REST API Specifications¶
Key Concepts¶
Clusters¶
Redis Labs clusters are a set of nodes, typically two or more, providing database services. Clusters are inherently multi-tenant, and a single cluster can manage multiple databases accessed through individual endpoints.
Protocol and Headers¶
JSON Requests and Responses¶
The Redis Labs REST API uses the JavaScript Object Notation (JSON) for requests and responses.
Some responses may have an empty body, but indicate the response with standard HTTP codes. For more information, see RFC 4627 (http://www.ietf.org/rfc/rfc4627.txt) and www.json.org.
Both requests and responses may include zero or more objects.
In case the request is for a single entity, the response shall return a single JSON object, or none. In case the request if for a list of entities, the response shall return a single JSON array with 0 or more elements.
Requests may be delivered with some JSON object fields missing. In this case, these fields will be assigned default values (often indicating they are not in use).
Request Headers¶
The Redis Labs REST API supports the following HTTP headers:
| Header | Supported/Required Values |
|---|---|
| Accept | application/json |
| Content-Length | Length (in bytes) of request message. |
| Content-Type | application/json |
Response Headers¶
The Redis Labs REST API supports the following HTTP headers:
| Header | Supported/Required Values |
|---|---|
| Content-Type | application/json |
| Content-Length | Length (in bytes) of response message. |
API Versions¶
All RLEC API operations are versioned, in order to minimize the impact of backwards-incompatible API changes and to coordinate between different versions operating in parallel.
Authentication¶
Authentication to RLEC API occurs via Basic Auth. Provide your RLEC username and password as the basic auth credentials.
All calls must be made over SSL, to port 9443.
Example Request:
curl -u "demo@redislabs.com:password" https://localhost:9443/v1/bdbs
Common Responses¶
The following are common responses which may be returned in some cases regardless of any specific request.
| Response | Condition / Required handling |
|---|---|
| 503 (Service Unavailable) | Contacted node is currently not a member of any active cluster. |
| 505 (HTTP Version Not Supported) | An unsupported X-API-Version was used, see API Versions above. |
Object Attributes¶
Note: Some objects include fields that are for internal use and are not documented. These fields might be returned as part of the object’s json format and should be ignored.
action¶
bdb¶
An API object that represents a managed database in the cluster.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Cluster unique ID of database. Can be set on Create, but can not be updated. |
| shard_list | array of integer | Cluster unique IDs of all database shards. |
| name | string | Database name |
| type | ‘redis’ | Type of database |
| ‘memcached’ | ||
| version | string | Database compatibility version: full redis / memcached version number, e.g. 6.0.6 |
| redis_version | string | Version of the redis-server processes: e.g. 6.0, 5.0-big |
| bigstore | boolean (default: False) | Database bigstore option |
| created_time | string | The date and time the database was created (read-only) |
| last_changed_time | string | Last administrative configuration change (read-only) |
| status | ‘pending’ | Database life-cycle status. See the ‘bdb -> status’ section (read-only) |
| ‘active’ | ||
| ‘active-change-pending’ | ||
| ‘delete-pending’ | ||
| ‘import-pending’ | ||
| ‘creation-failed’ | ||
| ‘recovery’ | ||
| import_status | ‘idle’ | Database import process status (read- only) |
| ‘initializing’ | ||
| ‘importing’ | ||
| ‘succeeded’ | ||
| ‘failed’ | ||
| import_progress | number, 0-100 | Database import progress (percentage) (read-only) |
| import_failure_reason | ‘download-error’ | Import failure reason (read-only) |
| ‘file-corrupted’ | ||
| ‘general-error’ | ||
| ‘file-larger-than-mem-limit:<n bytes of expected dataset>:<n bytes configured bdb limit>’ | ||
| ‘key-too-long’ | ||
| ‘invalid-bulk-length’ | ||
| ‘out-of-memory’ | ||
| backup_status | ‘exporting’ | Status of scheduled periodic backup process (read-only) |
| ‘succeeded’ | ||
| ‘failed’ | ||
| backup_progress | number, 0-100 | Database scheduled periodic backup progress (percentage) (read-only) |
| backup_failure_reason | ‘no-permission’ | Reason of last failed backup process (read-only) |
| ‘wrong-file-path’ | ||
| ‘general-error’ | ||
| export_status | ‘exporting’ | Status of manually triggered export process (read-only) |
| ‘succeeded’ | ||
| ‘failed’ | ||
| export_progress | number, 0-100 | Database manually trigerred export progress (percentage) (read-only) |
| export_failure_reason | ‘no-permission’ | Reason of last failed export process (read-only) |
| ‘wrong-file-path’ | ||
| ‘general-error’ | ||
| last_export_time | string | Time of last successful export (read- only) |
| dataset_import_sources | complex object | Array of source file location description objects to import from when performing an import action. This is write only, it cannot be read after set. GET /jsonschema to retrieve the object’s structure. See also the ‘bdb -> dataset_import_sources’ section. |
| memory_size | integer (default: 0) | Database memory limit (0 is unlimited), expressed in bytes. |
| bigstore_ram_size | integer (default: 0) | Memory size of bigstore RAM part. |
| eviction_policy | ‘volatile-lru’ | Database eviction policy (Redis style). Redis db default: ‘volatile-lru’, memcached db default: ‘allkeys-lru’ |
| ‘volatile-ttl’ | ||
| ‘volatile-random’ | ||
| ‘allkeys-lru’ | ||
| ‘allkeys-random’ | ||
| ‘noeviction’ | ||
| ‘volatile-lfu’ | ||
| ‘allkeys-lfu’ | ||
| replication | boolean (default: False) | In-memory database replication mode |
| data_persistence | ‘disabled’ | Database on-disk persistence policy. For snapshot persistence, a snapshot_policy must be provided |
| ‘snapshot’ | ||
| ‘aof’ | ||
| snapshot_policy | array of snapshot_policy object | Policy for snapshot-based data persistence. Dataset snapshot will be taken every N secs if there are at least M writes changes in the dataset |
| aof_policy | ‘appendfsync-every-sec’ | Policy for Append-Only File data persistence |
| ‘appendfsync-always’ | ||
| max_aof_load_time | integer | Maximum time shard’s AOF reload should take (seconds). Default 3600. |
| max_aof_file_size | integer | Maximum size for shard’s AOF file (bytes). Default 300GB, (on bigstore DB 150GB) |
