In the evolving landscape of data warehousing, star schema design remains a cornerstone for efficient analytics, enabling fast query execution and intuitive data modeling that supports business intelligence.

Understanding Star Schema Design
Star schema design organizes data into a central fact table surrounded by dimension tables, forming a structure that mirrors business processes. This clear, denormalized layout simplifies querying by reducing joins, improving performance, and making data relationships transparent for analysts and developers alike.
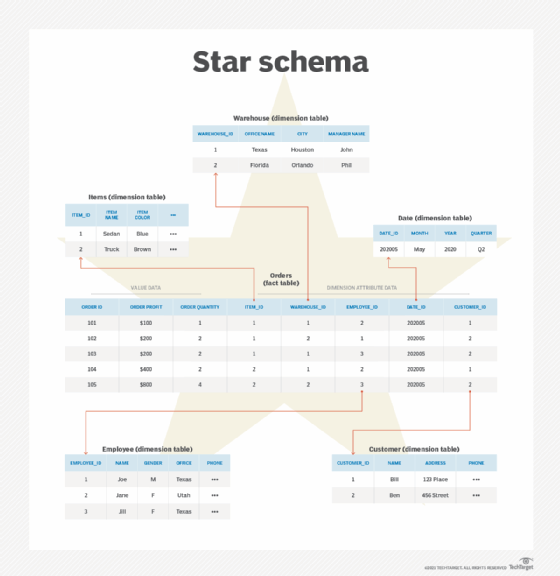
Key Components of Star Schema Implementation
At its core, a star schema consists of a fact table storing measurable business events—such as sales or orders—and multiple dimension tables providing context like time, product, and customer details. Properly identifying primary and foreign keys ensures referential integrity, enabling scalable and maintainable data models that support complex reporting and real-time insights.
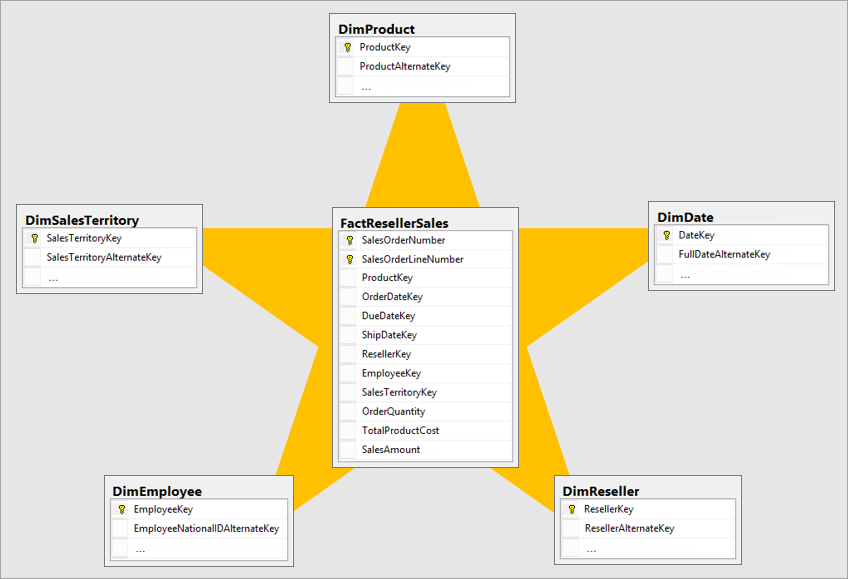
Best Practices for Star Schema Design
To maximize efficiency and usability, design star schemas with scalability in mind: use surrogate keys for consistency, normalize dimension tables carefully to avoid redundancy, and prioritize frequently accessed dimensions. Regularly review and evolve schemas as business needs shift, ensuring alignment with analytical goals and performance requirements.

Adopting star schema design is essential for building high-performance data warehouses that empower faster decision-making. By structuring data for clarity and speed, organizations unlock deeper insights and greater agility. Begin optimizing your schema today to drive smarter, faster analytics.
