Video of Interactive System Using ReaLchords
To show that ReaLchords is jammable in real-time, we add two demo videos.
In both videos, the musician plays a melody part on the piano, mostly on the right side of the piano. Their notes are highlighted in orange. Our model ReaLchords generates chords in an online fashion in real-time to accompany the musician, mostly on left side of the piano. The generated chords are highlighted in blue. The musician's playing is quantized at the 16th note level at the tempo they set.
The interface you see is from our follow-on work where we add a visual "anticipation" to show what chords the model might generate next to help the musician anticipate what chord changes might be coming. Visually you'll see a "waterfall" of chords (inspired by guitar hero). These "anticipated" chords are "speculated" by running our model forward and guessing both what the musician might play and what the model might play. This part is not included in this current paper, and will be in our next system paper, stay tuned!
In the first video, the musician sets the tempo to 100 BPM and plays with a metronome. The musicians starts playing a melody first, and then ReaLchords comes in at 0:15.
In the second video, the musician sets the tempo to 90 BPM, but doesn't listen to the metronome. The musician improvises along with ReaLchords from the beginning.
ReaLchords: an online accompaniment model that adapts to unknown input and perturbation
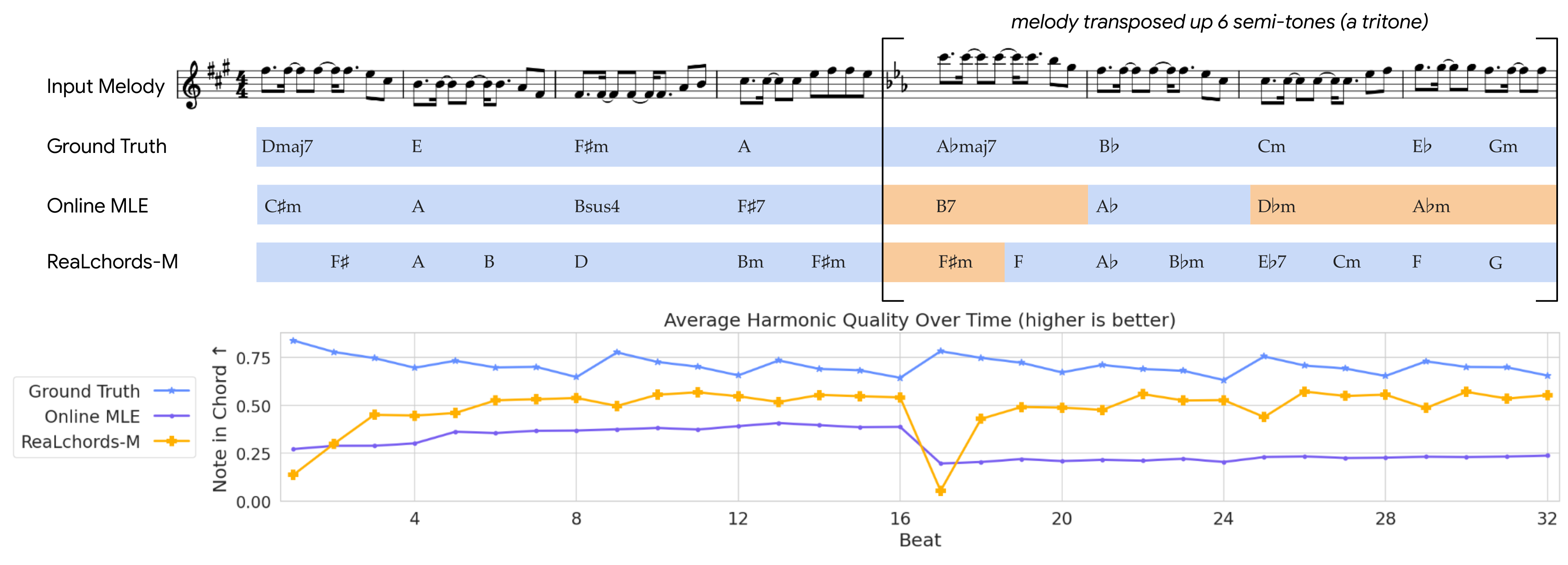
Online models finetuned with RL are able to recover from mistakes, while models trained with MLE alone do not. We take a melody from the test set and midway introduce an abrupt transposition designed to disrupt the accompaniment model (top row). The Online MLE model predicts a bad chord (B7) and fails to adapt. ReaLchords also predicts a bad chord (F#), but adapts quickly. Wrong chords highlighted in orange are our own judgment informed by music theory, but the overall pattern is corroborated by an objective measure of harmonic quality, averaged over many trials of this experiment (bottom row).



