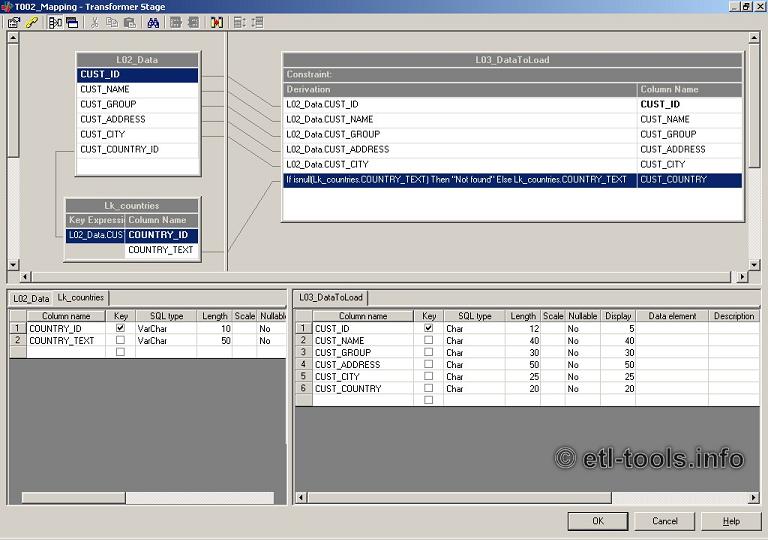
In modern natural language processing, the transformer lookup table serves as a foundational component for accelerating sequence modeling by enabling fast token-to-index mapping and efficient attention calculations—critical for scaling large language models.

Optimizing Token Indexing with Lookup Tables
A transformer lookup table maps discrete tokens to unique integer indices, reducing lookup time significantly compared to linear scanning. This indexed approach accelerates input preprocessing and facilitates real-time inference, especially in high-throughput environments where speed is paramount.
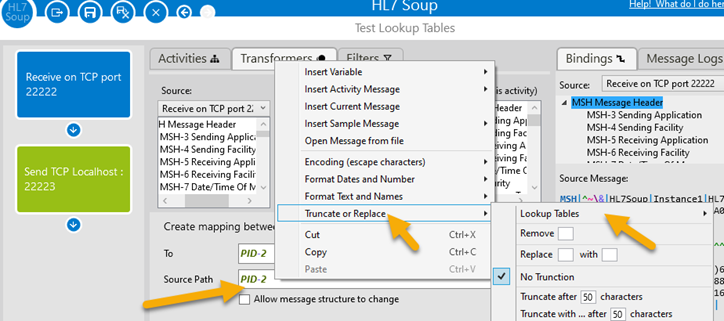
Efficient Attention Computation via Index Mapping
During the attention mechanism, lookup tables power rapid computation of key-value index pairs by substituting token embeddings with precomputed position and token IDs. This minimizes redundant calculations, improves cache utilization, and enhances overall model throughput without sacrificing accuracy.
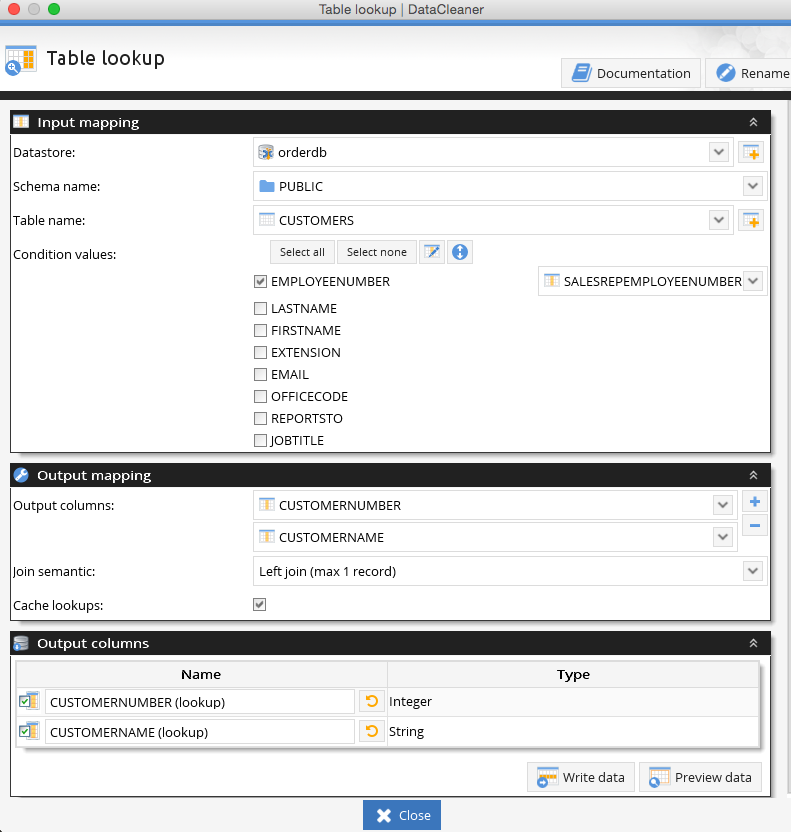
Impact on Model Scalability and Performance
By replacing dynamic index lookups with static lookup tables, transformer models achieve faster training and inference cycles. This optimization is especially vital for long-sequence tasks and resource-constrained deployment scenarios, enabling broader applicability across edge and cloud platforms.