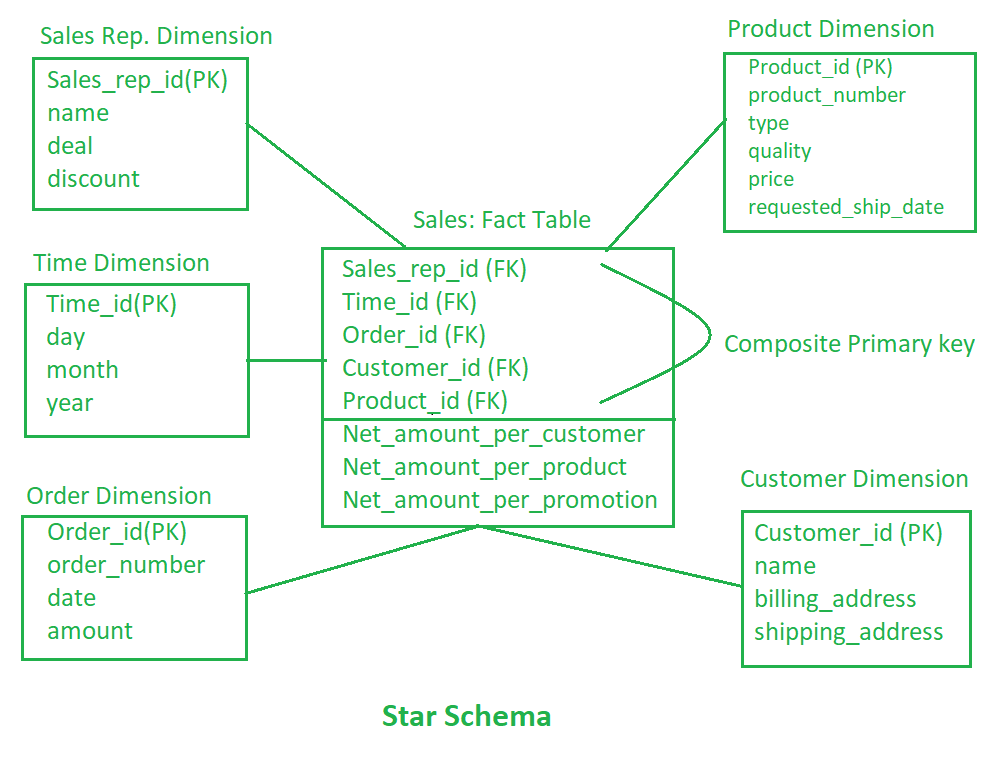
Understand star schema design and its relevance to developing Power BI semantic models optimized for performance and usability. Design a star schema for such a data warehouse clearly identifying the fact table and dimension tables, their primary keys, and foreign keys. Also, mention which columns in the fact table represent dimensions and which ones represent measures or facts.
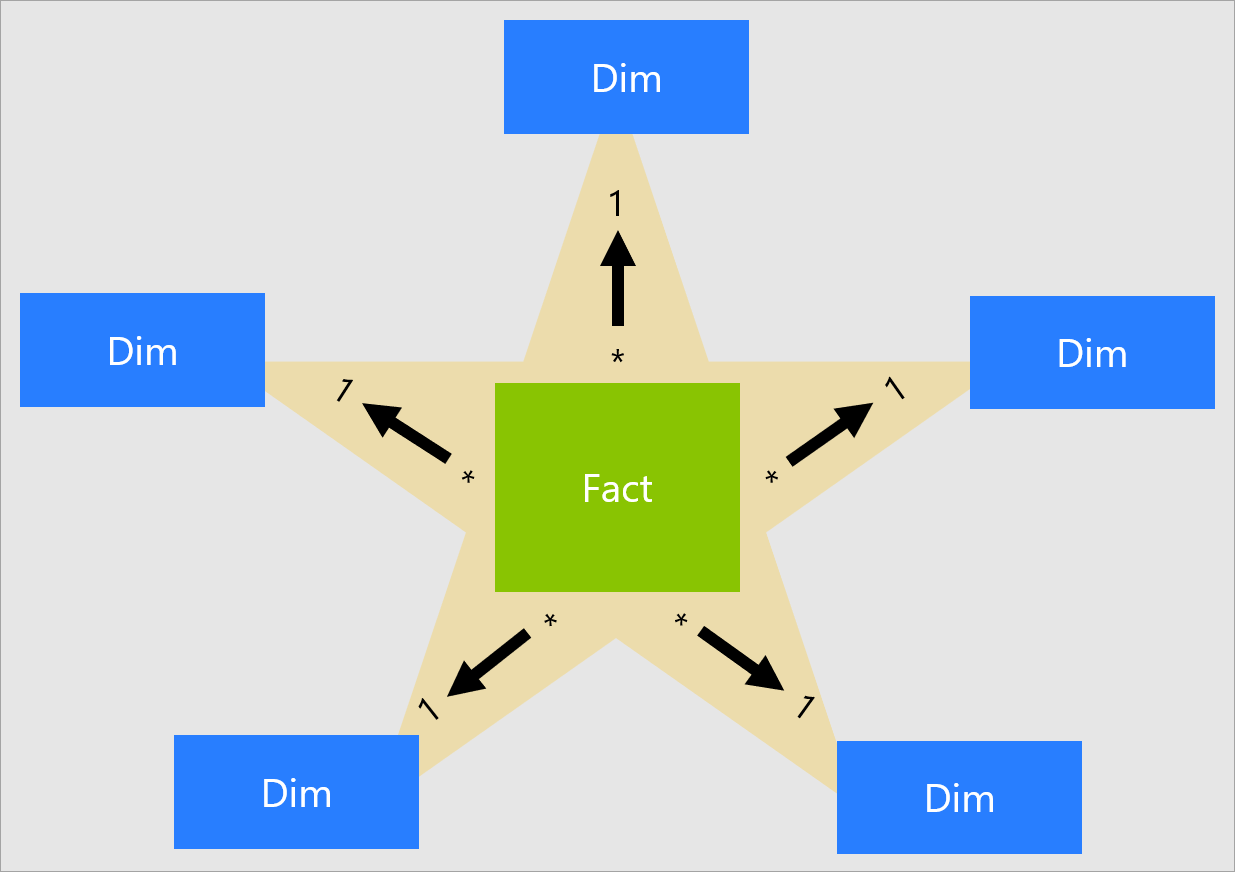
Learn about the star schema, a simple and common style of data mart and data warehouse design that consists of fact tables and dimension tables. See examples, benefits, and contrast with snowflake schema. Learn what a star schema is, how it differs from 3NF, and how it can improve query performance and data analysis.
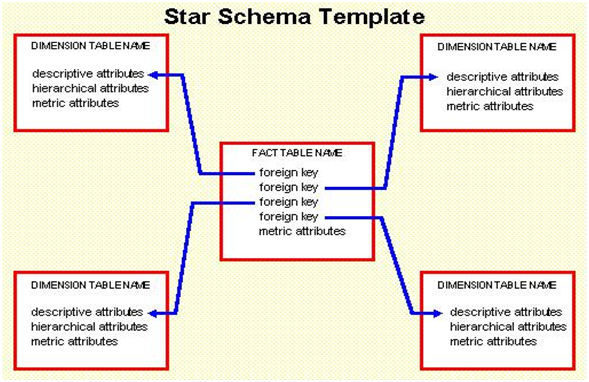
