'
- 'KPNA1'
- 'KPNA2'
- 'MAD2L2'
- 'MAGEF1'
- 'MBTD1'
- 'MEAF6'
- 'MLH1'
- 'MMS19'
- 'MORF4L1'
- 'MORF4L2'
- 'MRE11'
- 'MRGBP'
- 'MRNIP'
- 'MSH2'
- 'MSH3'
- 'MSH6'
- 'NDFIP1'
- 'NSD2'
- 'OOEP'
- 'PARP1'
- 'PARP3'
- 'PARPBP'
- 'PAXIP1'
- 'PIAS4'
- 'POGZ'
- 'POLQ'
- 'PPP4C'
- 'PPP4R2'
- 'PRDM7'
- 'PRDM9'
- 'PTPRC'
- 'RAD50'
- 'RAD51'
- 'RAD51AP1'
- 'RADX'
- 'RBBP8'
- 'RECQL5'
- 'RIF1'
- 'RMI2'
- 'RPA2'
- 'RTEL1'
- 'RUVBL1'
- 'RUVBL2'
- 'SETD2'
- 'SHLD1'
- 'SHLD2'
- 'SIRT6'
- 'SLC15A4'
- 'SMAP2'
- 'SMARCAD1'
- 'SMCHD1'
- 'SPIDR'
- 'STAT6'
- 'SUPT6H'
- 'TBX21'
- 'TERF2'
- 'TERF2IP'
- 'TEX15'
- 'TFRC'
- 'TGFB1'
- 'THOC1'
- 'TIMELESS'
- 'TNFSF13'
- 'TNFSF4'
- 'TP53BP1'
- 'TRRAP'
- 'UBE2B'
- 'UBQLN4'
- 'USP51'
- 'VPS72'
- 'WAS'
- 'WDR48'
- 'WRAP53'
- 'YEATS4'
- 'ZCWPW1'
- 'ZNF365'
- 'ZRANB3'
- 'ZSCAN4'
- $`GO:0000022`
-
- 'AURKB'
- 'AURKC'
- 'BIRC5'
- 'CDCA8'
- 'INCENP'
- 'KIF23'
- 'KIF4A'
- 'MAP10'
- 'NUMA1'
- 'PRC1'
- 'RACGAP1'
Now, we already had GO terms with genes. However, we still do not know the meaning of GO terms related to biological process. We can use GO.db database to get a set of annotation maps describing the entire Gene Ontology assembled using data from GO. We can use the following code to install the GO.db R package.
suppressMessages({if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
suppressWarnings(BiocManager::install("GO.db", update = F))
})
library(GO.db)
Then, we can use the following command to obtain the GO terms description.
# Getting the name of each GO term
terms <- names(allGO)
# Getting the description of each GO term
descriptions <-lapply(Term(terms), `[[`, 1)
In order to perform enrichment analysis in later submodules, we need to save the GO terms and genesets to the standard output. One commonly used format is Gene Matrix Transposed file format (*.gmt). The GMT file format is a tab delimited file format that describes gene sets. In the GMT format, each row represents a gene set; in the GMX format, each column represents a gene set. Here, we can save GO terms and genesets to the *.gmt using the following function:
# A function to save the GO terms with geneset to the local repository
writeGMT <- function(genesets, descriptions, outfile) {
if (file.exists(outfile)) {
file.remove(outfile)
}
for (gs in names(genesets)) {
write(c(gs, gsub("\t", " ", descriptions[[gs]]), genesets[[gs]]), file=outfile, sep="\t", append=TRUE, ncolumns=length(genesets[[gs]]) + 2)
}
}
outfile <- "./data/GO_terms.gmt"
writeGMT(allGO, descriptions, outfile)
Tip: Saving data to the Google Cloud Bucket
gsutil cp ./data/GO_terms.gmt gs://cpa-output
Kyoto Encyclopedia of Genes and Genomes (KEGG)#
Overview#
KEGG is a collection of databases dealing with genomes, biological pathways, diseases, drugs, and chemical substances. KEGG is utilized for bioinformatics research and education, including data analysis in genomics, metagenomics, metabolomics and other omics studies, modeling and simulation in systems biology, and translational research in drug development. The KEGG database project was initiated in 1995 by Minoru Kanehisa, professor at the Institute for Chemical Research, Kyoto University, under the then ongoing Japanese Human Genome Program. Foreseeing the need for a computerized resource that can be used for biological interpretation of genome sequence data, he started developing the KEGG PATHWAY database. It is a collection of manually drawn KEGG pathway maps representing experimental knowledge on metabolism and various other functions of the cell and the organism. Each pathway map contains a network of molecular interactions and reactions and is designed to link genes in the genome to gene products (mostly proteins) in the pathway. This has enabled the analysis called KEGG pathway mapping, whereby the gene content in the genome is compared with the KEGG PATHWAY database to examine which pathways and associated functions are likely to be encoded in the genome. KEGG is a “computer representation” of the biological system. It integrates building blocks and wiring diagrams of the system—more specifically, genetic building blocks of genes and proteins, chemical building blocks of small molecules and reactions, and wiring diagrams of molecular interaction and reaction networks. The illustrative structure of KEGG is presented as figure below.