| backup | boolean (default: False) | Policy for periodic database backup |
| backup_location | complex object | Target for automatic database backups. GET /jsonschema to retrieve the object’s structure. See also the ‘bdb -> backup_location’ section. |
| backup_interval | integer | Interval in seconds in which automatic backup will be initiated |
| backup_interval_offset | integer | Offset (in seconds) from round backup interval when automatic backup will be initiated (should be less than backup_interval) |
| backup_history | integer (default: 0) | Backup history retention policy (number of days, 0 is forever) |
| last_backup_time | string | Time of last successful backup (read- only) |
| hash_slots_policy | ‘legacy’ | The policy used for hash slots handling; ‘legacy’ means slots range will be ‘1-4096’, ‘16k’ means slots range will be ‘0-16383’ |
| ‘16k’ | ||
| oss_cluster | boolean (default: False) | OSS Cluster mode option. Cannot be enabled with ‘hash_slots_policy’: ‘legacy’ |
| shard_block_foreign_keys | boolean (default: True) | In Lua scripts, prevent use of keys which could reside in a different shard (foreign keys) |
| shard_block_crossslot_keys | boolean (default: False) | In Lua scripts, prevent use of keys from different hash slots within the range owned by the current shard |
| disabled_commands | string (default: ) | Redis commands which are disabled in db |
| oss_cluster_api_preferred_ip_type | ‘internal’ | Internal/external IP type in oss cluster API. Default value for new endpoints |
| ‘external’ | ||
| sharding | boolean (default: False) | Cluster mode (server side sharding). When true, shard hashing rules must be provided by either oss_sharding or shard_key_regex |
| shards_count | integer, 1-512 (default: 1) | Number of database server-side shards |
| shards_placement | ‘dense’ | Control the density of shards: should they reside on as few or as many nodes as possible |
| ‘sparse’ | ||
| shard_key_regex | [{
"regex": string
}, ...]
|
Custom keyname-based sharding rules. Custom keyname-based sharding rules. To use the default rules you should set the value to: [ { “regex”: “.*\\{(?<tag>.*)\\}.*” }, { “regex”: “(?<tag>.*)” } ] |
| oss_sharding | boolean (default: False) | An alternative to shard_key_regex for using the common case of the oss shard hashing policy |
| auto_upgrade | boolean (default: False) | Should upgrade automatically after a cluster upgrade |
| internal | boolean (default: False) | Is this a bdb used by the cluster internally |
| tags | [{
"key": string,
"value": string
}, ...]
|
Optional list of tags objects attached to the database; key: key representing the tag’s meaning - must be unique among tags. (pattern does not allow special characters &,<,>,”); value: the tag’s value |
| action_uid | string | Currently running action’s uid (read- only) |
| authentication_redis_pass | string | Redis AUTH password authentication |
| authentication_sasl_uname | string | Binary memcache SASL username (pattern does not allow special characters &,<,>,”) |
| authentication_sasl_pass | string | Binary memcache SASL password |
| authentication_admin_pass | string | Password for administrative access to the BDB (used for SYNC from the BDB) |
| ssl | boolean (default: False) | (deprecated) Require SSL authenticated and encrypted connections to the database |
| tls_mode | ‘enabled’ | Require SSL authenticated and encrypted connections to the database |
| ‘disabled’ | ||
| ‘replica_ssl’ | ||
| enforce_client_authentication | ‘enabled’ | Require authentication of client certificates for SSL connections to the database. If set to ‘enabled’, a certificate should be provided in either authentication_ssl_client_certs or authentication_ssl_crdt_certs |
| ‘disabled’ | ||
| authentication_ssl_client_certs | [{
"client_cert": string
}, ...]
|
List of authorized client certificates; client_cert: X.509 PEM (base64) encoded certificate |
| authorized_names | array of string | Additional certified names |
| authentication_ssl_crdt_certs | [{
"client_cert": string
}, ...]
|
List of authorized crdt certificates; client_cert: X.509 PEM (base64) encoded certificate |
| roles_permissions | [{
"role_uid": integer,
"redis_acl_uid": integer
}, ...]
|
|
| default_user | boolean (default: True) | Is connecting with a default user allowed? |
| data_internode_encryption | boolean | Should the data plane internode communication for this database be encrypted |
| port | integer | TCP port on which the database is available. Will be generated automatically if omitted and will be returned as 0 |
| dns_address_master | string | (deprecated) Database private address endpoint FQDN (read-only) |
| endpoints | array | List of database access endpoints (read- only) |
| endpoint_node | integer | (deprecated) Node UID hosting the BDB’s endpoint (read-only) |
| endpoint_ip | complex object | (deprecated) External IP addresses of node hosting the BDB’s endpoint. GET /jsonschema to retrieve the object’s structure. (read-only) |
| max_connections | integer (default: 0) | Maximum number of client connections allowed (0 unlimited) |
| implicit_shard_key | boolean (default: False) | Controls the behavior of what happens in case a key does not match any of the regex rules. When set to True, if a key does not match any of the rules, the entire key will be used for the hashing function. When set to False, if a key does not match any of the rules, an error will be returned. |
| replica_sources | array of syncer_sources object | Remote endpoints of database to sync from. See the ‘bdb -> replica_sources’ section |
| crdt_sources | array of syncer_sources object | Remote endpoints/peers of CRDB database to sync from. See the ‘bdb -> replica_sources’ section |
| gradual_src_mode | ‘enabled’ | Indicates if gradual sync (of sync sources) should be activated |
| ‘disabled’ | ||
| gradual_src_max_sources | integer (default: 1) | Sync a maximum N sources in parallel (gradual_src_mode should be enabled for this to take effect) |
| gradual_sync_mode | ‘enabled’ | Indicates if gradual sync (of source shards) should be activated (‘auto’ for automatic decision) |
| ‘disabled’ | ||
| ‘auto’ | ||
| gradual_sync_max_shards_per_source | integer (default: 1) | Sync a maximum of N shards per source in parallel (gradual_sync_mode should be enabled for this to take effect) |
| sync_sources | [{
"uid": integer,
"uri": string,
"compression": integer,
"status": string,
"rdb_transferred": integer,
"rdb_size": integer,
"last_update": string,
"lag": integer,
"last_error": string
}, ...]