A star schema has a fact table in the center and dimension tables around it, with denormalized data for faster access. What is Star Schema in Data Modeling? A star schema is a data modeling approach designed for organizing information in a structured and efficient way. It is commonly used in data warehouses, databases, and data marts to simplify querying and analysis.
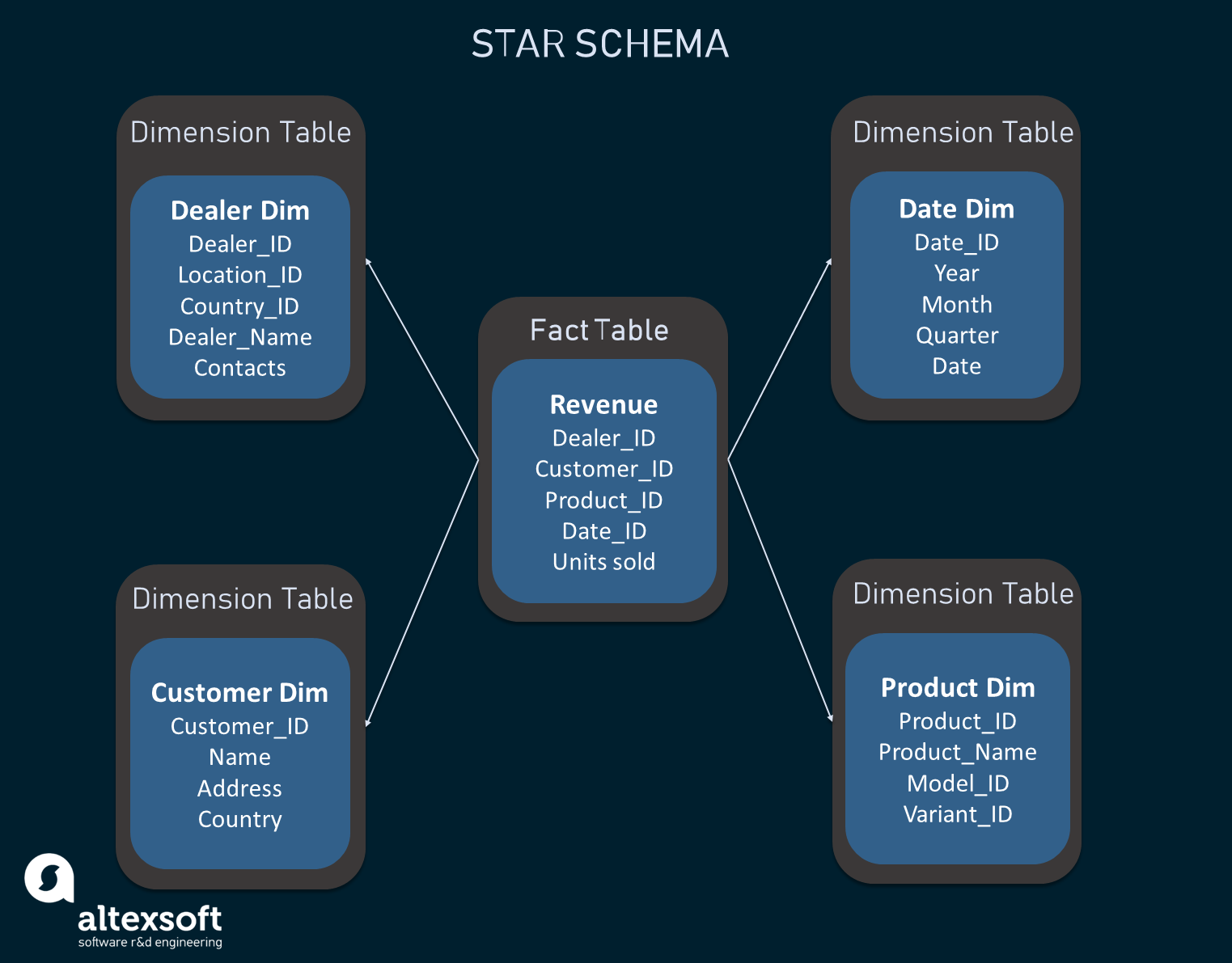
The design centers around a fact table linked to multiple dimension tables, creating a star-like structure. It's also known as Kimball data. Understand the Star Schema in data warehousing, its structure, components, and benefits for simplified queries and improved performance.
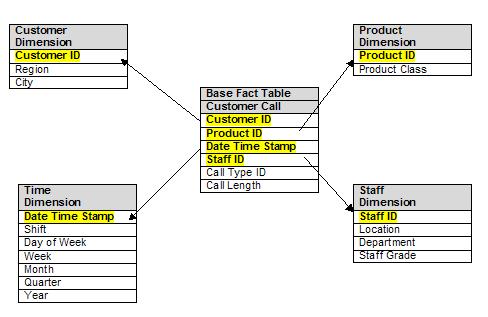