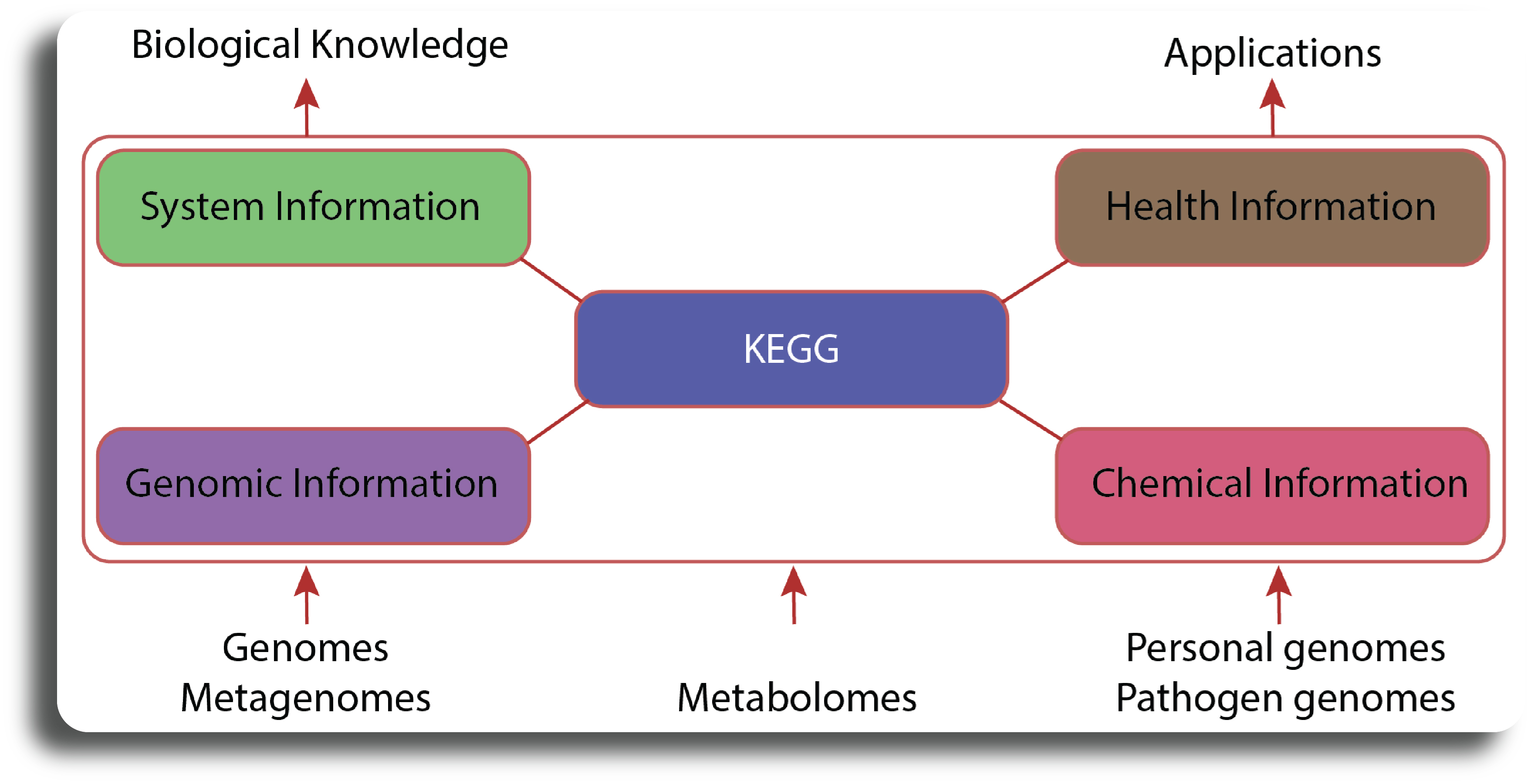
Retrieving pathways from KEGG databases#
In this section, we will retrieve pathways and related genesets from the KEGG database using R command line. Here we will use KEGGREST R package that provides a client interface to the KEGG REST server. KEGGREST can be installed from the Bioconductor using following command.