|
(deprecated, instead use replica_sources or crdt_sources) Remote endpoints of database to sync from. See the ‘bdb -> replica_sources’ section; uid: Numeric unique identification of this source; uri: Source redis URI; compression: Compression level for the replication link; status: Sync status of this source; rdb_transferred: Number of bytes transferred from the source’s RDB during the syncing phase.; rdb_size: The source’s RDB size to be transferred during the syncing phase.; last_update: Time when we last receive an update from the source.; lag: Lag in millisec between source and destination (while synced).; last_error: Last error encountered when syncing from the source. |
| replica_sync | ‘enabled’ | Allow to enable, disable or pause syncing from specified replica_sources. See the ‘bdb -> replica_sync’ section |
| ‘disabled’ | ||
| ‘paused’ | ||
| ‘stopped’ | ||
| crdt_sync | ‘enabled’ | Allow to enable, disable or pause syncing from specified crdt_sources. Applicable only for CRDB bdb. See the ‘bdb -> replica_sync’ section |
| ‘disabled’ | ||
| ‘paused’ | ||
| ‘stopped’ | ||
| sync | ‘enabled’ | (deprecated, instead use replica_sync or crdt_sync) Allow to enable, disable or pause syncing from specified sync_sources. See the ‘bdb -> replica_sync’ section |
| ‘disabled’ | ||
| ‘paused’ | ||
| ‘stopped’ | ||
| bigstore_ram_weights | [{
"shard_uid": integer,
"weight": number
}, ...]
|
List of shard UIDs and their bigstore RAM weights; shard_uid: Shard UID; weight: Relative weight of RAM distribution |
| email_alerts | boolean (default: False) | Send email alerts for this DB |
| rack_aware | boolean (default: False) | Require the database to be always replicated across multiple racks |
| proxy_policy | ‘single’ | The default policy used for proxy binding to endpoints |
| ‘all-master-shards’ | ||
| ‘all-nodes’ | ||
| use_nodes | array of string | Cluster node uids to use for bdb’s shards and bound endpoints |
| avoid_nodes | array of string | Cluster node uids to avoid when placing the bdb’s shards and binding its endpoints |
| endpoint | string | Latest bound endpoint. Used when reconfiguring an endpoint via update |
| wait_command | boolean (default: True) | Support Redis wait command. (read-only) |
| background_op | [{
"status": string,
"name": string,
"error": object,
"progress": number
}, ...]
|
(read-only); progress: Percent of completed steps in current operation |
| module_list | [{
"module_id": string,
"module_args": [u'string', u'null'],
"module_name": string,
"semantic_version": string
}, ...]
|
List of modules associated with database.; module_id: Module UID; module_args: Module command line arguments (pattern does not allow special characters &,<,>,”); module_name: Module’s name; semantic_version: Module’s semantic version |
| crdt | boolean (default: False) | Use CRDT-based data types for multi- master replication |
| crdt_replica_id | integer | Local replica-id, for internal use only. |
| crdt_replicas | string | Replica-set configuration, for internal use only. |
| crdt_ghost_replica_ids | string | Removed replicas IDs, for internal use only. |
| crdt_causal_consistency | boolean (default: False) | Causal consistent CRDB. |
| crdt_syncer_auto_oom_unlatch | boolean (default: True) | Syncer automatically attempts to recover synchronisation from peers after this BDB got Out-Of-Memory. Otherwise, the syncer exits |
| crdt_config_version | integer | Replica-set configuration version, for internal use only. |
| crdt_protocol_version | integer | CRDB active Protocol version |
| crdt_featureset_version | integer | CRDB active FeatureSet version |
| crdt_guid | string | GUID of CRDB this bdb is part of, for internal use only. |
| slave_ha | boolean | Enable slave high availability mechanism for this bdb. default takes the cluster setting. |
| slave_ha_priority | integer | Priority of the BDB in slave high availability mechanism. |
| skip_import_analyze | ‘enabled’ | Enable/disable skipping the analysis stage when importing an RDB file |
| ‘disabled’ | ||
| mkms | boolean (default: True) | Are MKMS (Multi Key Multi Slots) commands supported? |
| account_id | integer | SM account ID |
| mtls_allow_weak_hashing | boolean | An optional mTLS relaxation flag for certs verification |
| mtls_allow_outdated_certs | boolean | An optional mTLS relaxation flag for certs verification |
| metrics_export_all | boolean | Enable/Disable exposing all shard metrics through the metrics exporter |
| replica_sync_dist | boolean | Enable/Disable distributed syncer in replica-of |
| crdt_sync_dist | boolean | Enable/Disable distributed syncer in master-master |
| syncer_mode | ‘distributed’ | The syncer for replication between database instances is either on a single node (centralized) or on each node that has a proxy according to the proxy policy (distributed). (read-only) |
| ‘centralized’ | ||
| generate_text_monitor | boolean | Enable/Disable generation of syncer monitoring information |
| repl_backlog_size | string | Redis replication backlog size (‘auto’ or size in bytes) |
| crdt_repl_backlog_size | string | Active-Active replication backlog size (‘auto’ or size in bytes) |
syncer_sources¶
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Numeric unique identification of this source |
| uri | string | Source redis URI |
| compression | integer, 0-6 | Compression level for the replication link |
| encryption | boolean | Encryption enabled / disabled |
| server_cert | string | Server certificate to use if encryption is enabled |
| client_cert | string | Client certificate to use if encryption is enabled |
| client_key | string | Client key to use if encryption is enabled |
| status | string | Sync status of this source |
| replication_tls_sni | string | Replication TLS server name indication |
| rdb_transferred | integer | Number of bytes transferred from the source’s RDB during the syncing phase. |
| rdb_size | integer | The source’s RDB size to be transferred during the syncing phase. |
| last_update | string | Time when we last receive an update from the source. |
| lag | integer | Lag in millisec between source and destination (while synced). |
| last_error | string | Last error encountered when syncing from the source. |
snapshot_policy¶
| Name | Type/Value | Description |
|---|---|---|
| secs | integer | |
| writes | integer |
bdb_group¶
An API object that represents a group of databases that share a memory pool.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Cluster unique ID of the database group. |
| memory_size | integer | The common memory pool size limit for all datbases in the group, expressed in bytes |
| members | array of string | A list of uids of member databases (read-only) |
bootstrap¶
An bootstrap configuration object.