Learn how to implement Star Schema in your data warehouse for faster analytics queries. Complete guide with SQL examples, best practices, and performance tips for dimensional data modeling. Learn what the database structure called a star schema is, how it works, the difference between it and a snowflake schema, pros and cons and use cases.
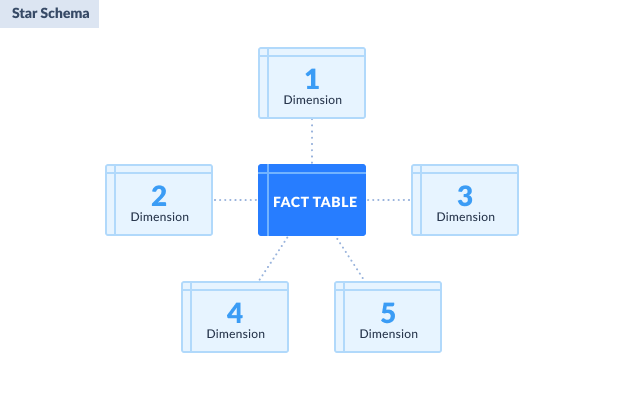
The star schema remains the simplest and most stable model for most reporting needs. It offers a reliable contract between data engineering, analytics, and the business. In this comprehensive guide, we explore the powerful world of the data warehouse star schema.
From understanding the core concepts and benefits to designing and implementing the schema, this guide covers everything you need to know about star schema in data warehousing. Discover the key components, best practices, and tools for building a well.