suppressMessages({if (!require("BiocManager", quietly = TRUE))
install.packages("BiocManager")
suppressWarnings(BiocManager::install("KEGGREST", update = F))
})
suppressPackageStartupMessages({
library(KEGGREST)
})
KEGG contains a number of databases. To get an idea of what is available, run listDatabases():
KEGGREST::listDatabases()
- 'pathway'
- 'brite'
- 'module'
- 'ko'
- 'genome'
- 'vg'
- 'ag'
- 'compound'
- 'glycan'
- 'reaction'
- 'rclass'
- 'enzyme'
- 'disease'
- 'drug'
- 'dgroup'
- 'environ'
- 'genes'
- 'ligand'
- 'kegg'
We can use these databases in further queries. Note that in many cases you can also use a three-letter KEGG organism code or a “T number” (genome identifier) in the same place you would use one of these database names.
We can obtain the list of organisms available in KEGG with the keggList() function:
organism <- keggList("organism")
print(paste0("KEGG supports ",dim(organism)[1]," organisms"))
[1] "KEGG supports 8889 organisms"
To view the supported organisms we can use the following command:
# View several supported organism
head(organism)
| T.number | organism | species | phylogeny |
|---|---|---|---|
| T01001 | hsa | Homo sapiens (human) | Eukaryotes;Animals;Vertebrates;Mammals |
| T01005 | ptr | Pan troglodytes (chimpanzee) | Eukaryotes;Animals;Vertebrates;Mammals |
| T02283 | pps | Pan paniscus (bonobo) | Eukaryotes;Animals;Vertebrates;Mammals |
| T02442 | ggo | Gorilla gorilla gorilla (western lowland gorilla) | Eukaryotes;Animals;Vertebrates;Mammals |
| T01416 | pon | Pongo abelii (Sumatran orangutan) | Eukaryotes;Animals;Vertebrates;Mammals |
| T03265 | nle | Nomascus leucogenys (northern white-cheeked gibbon) | Eukaryotes;Animals;Vertebrates;Mammals |
In submodule 02, we performed DE analysis on a human dataset. Therefore, we need to download pathways for humans. The abbreviation of human pathway in KEGG is hsa and we can use keggList function to get the pathway list.