| Name | Type/Value | Description |
|---|---|---|
| action | ‘recover_cluster’ | Action to perform |
| recovery_filename | string | Name of backup file to recover from |
| node | object node_identity | Node description. |
| or: | ||
| action | ‘join_cluster’ | Action to perform |
| ‘create_cluster’ | ||
| max_retries | integer | Max. number of retries in case of recoverable errors. |
| retry_time | integer | Max. waiting time, in seconds, between retries. |
| dns_suffixes | [{
"name": string,
"cluster_default": boolean,
"use_aaaa_ns": boolean,
"use_internal_addr": boolean,
"slaves": array
}, ...]
|
Explicit configuration of DNS suffixes; name: DNS suffix name; cluster_default: Should this suffix be the default cluster suffix; use_aaaa_ns: Should AAAA records be published for NS records; use_internal_addr: Should internal cluster IPs be published for databases; slaves: List of slave servers that should be published as NS and notified |
| license | string | License string |
| cluster | object cluster_identity | Cluster to join or create. |
| credentials | object credentials | Cluster admin credentials. |
| node | object node_identity | Node description. |
| policy | object policy | Policy object. |
| cnm_https_port | integer | Port to join a cluster with non-default cnm_https port |
| required_version | string | This node can join the cluster only if all nodes in the cluster are of version greater than the required_version |
credentials¶
| Name | Type/Value | Description |
|---|---|---|
| username | string | Admin username (pattern does not allow special characters &,<,>,”) |
| password | string | Admin password |
cluster_identity¶
| Name | Type/Value | Description |
|---|---|---|
| name | string | Fully qualified cluster name. Limited to 64 characters and must comply with the IETF’s RFC 952 standard and section 2.1 of the RFC 1123 standard. |
| nodes | array of string | Array of IP addresses of existing cluster nodes. |
| wait_command | boolean (default: True) | Support Redis wait command |
node_identity¶
| Name | Type/Value | Description |
|---|---|---|
| identity | object identity | Node identity. |
| limits | object limits | Node limits. |
| bigstore_driver | ‘ibm-capi-ga1’ | Bigstore driver name or none |
| ‘ibm-capi-ga2’ | ||
| ‘ibm-capi-ga4’ | ||
| ‘rocksdb’ | ||
| paths | object paths | Storage paths object. |
paths¶
| Name | Type/Value | Description |
|---|---|---|
| ephemeral_path | string | Ephemeral storage path. |
| bigstore_path | string | Bigredis storage path. |
| persistent_path | string | Persistent storage path. |
| ccs_persistent_path | string | Persistent storage path of ccs. |
identity¶
| Name | Type/Value | Description |
|---|---|---|
| name | string | Node’s name. |
| uid | integer | Assumed node’s uid, for cluster joining. Used to replace a dead node with a new one. |
| rack_id | string | Rack id, overrides cloud config. |
| override_rack_id | boolean | When replacing an existing node in a rack aware cluster, allows the new node to be located in a different rack. |
| addr | string | Internal IP address of node |
| external_addr | complex object | External IP addresses of node. GET /jsonschema to retrieve the object’s structure. |
| accept_servers | boolean (default: True) | If True no shards will be created on the node |
limits¶
| Name | Type/Value | Description |
|---|---|---|
| max_redis_servers | integer (default: 100) | Max. allowed redis servers on node. |
| max_listeners | integer (default: 100) | Max. allowed listeners on node. |
policy¶
| Name | Type/Value | Description |
|---|---|---|
| rack_aware | boolean | Cluster rack awareness. |
| default_sharded_proxy_policy | ‘single’ | Default proxy_policy for newly-created sharded databases’ endpoints |
| ‘all-master-shards’ | ||
| ‘all-nodes’ | ||
| default_non_sharded_proxy_policy | ‘single’ | Default proxy_policy for newly-created non sharded databases’ endpoints |
| ‘all-master-shards’ | ||
| ‘all-nodes’ | ||
| default_shards_placement | ‘sparse’ | Default shards_placement for newly- created databases |
| ‘dense’ | ||
| shards_overbooking | boolean (default: True) | If true, all bdbs’ memory_size is ignored during shards placement |
| default_fork_evict_ram | boolean (default: False) | If true, the bdb’s should evict data from ram in order to succeed replication or persistency |
check_result¶
Cluster check result
| Name | Type/Value | Description |
|---|---|---|
| cluster_test_result | boolean | Indication if any one of the tests failed |
| nodes | [{
"node_uid": integer,
"result": boolean,
"error": string
}, ...]
|
Nodes results |
cluster¶
An API object that represents the cluster.