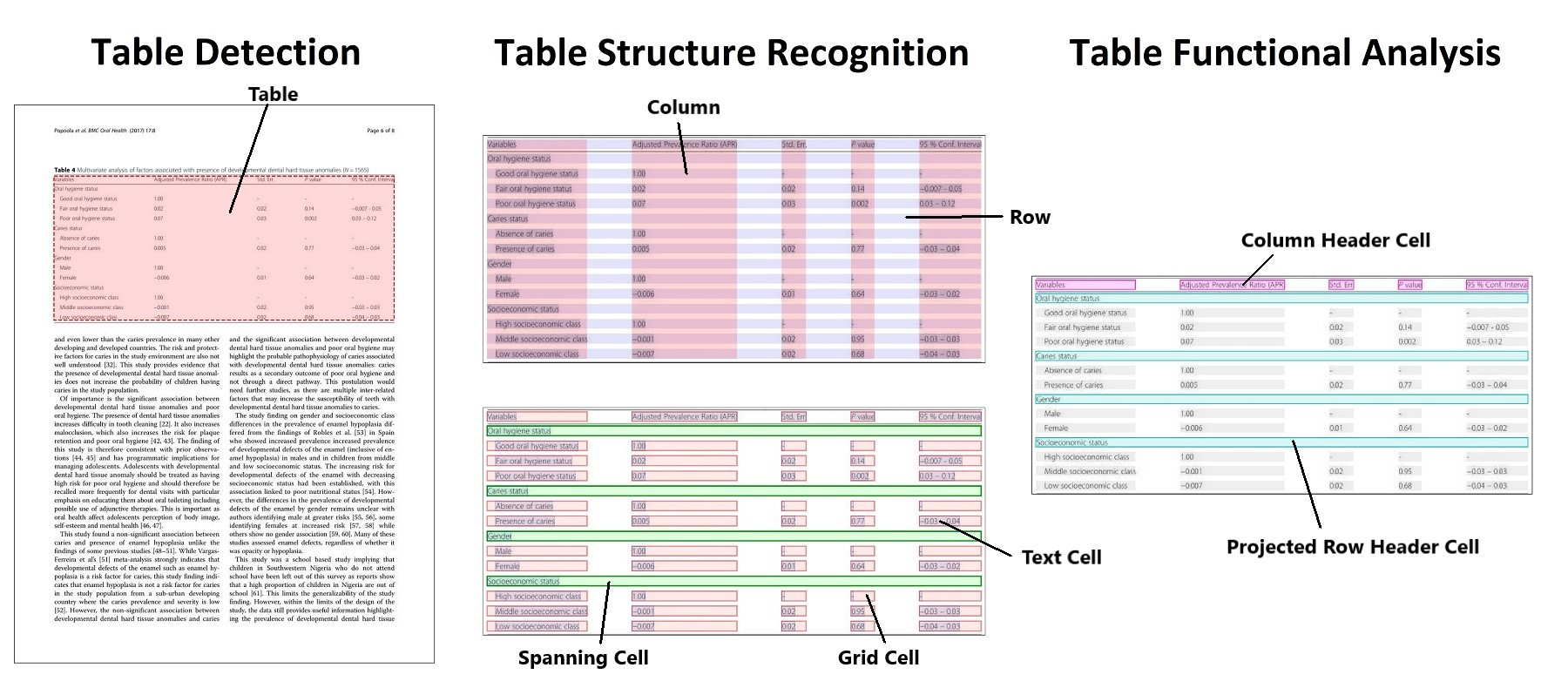
The transformer lookup table is a pivotal innovation in neural architecture design, driving efficiency and scalability in sequence modeling. Understanding and implementing effective lookup strategies empowers developers to build faster, more responsive NLP systems. Explore advanced implementations to unlock the full potential of transformer-based models today.