# Obtain the pathways belong to human
pathways.list <- keggList("pathway", "hsa")
The pathway list contains pathway description and pathway code in a single line of text. To see the first five pathways, we can use the following command:
#list the specific pathways to view
pathway_ids <- c("hsa00010", "hsa00020", "hsa00030", "hsa00040", "hsa00051")
# View the first five pathways
pathways.list[pathway_ids]
- hsa00010
- 'Glycolysis / Gluconeogenesis - Homo sapiens (human)'
- hsa00020
- 'Citrate cycle (TCA cycle) - Homo sapiens (human)'
- hsa00030
- 'Pentose phosphate pathway - Homo sapiens (human)'
- hsa00040
- 'Pentose and glucuronate interconversions - Homo sapiens (human)'
- hsa00051
- 'Fructose and mannose metabolism - Homo sapiens (human)'
We can see that, in each line, the text in the quotation mark contains pathway information while the later part contains pathway code leading by a prefix path:. To get pathway codes from the pathway list, we can use the following command:
# Retrieve all the pathway IDs belong to human
pathway.codes <- sub("path:", "", names(pathways.list))
pathway.codes
- 'hsa01100'
- 'hsa01200'
- 'hsa01210'
- 'hsa01212'
- 'hsa01230'
- 'hsa01232'
- 'hsa01250'
- 'hsa01240'
- 'hsa00010'
- 'hsa00020'
- 'hsa00030'
- 'hsa00040'
- 'hsa00051'
- 'hsa00052'
- 'hsa00053'
- 'hsa00500'
- 'hsa00520'
- 'hsa00620'
- 'hsa00630'
- 'hsa00640'
- 'hsa00650'
- 'hsa00562'
- 'hsa00190'
- 'hsa00910'
- 'hsa00920'
- 'hsa00061'
- 'hsa00062'
- 'hsa00071'
- 'hsa00100'
- 'hsa00120'
- 'hsa00140'
- 'hsa00561'
- 'hsa00564'
- 'hsa00565'
- 'hsa00600'
- 'hsa00590'
- 'hsa00591'
- 'hsa00592'
- 'hsa01040'
- 'hsa00230'
- 'hsa00240'
- 'hsa00250'
- 'hsa00260'
- 'hsa00270'
- 'hsa00280'
- 'hsa00290'
- 'hsa00310'
- 'hsa00220'
- 'hsa00330'
- 'hsa00340'
- 'hsa00350'
- 'hsa00360'
- 'hsa00380'
- 'hsa00400'
- 'hsa00410'
- 'hsa00430'
- 'hsa00440'
- 'hsa00450'
- 'hsa00470'
- 'hsa00480'
- 'hsa00510'
- 'hsa00513'
- 'hsa00512'
- 'hsa00515'
- 'hsa00514'
- 'hsa00532'
- 'hsa00534'
- 'hsa00533'
- 'hsa00531'
- 'hsa00563'
- 'hsa00601'
- 'hsa00603'
- 'hsa00604'
- 'hsa00511'
- 'hsa00730'
- 'hsa00740'
- 'hsa00750'
- 'hsa00760'
- 'hsa00770'
- 'hsa00780'
- 'hsa00785'
- 'hsa00790'
- 'hsa00670'
- 'hsa00830'
- 'hsa00860'
- 'hsa00130'
- 'hsa00900'
- 'hsa00232'
- 'hsa00524'
- 'hsa00980'
- 'hsa00982'
- 'hsa00983'
- 'hsa03020'
- 'hsa03022'
- 'hsa03040'
- 'hsa03010'
- 'hsa00970'
- 'hsa03013'
- 'hsa03015'
- 'hsa03008'
- 'hsa03060'
- 'hsa04141'