| Name | Type/Value | Description |
|---|---|---|
| name | string | Cluster’s fully qualified domain name (read-only) |
| created_time | string | Cluster creation date (read-only) |
| rack_aware | boolean | Cluster operates in a rack-aware mode (read-only) |
| default_sharded_proxy_policy | string (default: all-master-shards) | Default proxy_policy for newly-create sharded databases’ endpoints (read-only) |
| default_non_sharded_proxy_policy | string (default: single) | Default proxy_policy for newly-create non sharded databases’ endpoints (read- only) |
| alert_settings | object alert_settings | Cluster and node alert settings |
| smtp_host | string | SMTP server to use for automated emails |
| smtp_port | integer | SMTP server port for automated emails |
| smtp_username | string | SMTP server username (pattern does not allow special characters &,<,>,”) |
| smtp_password | string | SMTP server password |
| email_from | string | Sender email for automated emails |
| smtp_use_tls | boolean (default: False) | Deprecated, please use smtp_tls_mode field instead. Use TLS for SMTP access |
| smtp_tls_mode | ‘none’ | Specifcies if and what TLS mode to use for SMTP access |
| ‘tls’ | ||
| ‘starttls’ | ||
| email_alerts | boolean (default: False) | Send node/clsuter email alerts. Requires valid SMTP and email_from settings. |
| crdt_rest_client_timeout | integer | Timeout for REST client used by the Active-Active management API. |
| crdt_rest_client_retries | integer | Maximum number of retries for REST client used by the Active-Active management API. |
| wait_command | boolean (default: True) | Support Redis wait command (read-only) |
| password_complexity | boolean (default: False) | Enforce password complexity policy. |
| password_expiration_duration | integer (default: 0) | The number of days a password is valid until the user is required to replace it. |
| use_ipv6 | boolean (default: True) | Should redislabs services listen on ipv6. |
| cm_port | integer, 1024-65535 | UI HTTPS listening port. |
| cnm_http_port | integer, 1024-65535 | API HTTP listening port. |
| cnm_https_port | integer, 1024-65535 | API HTTPS listening port. |
| handle_redirects | boolean (default: False) | Handle API HTTPS requests redirect to master node internally. |
| http_support | boolean (default: False) | Decide whether to enable or disable HTTP support |
| debuginfo_path | string | Path to a local directory used when generating support packages. |
| saslauthd_ldap_conf | string | saslauthd ldap configuration. |
| proxy_certificate | string | Cluster’s proxy certificate. |
| syncer_certificate | string | Cluster’s syncer certificate. |
| cluster_ssh_public_key | string | Cluster’s auto-generated ssh public key |
| proxy_max_ccs_disconnection_time | integer | Cluster-wide proxy timeout policy between proxy and CCS |
| min_control_TLS_version | ‘1’ | The minimum version of TLS protocol which is supported at the control path |
| ‘1.1’ | ||
| ‘1.2’ | ||
| ‘1.3’ | ||
| min_data_TLS_version | ‘1’ | The minimum version of TLS protocol which is supported at the data path. |
| ‘1.1’ | ||
| ‘1.2’ | ||
| min_sentinel_TLS_version | ‘1’ | The minimum version of TLS protocol which is supported at the data path. |
| ‘1.1’ | ||
| ‘1.2’ | ||
| slave_ha | boolean (default: False) | Enable slave high availability mechanism. (read-only) |
| slave_ha_grace_period | integer (default: 900) | Time in seconds between when a node fails, and when slave high availability mechanism starts relocating shards. (read-only) |
| slave_ha_cooldown_period | integer (default: 3600) | Time in seconds between runs of slave high availability mechanism, on different nodes. (read-only) |
| slave_ha_bdb_cooldown_period | integer (default: 86400) | Time in seconds between runs of slave high availability mechanism, on different nodes, on the same database. (read-only) |
| upgrade_mode | boolean (default: False) | Is cluster currently in upgrade mode. |
| sentinel_ssl_policy | ‘required’ | Is ssl for the Discovery Service required/disabled/allowed |
| ‘disabled’ | ||
| ‘allowed’ | ||
| slowlog_in_sanitized_support | boolean | Whether to include slowlogs in the sanitized support package |
| s3_url | string | Specifies the URL for S3 export and import |
| cm_session_timeout_minutes | integer (default: 15) | The timeout (in minutes) for the session to the CM |
| envoy_max_downstream_connections | integer, 100-2048 | The max downstream connections envoy is allowed to open |
| control_cipher_suites | string | Specifies the enabled ciphers for the control plane. The ciphers are specified in the format understood by the BoringSSL library. |
| data_cipher_list | string | Specifies the enabled ciphers for the data plane. The ciphers are specified in the format understood by the OpenSSL library. |
| sentinel_cipher_suites | array | Specifies the list of enabled ciphers for the sentinel service. The supported ciphers are ones that were implemented by the https://golang.org/src/crypto/tls /cipher_suites.go package. |
alert_settings¶
| Name | Type/Value | Description |
|---|---|---|
| node_failed | boolean (default: False) | Node failed |
| node_insufficient_disk_aofrw | boolean (default: False) | Insufficient AOF disk space |
| node_checks_error | boolean (default: False) | Some node checks have failed |
| node_aof_slow_disk_io | boolean (default: False) | AOF reaching disk I/O limits |
| node_memory | object cluster_alert_settings_with_threshold | Node memory has reached the threshold value [% of the memory limit] |
| node_persistent_storage | object cluster_alert_settings_with_threshold | Node persistent storage has reached the threshold value [% of the storage limit] |
| node_ephemeral_storage | object cluster_alert_settings_with_threshold | Node ephemeral storage has reached the threshold value [% of the storage limit] |
| node_free_flash | object cluster_alert_settings_with_threshold | Node flash storage has reached the threshold value [% of the storage limit] |
| node_cpu_utilization | object cluster_alert_settings_with_threshold | Node cpu utilization has reached the threshold value [% of the utilization limit] |
| node_net_throughput | object cluster_alert_settings_with_threshold | Node network throughput has reached the threshold value [bytes/s] |
| node_internal_certs_about_to_expire | object cluster_alert_settings_with_threshold | Internal certificate on node will expire in [x] days |
| cluster_certs_about_to_expire | object cluster_alert_settings_with_threshold | Cluster certificate will expire in [x] days |
| cluster_ram_overcommit | boolean (default: False) | RAM committed to databases is larger than cluster total RAM |
| cluster_flash_overcommit | boolean (default: False) | Flash committed to databases is larger than cluster total flash |
| cluster_too_few_nodes_for_replication | boolean (default: False) | Replication requires at least 2 nodes in cluster |
| cluster_even_node_count | boolean (default: False) | True high availability requires odd number of nodes in cluster |
| cluster_multiple_nodes_down | boolean (default: False) | Multiple cluster nodes are down - this might cause a data loss |
| cluster_inconsistent_rl_sw | boolean (default: False) | Not all nodes in cluster are running the same Redis Labs software version |
| cluster_inconsistent_redis_sw | boolean (default: False) | Not all shards in cluster are running the same Redis software version |