Cold Start Generation (Section 5.4)
Models predict chords immediately and have to adapt to the resulting melody-chord combinations, which are usually wrong and outside of the data distribution. The Online MLE struggles to adapt to its own past chords, and never gets close to the primed behavior. ReaLchords and ReaLchords-M quickly overcome their own mistakes. Each row is an example.















In the third example, the online MLE model stopped the generation early.
Primed Generation
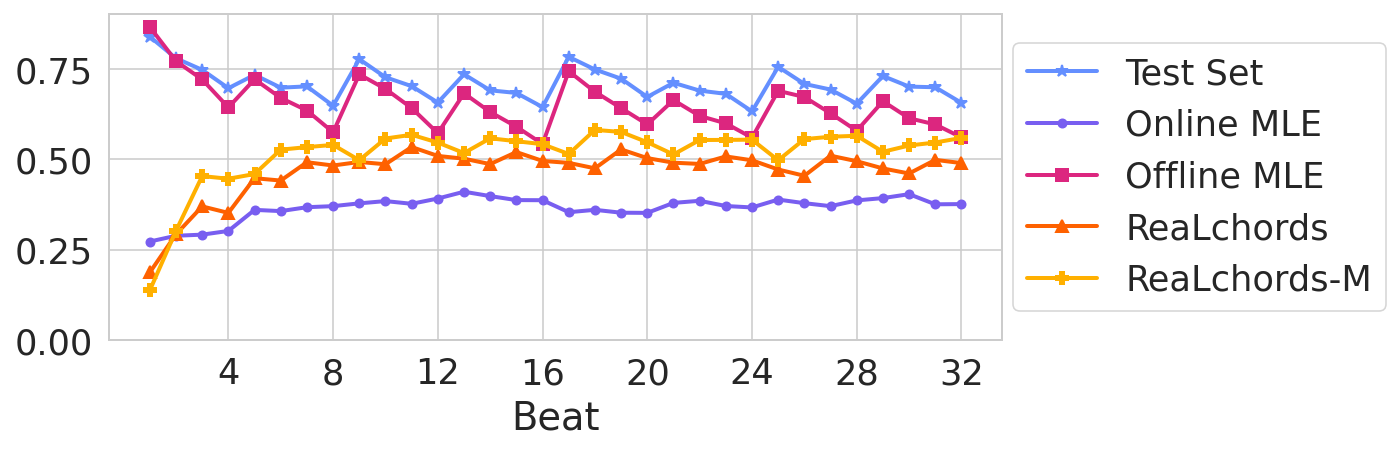
Models are primed with 8 beats of ground truth chords before generating their own chords. This avoids the cold-start problem of predicting a chord without knowing anything about the melody, and gives an indication of the model’s ability to anticipate what happens next without having to first adapt to what happened previously. Behavior is similar across the models. For reference, we also plot the cold-start behavior of Online MLE (without priming), which is significantly worse. We argue that, as a benchmark for online accompaniment, primed generation is unnatural and too facile. Each row is an example.












Perturbed Generation
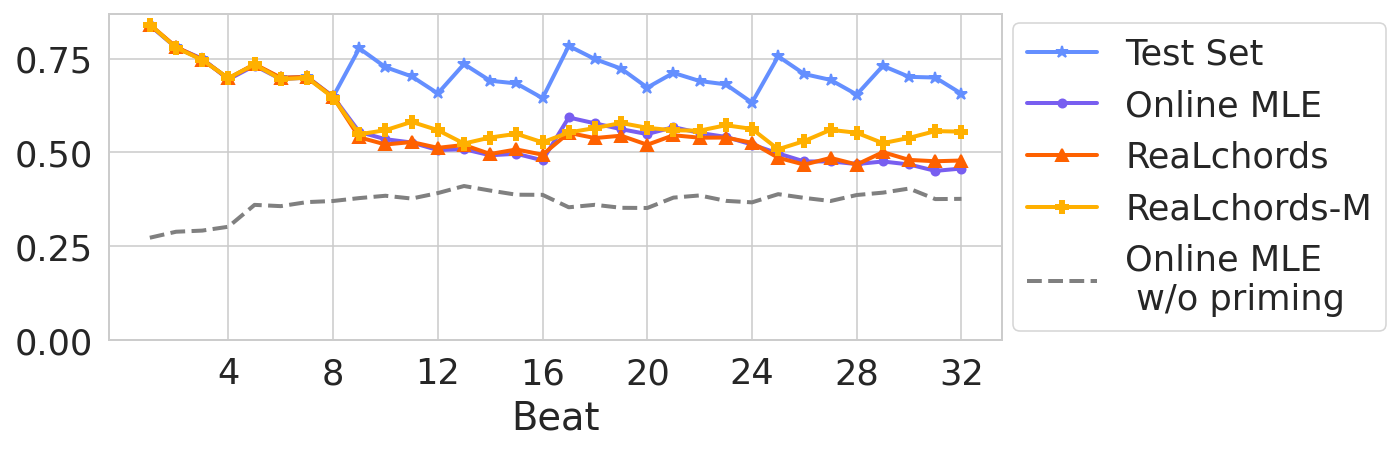
We transpose the melody up by a tritone (6 semitones) at beat 17, resulting in both an out-of-distribution melody and almost guaranteeing that the next chord is a poor fit. This is similar to the push test in legged robotics. The Online MLE fails the test: it exhibits a drop in harmonic quality and never recovers. ReaLchords and ReaLchords-M quickly adapt to the new key and recover their previous performance. Each row is an example.