- 'hsa04130'
- 'hsa04120'
- 'hsa04122'
- 'hsa03050'
- 'hsa03018'
- 'hsa03030'
- 'hsa03410'
- 'hsa03420'
- 'hsa03430'
- 'hsa03440'
- 'hsa03450'
- 'hsa03460'
- 'hsa03250'
- 'hsa03260'
- 'hsa03264'
- 'hsa03265'
- 'hsa03266'
- 'hsa03267'
- 'hsa02010'
- 'hsa04010'
- 'hsa04012'
- 'hsa04014'
- 'hsa04015'
- 'hsa04310'
- 'hsa04330'
- 'hsa04340'
- 'hsa04350'
- 'hsa04390'
- 'hsa04392'
- 'hsa04370'
- 'hsa04371'
- 'hsa04630'
- 'hsa04064'
- 'hsa04668'
- 'hsa04066'
- 'hsa04068'
- 'hsa04020'
- 'hsa04070'
- 'hsa04072'
- 'hsa04071'
- 'hsa04024'
- 'hsa04022'
- 'hsa04151'
- 'hsa04152'
- 'hsa04150'
- 'hsa04080'
- 'hsa04060'
- 'hsa04061'
- 'hsa04512'
- 'hsa04514'
- 'hsa04144'
- 'hsa04145'
- 'hsa04142'
- 'hsa04146'
- 'hsa04140'
- 'hsa04136'
- 'hsa04137'
- 'hsa04110'
- 'hsa04114'
- 'hsa04210'
- 'hsa04215'
- 'hsa04216'
- 'hsa04217'
- 'hsa04115'
- 'hsa04218'
- 'hsa04510'
- 'hsa04520'
- 'hsa04530'
- 'hsa04540'
- 'hsa04550'
- 'hsa04814'
- 'hsa04810'
- 'hsa04640'
- 'hsa04610'
- 'hsa04611'
- 'hsa04613'
- 'hsa04620'
- 'hsa04621'
- 'hsa04622'
- 'hsa04623'
- 'hsa04625'
- 'hsa04650'
- 'hsa04612'
- 'hsa04660'
- 'hsa04658'
- 'hsa04659'
- 'hsa04657'
- 'hsa04662'
- 'hsa04664'
- 'hsa04666'
- 'hsa04670'
- 'hsa04672'
- 'hsa04062'
- 'hsa04911'
- 'hsa04910'
- 'hsa04922'
- 'hsa04923'
- 'hsa04920'
- 'hsa03320'
- 'hsa04929'
- 'hsa04912'
- 'hsa04913'
- 'hsa04915'
- 'hsa04914'
- 'hsa04917'
- 'hsa04921'
- 'hsa04926'
- 'hsa04935'
- 'hsa04918'
- 'hsa04919'
- 'hsa04928'
- 'hsa04916'
- 'hsa04924'
- 'hsa04614'
- 'hsa04925'
- 'hsa04927'
- 'hsa04260'
- 'hsa04261'
- 'hsa04270'
- 'hsa04970'
- 'hsa04971'
- 'hsa04972'
- 'hsa04976'
- 'hsa04973'
- 'hsa04974'
- 'hsa04975'
- 'hsa04979'
- 'hsa04977'
- 'hsa04978'
- 'hsa04962'
- 'hsa04960'
- 'hsa04961'
- 'hsa04964'
- 'hsa04966'
- 'hsa04724'
- 'hsa04727'
- 'hsa04725'
- 'hsa04728'
- 'hsa04726'
- 'hsa04720'
- 'hsa04730'
- 'hsa04723'
- 'hsa04721'
- 'hsa04722'
- 'hsa04744'
- 'hsa04740'
- 'hsa04742'
- 'hsa04750'
- 'hsa04360'
- 'hsa04380'
- 'hsa04211'
- 'hsa04213'
- 'hsa04710'
- 'hsa04713'
- 'hsa04714'
- 'hsa05200'
- 'hsa05202'
- 'hsa05206'
- 'hsa05205'
- 'hsa05204'
- 'hsa05207'
- 'hsa05208'
- 'hsa05203'
- 'hsa05230'
- 'hsa05231'
- 'hsa05235'
- 'hsa05210'
- 'hsa05212'
- 'hsa05225'
- 'hsa05226'
- 'hsa05214'
- 'hsa05216'
- 'hsa05221'
- 'hsa05220'
- 'hsa05217'
- 'hsa05218'
- 'hsa05211'
- 'hsa05219'
- 'hsa05215'
- 'hsa05213'
- 'hsa05224'
- 'hsa05222'
- 'hsa05223'
- 'hsa05166'
- 'hsa05170'
- 'hsa05161'
- 'hsa05160'
