Recomposer: Event-roll-guided generative audio editing
|Paper|
Daniel P. W. Ellis, Eduardo Fonseca, Ron J. Weiss, Kevin Wilson, Scott Wisdom, Hakan Erdogan, John R. Hershey, Aren Jansen, R. Channing Moore, Manoj Plakal
Google DeepMind
Overview
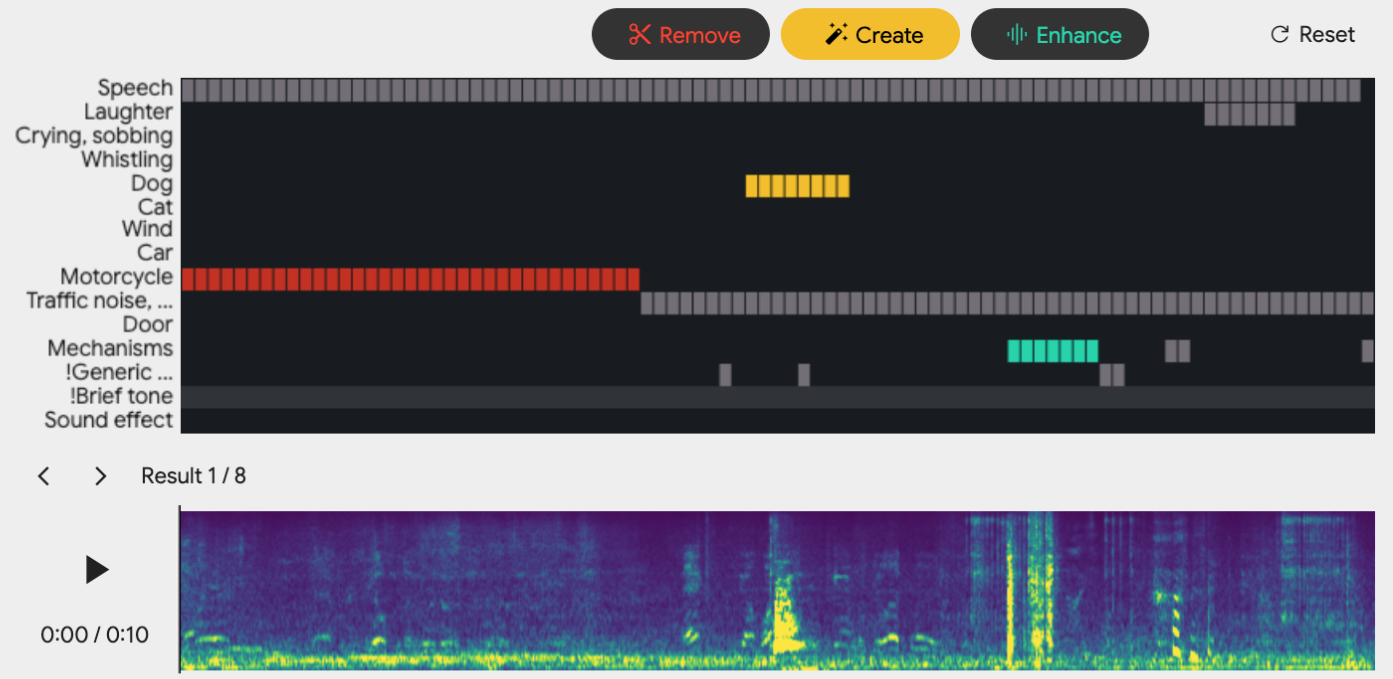
Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., “enhance Door”) and a graphical representation of the event timing derived from an “event roll” transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic input/desired output audio examples formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions – action, class, timing. We believe our work demonstrates “recomposition” is an important and practical application.