| cluster_internal_bdb | boolean (default: False) | Issues with internal cluster databases |
| cluster_node_joined | boolean (default: False) | New node joined cluster |
| cluster_node_remove_completed | boolean (default: False) | Node removed from cluster |
| cluster_node_remove_failed | boolean (default: False) | Failure to removed node from cluster |
| cluster_node_remove_abort_completed | boolean (default: False) | Abort node remove operation completed |
| cluster_node_remove_abort_failed | boolean (default: False) | Abort node remove operation failed |
cluster_alert_settings_with_threshold¶
| Name | Type/Value | Description |
|---|---|---|
| enabled | boolean (default: False) | Alert enabled or disabled |
| threshold | string | Threshold for alert going on/off |
cluster_settings¶
Cluster Resources Management Policy
| Name | Type/Value | Description |
|---|---|---|
| shards_overbooking | boolean | |
| default_non_sharded_proxy_policy | ‘single’ | |
| ‘all-master-shards’ | ||
| ‘all-nodes’ | ||
| default_sharded_proxy_policy | ‘single’ | |
| ‘all-master-shards’ | ||
| ‘all-nodes’ | ||
| default_shards_placement | ‘dense’ | |
| ‘sparse’ | ||
| default_fork_evict_ram | boolean | |
| default_provisioned_redis_version | string | |
| redis_migrate_node_threshold | integer | |
| bigstore_migrate_node_threshold | integer | |
| redis_migrate_node_threshold_p | integer | |
| bigstore_migrate_node_threshold_p | integer | |
| redis_provision_node_threshold | integer | |
| bigstore_provision_node_threshold | integer | |
| redis_provision_node_threshold_p | integer | |
| bigstore_provision_node_threshold_p | integer | |
| max_simultaneous_backups | integer | |
| slave_ha | boolean | |
| slave_ha_grace_period | integer | |
| slave_ha_cooldown_period | integer | |
| slave_ha_bdb_cooldown_period | integer | |
| parallel_shards_upgrade | integer | |
| show_internals | boolean | |
| login_lockout_threshold | integer | |
| login_lockout_duration | integer | |
| login_lockout_counter_reset_after | integer | |
| default_concurrent_restore_actions | integer | |
| endpoint_rebind_propagation_grace_time | integer | |
| max_saved_events_per_type | integer | |
| data_internode_encryption | boolean | |
| rack_aware | boolean | |
| redis_upgrade_policy | ‘major’ | |
| ‘latest’ |
db_alerts_settings¶
An API object that represents the database alerts configuration.
| Name | Type/Value | Description |
|---|---|---|
| bdb_backup_delayed | object bdb_alert_settings_with_threshold | Periodic backup has been delayed for longer than specified threshold value [minutes] |
| bdb_high_latency | object bdb_alert_settings_with_threshold | Latency is higher than specified threshold value [micro-sec] |
| bdb_high_throughput | object bdb_alert_settings_with_threshold | Throughput is higher than specified threshold value [requests / sec.] |
| bdb_low_throughput | object bdb_alert_settings_with_threshold | Throughput is lower than specified threshold value [requests / sec.] |
| bdb_size | object bdb_alert_settings_with_threshold | Dataset size has reached the threshold value [% of the memory limit] |
| bdb_ram_dataset_overhead | object bdb_alert_settings_with_threshold | Dataset RAM overhead of a shard has reached the threshold value [% of its RAM limit] |
| bdb_ram_values | object bdb_alert_settings_with_threshold | Percent of values kept in a shard’s RAM is lower than [% of its key count] |
| bdb_shard_num_ram_values | object bdb_alert_settings_with_threshold | Number of values kept in a shard’s RAM is lower than [values] |
| bdb_high_syncer_lag | object bdb_alert_settings_with_threshold | (Deprecated) Replica of - sync lag is higher than specified threshold value [seconds] |
| bdb_syncer_connection_error | object bdb_alert_settings_with_threshold | (Deprecated) Replica of - sync has connection error while trying to connect replica source |
| bdb_syncer_general_error | object bdb_alert_settings_with_threshold | (Deprecated) Replica of - sync encountered in general error |
| bdb_replica_src_high_syncer_lag | object bdb_alert_settings_with_threshold | Replica-of source - sync lag is higher than specified threshold value [seconds] |
| bdb_replica_src_syncer_connection_error | object bdb_alert_settings_with_threshold | Replica-of source - sync has connection error while trying to connect replica source |
| bdb_replica_src_syncer_general_error | object bdb_alert_settings_with_threshold | Replica-of - sync encountered in general error |
| bdb_crdt_src_high_syncer_lag | object bdb_alert_settings_with_threshold | CRDB source - sync lag is higher than specified threshold value [seconds] |
| bdb_crdt_src_syncer_connection_error | object bdb_alert_settings_with_threshold | CRDB source - sync has connection error while trying to connect replica source |
| bdb_crdt_src_syncer_general_error | object bdb_alert_settings_with_threshold | CRDB - sync encountered in general error |
| bdb_long_running_action | object bdb_alert_settings_with_threshold | An alert for state-machines that are running for too long |
bdb_alert_settings_with_threshold¶
| Name | Type/Value | Description |
|---|---|---|
| enabled | boolean (default: False) | Alert enabled or disabled |
| threshold | string | Threshold for alert going on/off |
db_command¶
An object representing a generic Redis command.
| Name | Type/Value | Description |
|---|---|---|
| command | string | Redis command. |
| args | array of string | Command arguments. |
definitions¶
job_scheduler¶
An API object that represents the job_scheduler settings in the cluster.
| Name | Type/Value | Description |
|---|---|---|
| backup_job_settings | object backup_job_settings | Backup job settings |
| redis_cleanup_job_settings | object redis_cleanup_job_settings | Redis cleanup job settings |
| node_checks_job_settings | object node_checks_job_settings | Node checks job settings |
| log_rotation_job_settings | object log_rotation_job_settings | Log rotation job settings |
| rotate_ccs_job_settings | object rotate_ccs_job_settings | Rotate CCS job settings |
| cert_rotation_job_settings | object cert_rotation_job_settings | Job settings of internal certificate rotation |
cert_rotation_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string | |
| expiry_days_before_rotation | integer, 1-90 (default: 60) | Number of days before a certificate expires before we rotate it |
rotate_ccs_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string | |
| file_suffix | string (default: 5min) | String added to the end of the rotated rdb files |
| rotate_max_num | integer, 1-100 (default: 24) | The maximum number of saved rdb files |
log_rotation_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string |
node_checks_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string |
backup_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string |
redis_cleanup_job_settings¶
| Name | Type/Value | Description |
|---|---|---|
| cron_expression | string |
jwt_authorize¶
User authentication or JW token refresh request to REST API
| Name | Type/Value | Description |
|---|---|---|
| username | string | |
| password | string | |
| ttl | integer, 1-86400 (default: 300) | Time To Live - The amount of time in seconds the token will be valid |
ldap¶
An API object that represents the cluster’s LDAP configuration.