- 'hsa05171'
- 'hsa05164'
- 'hsa05162'
- 'hsa05168'
- 'hsa05163'
- 'hsa05167'
- 'hsa05169'
- 'hsa05165'
- 'hsa05110'
- 'hsa05120'
- 'hsa05130'
- 'hsa05132'
- 'hsa05131'
- 'hsa05135'
- 'hsa05133'
- 'hsa05134'
- 'hsa05150'
- 'hsa05152'
- 'hsa05100'
- 'hsa05146'
- 'hsa05144'
- 'hsa05145'
- 'hsa05140'
- 'hsa05142'
- 'hsa05143'
- 'hsa05310'
- 'hsa05322'
- 'hsa05323'
- 'hsa05320'
- 'hsa05321'
- 'hsa05330'
- 'hsa05332'
- 'hsa05340'
- 'hsa05010'
- 'hsa05012'
- 'hsa05014'
- 'hsa05016'
- 'hsa05017'
- 'hsa05020'
- 'hsa05022'
- 'hsa05030'
- 'hsa05031'
- 'hsa05032'
- 'hsa05033'
- 'hsa05034'
- 'hsa05417'
- 'hsa05418'
- 'hsa05410'
- 'hsa05412'
- 'hsa05414'
- 'hsa05415'
- 'hsa05416'
- 'hsa04930'
- 'hsa04940'
- 'hsa04950'
- 'hsa04936'
- 'hsa04932'
- 'hsa04931'
- 'hsa04933'
- 'hsa04934'
- 'hsa01521'
- 'hsa01524'
- 'hsa01523'
- 'hsa01522'
We can use the following command to check how many pathways are available for human
print(paste0("Number of available pathways for human are: ", length(pathway.codes)))
[1] "Number of available pathways for human are: 353"
The following code will help to get list of genes and pathway’s description for all pathways available in human.
# Function to get all the gene names for each pathway
genes.by.pathway <- sapply(pathway.codes,
function(pwid){
pw <- keggGet(pwid)
if (is.null(pw[[1]]$GENE)) return(NA)
pw2 <- pw[[1]]$GENE[c(FALSE,TRUE)]
pw2 <- unlist(lapply(strsplit(pw2, split = ";", fixed = T), function(x)x[1]))
return(pw2)
}
)
# Function to get description for each pathway
description.by.pathway <- sapply(pathway.codes,
function(pwid){
pw <- keggGet(pwid)
if (is.null(pw[[1]]$NAME)) return(NA)
pw2 <- pw[[1]]$NAME
return(pw2)
}
)
# Convert the pathway description to a list
description.by.pathway <- as.list(description.by.pathway)
We can view the first five pathways with their genesets using the following command
# View the five pathways with the genesets
genes.by.pathway <- genes.by.pathway[!is.na(genes.by.pathway)]
genes.by.pathway[1:5]
- $hsa00010
-
- 'HK3'
- 'HK1'
- 'HK2'
- 'HKDC1'
- 'GCK'
- 'GPI'
- 'PFKM'
- 'PFKP'
- 'PFKL'
- 'FBP1'
- 'FBP2'
- 'ALDOC'
- 'ALDOA'
- 'ALDOB'
- 'TPI1'
- 'GAPDH'
- 'GAPDHS'
- 'PGK2'
- 'PGK1'
- 'PGAM1'
- 'PGAM2'
- 'PGAM4'
- 'ENO3'
- 'ENO2'
- 'ENO1'
- 'ENO4'
- 'PKM'
- 'PKLR'
- 'PDHA2'
- 'PDHA1'
- 'PDHB'
- 'DLAT'
- 'DLD'
- 'LDHAL6A'
- 'LDHAL6B'
- 'LDHA'
- 'LDHB'
- 'LDHC'
- 'ADH1A'
- 'ADH1B'
- 'ADH1C'
- 'ADH7'
- 'ADH4'
- 'ADH5'
- 'ADH6'
- 'AKR1A1'
- 'ALDH2'