In the third example, the online MLE model stopped the generation early.
RL Finetuning Objective
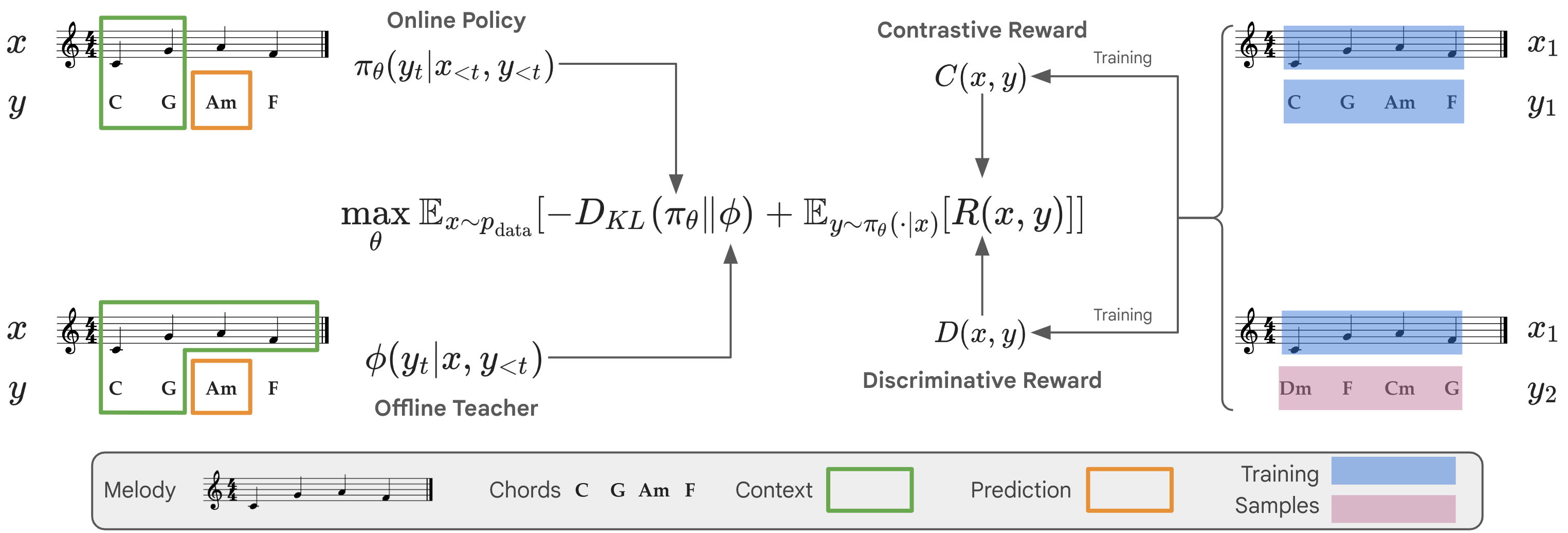
ReaLchords leverages RL finetuning to learn anticipation and adaptation for online melody-to-chord accompaniment. Initializing from a model pretrained by MLE, the policy generates a complete chord response to a melody from the dataset, each chord being predicted given only previous melody and chords (top left). In contrast, the offline model (also trained by MLE) predicts each chord given the complete melody (bottom left). A KL-divergence penalty distills the predictions of the offline model into the online model, improving its ability to anticipate the future. (Right) The reward stems from an ensemble of multi-scale contrastive and discriminative models that evaluate the musical coherence between melody and chord. The final training objective in ReaLchords is a sum of the reward and the distillation loss (center).