| Name | Type/Value | Description |
|---|---|---|
| control_plane | boolean (default: False) | Whether to use LDAP for user authentication/authorization in the control-plane |
| data_plane | boolean (default: False) | Whether to use LDAP for user authentication/authorization in the data-plane |
| uris | array of string | URIs of LDAP servers containing only the schema, the host, and the port |
| starttls | boolean (default: False) | Whether to use StartTLS negotiation for the LDAP connection |
| ca_cert | string | A PEM-encoded CA certificate(s) to use for validating TLS connections to the LDAP server |
| bind_dn | string | A DN to use when binding with the LDAP server to run queries |
| bind_pass | string | A password to use when binding with the LDAP server to run queries |
| user_dn_template | string | A string template that maps between the username provided to the cluster for authentication, and the LDAP DN. The special substring “%u” shall be replaced with the username. (Mutually exclusive with “user_dn_query”) |
| user_dn_query | complex object | An LDAP search for mapping from a username to a user DN. The special substring “%u” in the filter shall be replaced with the username. (Mutually exclusive with “user_dn_template”) |
| dn_group_attr | string | The name of an attribute of the LDAP user entity that contains a list of the groups that user belongs to. (Mutually exclusive with “dn_group_query”) |
| dn_group_query | complex object | An LDAP search for mapping from a user DN to the groups the user is a member of. The special substring “%D” in the filter shall be replaced with the user’s DN. (Mutually exclusive with “dn_group_attr”) |
| cache_ttl | integer (default: 300) | Maximum TTL of cached entries, in seconds |
ldap_mapping¶
An API object that represents aan LDAP-mapping object
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | LDAP-mapping’s unique uid. |
| name | string | Role’s name |
| dn | string | An LDAP group’s distinguished name |
| string | email address that (if set) is used for alerts | |
| email_alerts | boolean (default: True) | Activate email alerts for an associated email. |
| bdbs_email_alerts | complex object | UIDs of databases that associated email will receive alerts for. |
| cluster_email_alerts | boolean | Activate cluster email alerts for an associated email. |
| role_uids | array of integer | List of role uids associated with the LDAP group |
| account_id | integer | SM account ID |
| action_uid | string | Action uid. If exists - progress can be tracked by the GET /actions/<uid> API (read-only) |
module¶
Represents a Redis module
| Name | Type/Value | Description |
|---|---|---|
| uid | string | Cluster unique ID of module |
| architecture | string | Module was compiled under this architecture |
| os | string | OS on which this module was compiled on |
| os_list | array of string | List of OSes the module supports |
| display_name | string | Name of module for display purposes |
| author | string | Who created this module |
| command_line_args | string | Command line arguments passed to the module |
| config_command | string | Name of command to configure module arguments at runtime |
| description | string | Short description of the module |
| string | Author’s email address | |
| homepage | string | Module’s Homepage |
| license | string | Module is distributed under this license |
| min_redis_version | string | Minimum Redis version required by this module |
| min_redis_pack_version | string | Minimum redis pack version required by this module |
| module_file | string | Module file name |
| module_name | string | Module’s name |
| sha256 | string | SHA256 of module binary |
| version | integer | Module’s version |
| semantic_version | string | Module’s semantic version |
| capabilities | array of string | List of capabilities supported by this module |
| is_bundled | boolean | Whether module came bundled with a version of Redis Enterprise |
| dependencies | object dependencies | Module dependencies |
node¶
An API object that represents a node in the cluster.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Cluster unique ID of node (read-only) |
| status | ‘active’ | Node status (read-only) |
| ‘provisioning’ | ||
| ‘decommissioning’ | ||
| ‘down’ | ||
| addr | string | Internal IP address of node |
| external_addr | complex object | External IP addresses of node. GET /jsonschema to retrieve the object’s structure. |
| public_addr | string | Public IP address of node |
| total_memory | integer | Total memory of node (bytes) (read-only) |
| cores | integer | Total number of CPU cores (read-only) |
| architecture | string | Hardware architecture (read-only) |
| bigstore_driver | ‘ibm-capi-ga1’ | Bigstore driver name or none |
| ‘ibm-capi-ga2’ | ||
| ‘ibm-capi-ga4’ | ||
| ‘rocksdb’ | ||
| bigstore_size | integer | Storage size of bigstore storage (read- only) |
| bigredis_storage_path | string | Flash storage path (read-only) |
| ephemeral_storage_path | string | Ephemeral storage path (read-only) |
| ephemeral_storage_size | number | Ephemeral storage size (bytes) (read- only) |
| persistent_storage_path | string | Persistent storage path (read-only) |
| persistent_storage_size | number | Persistent storage size (bytes) (read- only) |
| recovery_path | string | Recovery files path |
| software_version | string | Installed Redis Labs cluster software version (read-only) |
| supported_database_versions | [{
"db_type": string,
"version": string
}, ...]