- 'ALDH3A2'
- 'ALDH1B1'
- 'ALDH7A1'
- 'ALDH9A1'
- 'ALDH3B1'
- 'ALDH3B2'
- 'ALDH3A1'
- 'ACSS1'
- 'ACSS2'
- 'GALM'
- 'PGM1'
- 'PGM2'
- 'G6PC1'
- 'G6PC2'
- 'G6PC3'
- 'ADPGK'
- 'BPGM'
- 'MINPP1'
- 'PCK1'
- 'PCK2'
- $hsa00020
-
- 'CS'
- 'ACLY'
- 'ACO2'
- 'ACO1'
- 'IDH1'
- 'IDH2'
- 'IDH3B'
- 'IDH3G'
- 'IDH3A'
- 'OGDHL'
- 'OGDH'
- 'DLST'
- 'DLD'
- 'SUCLG1'
- 'SUCLG2'
- 'SUCLA2'
- 'SDHA'
- 'SDHB'
- 'SDHC'
- 'SDHD'
- 'FH'
- 'MDH1'
- 'MDH2'
- 'PC'
- 'PCK1'
- 'PCK2'
- 'PDHA2'
- 'PDHA1'
- 'PDHB'
- 'DLAT'
- $hsa00030
-
- 'GPI'
- 'G6PD'
- 'PGLS'
- 'H6PD'
- 'PGD'
- 'RPE'
- 'RPEL1'
- 'TKT'
- 'TKTL2'
- 'TKTL1'
- 'TALDO1'
- 'RPIA'
- 'DERA'
- 'RBKS'
- 'PGM1'
- 'PGM2'
- 'PRPS1L1'
- 'PRPS2'
- 'PRPS1'
- 'RGN'
- 'IDNK'
- 'GLYCTK'
- 'ALDOC'
- 'ALDOA'
- 'ALDOB'
- 'FBP1'
- 'FBP2'
- 'PFKM'
- 'PFKP'
- 'PFKL'
- $hsa00040
-
- 'GUSB'
- 'KL'
- 'UGT2A1'
- 'UGT2A3'
- 'UGT2B17'
- 'UGT2B11'
- 'UGT2B28'
- 'UGT1A6'
- 'UGT1A4'
- 'UGT1A1'
- 'UGT1A3'
- 'UGT2B10'
- 'UGT1A9'
- 'UGT2B7'
- 'UGT1A10'
- 'UGT1A8'
- 'UGT1A5'
- 'UGT2B15'
- 'UGT1A7'
- 'UGT2B4'
- 'UGT2A2'
- 'UGDH'
- 'UGP2'
- 'AKR1A1'
- 'CRYL1'
- 'RPE'
- 'RPEL1'
- 'XYLB'
- 'AKR1B1'
- 'AKR1B10'
- 'DCXR'
- 'SORD'
- 'DHDH'
- 'FGGY'
- 'CRPPA'
- $hsa00051
-
- 'MPI'
- 'PMM2'
- 'PMM1'
- 'GMPPB'
- 'GMPPA'
- 'GMDS'
- 'GFUS'
- 'FPGT'
- 'FCSK'
- 'ENOSF1'
- 'HK3'
- 'HK1'
- 'HK2'
- 'HKDC1'
- 'PFKM'
- 'PFKP'
- 'PFKL'
- 'FBP1'
- 'FBP2'
- 'PFKFB1'
- 'PFKFB2'
- 'PFKFB3'
- 'PFKFB4'
- 'TIGAR'
- 'KHK'
- 'SORD'
- 'AKR1B1'
- 'AKR1B10'
- 'ALDOC'
- 'ALDOA'
- 'ALDOB'
- 'TPI1'
- 'TKFC'
Use the following command to see the description of the first five pathways
# View the description of the first five pathways
description.by.pathway <- description.by.pathway[!is.na(description.by.pathway)]
description.by.pathway[names(genes.by.pathway[1:5])]
- $hsa00010
- 'Glycolysis / Gluconeogenesis - Homo sapiens (human)'
- $hsa00020
- 'Citrate cycle (TCA cycle) - Homo sapiens (human)'
- $hsa00030
- 'Pentose phosphate pathway - Homo sapiens (human)'
- $hsa00040
- 'Pentose and glucuronate interconversions - Homo sapiens (human)'
- $hsa00051
- 'Fructose and mannose metabolism - Homo sapiens (human)'
Then we can save the output to *.gmt file using the following commands
# Saving the pathway information to the local repository
outfile <- "./data/KEGG_pathways.gmt"
writeGMT(genes.by.pathway, description.by.pathway, outfile)
gsutil cp ./data/KEGG_pathways.gmt gs://cpa-output
In the next submodule, we will do Pathway Analysis.