|
Versions of open source databases supported by Redis Labs software on the node (read-only); db_type: Type of database; version: Version of database |
| shard_list | array of integer | Cluster unique IDs of all node shards. |
| os_version | string | Installed OS version (human readable) (read-only) |
| os_name | string | OS name only (read-only) |
| os_semantic_version | string | Full version number (read-only) |
| shard_count | integer | Number of shards on the node (read-only) |
| uptime | integer | System uptime (seconds) (read-only) |
| system_time | string | System time (UTC) (read-only) |
| rack_id | string | Rack ID where node is installed |
| accept_servers | boolean (default: True) | If True no shards will be created on the node |
| max_redis_servers | integer | Maximal number of shards on the node |
| max_listeners | integer | Maximal number of listeners on the node |
proxy¶
An API object that represents a proxy in the cluster.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | unique ID of proxy (read-only) |
| threads | integer, 1-256 | Number of threads. |
| max_threads | integer, 1-256 | Max number of threads. |
| dynamic_threads_scaling | boolean | |
| threads_usage_threshold | integer, 50-99 | Max number of threads. |
| duration_usage_threshold | integer, 10-300 | Max number of threads. |
| backlog | integer | tcp listen queue backlog. |
| conns | integer | Number of connections. |
| client_keepcnt | integer | Client tcp keepalive count. |
| client_keepidle | integer | Client tcp keepalive idle. |
| client_keepintvl | integer | Client tcp keepalive interval. |
| max_servers | integer | Max. number of redis servers. |
| max_listeners | integer | Max. number of listeners. |
| max_worker_client_conns | integer | Max. client conns per thread. |
| max_worker_server_conns | integer | Max. server conns per thread. |
| max_worker_txns | integer | Max. in-flight transactions per thread. |
| ignore_bdb_cconn_limit | boolean | ignore client connection limits. |
| ignore_bdb_cconn_output_buff_limits | boolean | Ignore buffer limit. |
redis_acl¶
An API object that represents a RedisACL object
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Object’s unique uid. |
| name | string | Redis ACL’s name |
| acl | string | Redis’ ACL’s string |
| account_id | integer | SM account ID |
| action_uid | string | Action uid. If exists - progress can be tracked by the GET /actions/<uid> API (read-only) |
role¶
An API object that represents a role.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | Role’s unique uid. |
| name | string | Role’s name |
| management | ‘none’ | Management role |
| ‘db_viewer’ | ||
| ‘cluster_viewer’ | ||
| ‘db_member’ | ||
| ‘cluster_member’ | ||
| ‘admin’ | ||
| account_id | integer | SM account ID |
| action_uid | string | Action uid. If exists - progress can be tracked by the GET /actions/<uid> API (read-only) |
services_configuration¶
Cluster optional services settings
| Name | Type/Value | Description |
|---|---|---|
| mdns_server | object mdns_server | Whether to enable/disable the Multicast DNS server |
| cm_server | object cm_server | Whether to enable/disable the CM server |
| stats_archiver | object stats_archiver | Whether to enable/disable the stats archiver service |
| saslauthd | object saslauthd | Whether to enable/disable the saslauthd service |
| pdns_server | object pdns_server | Whether to enable/disable the pdns server |
| crdb_coordinator | object crdb_coordinator | Whether to enable/disable the crdb coordinator process |
| crdb_worker | object crdb_worker | Whether to enable/disable the crdb worker processes |
pdns_server¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
mdns_server¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
crdb_coordinator¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
cm_server¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
stats_archiver¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
crdb_worker¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
saslauthd¶
| Name | Type/Value | Description |
|---|---|---|
| operating_mode | ‘disabled’ | |
| ‘enabled’ |
shard¶
An API object that represents a Redis shard in in a bdb.
| Name | Type/Value | Description |
|---|---|---|
| uid | string | Cluster unique ID of shard. |
| status | ‘active’ | The current status of the shard |
| ‘inactive’ | ||
| ‘trimming’ | ||
| detailed_status | ‘ok’ | A more specific status of the shard |
| ‘importing’ | ||
| ‘timeout’ | ||
| ‘loading’ | ||
| ‘busy’ | ||
| ‘down’ | ||
| ‘trimming’ | ||
| ‘unknown’ | ||
| bdb_uid | integer | The ID of bdb this shard belongs to. |
| node_uid | string | The ID of the node this shard is located on. |
| role | ‘master’ | Role of this shard (master or slave) |
| ‘slave’ | ||
| assigned_slots | string | Shards hash slot range |
| bigstore_ram_weight | number | Shards RAM distribution weight |
| sync | object sync | Indication of the shard’s current sync status and progress |
| loading | object loading | Current status of dump file loading |
| backup | object backup | Current status of dump file loading |
| report_timestamp | string | The time in which the shard’s info was collected (read-only) |
| redis_info | object redis_info | A sub-dictionary of Redis INFO command. see https://redis.io/commands/info for detailed documentation |
loading¶
| Name | Type/Value | Description |
|---|---|---|
| status | ‘in_progress’ | Indication if the load of a dump file is on-going (read-only) |
| ‘idle’ | ||
| progress | number, 0-100 | Percentage of bytes already loaded. |
backup¶
| Name | Type/Value | Description |
|---|---|---|
| status | ‘exporting’ | Status of scheduled periodic backup process |
| ‘succeeded’ | ||
| ‘failed’ | ||
| progress | number, 0-100 | Shard backup progress (percentage) |
sync¶
| Name | Type/Value | Description |
|---|---|---|
| status | ‘in_progress’ | Indication of the shard’s current sync status |
| ‘idle’ | ||
| ‘link_down’ | ||
| progress | integer | Number of bytes remaining in current sync |
suffix¶
An API object that represents a DNS suffix in the cluster.
| Name | Type/Value | Description |
|---|---|---|
| name | string | Suffix name, unique and represents its zone (read-only) |
| mdns | boolean | Support for Multicast DNS (read-only) |
| internal | boolean | Does the Suffix point on internal ip addresses (read-only) |
| default | boolean | Suffix is default suffix for the cluster (read-only) |
| use_aaaa_ns | boolean | Suffix uses AAAA NS entries (read-only) |
| slaves | array of string | Frontend DNS servers that are to be updated by this suffix |
user¶
An API object that represents an RLEC user.
| Name | Type/Value | Description |
|---|---|---|
| uid | integer | User’s unique uid. |
| string | User’s email. (pattern matching only ascii characters) | |
| password | string | User’s password. Note that it could also be an already-hashed value, in which case ‘password_hash_method’ parameter is also provided. |
| name | string | User’s name. (pattern does not allow non ascii and special characters &,<,>,”) |
| email_alerts | boolean (default: True) | Activate email alerts for a user. |
| bdbs_email_alerts | complex object | UIDs of databases that user will receive alerts for. |
| cluster_email_alerts | boolean | Activate cluster email alerts for a user. |
| role | ‘admin’ | User’s role. |
| ‘cluster_member’ | ||
| ‘db_viewer’ | ||
| ‘db_member’ | ||
| ‘cluster_viewer’ | ||
| ‘none’ | ||
| auth_method | ‘regular’ | User’s authentication method. |
| ‘external’ | ||
| password_hash_method | ‘1’ | Used when password is passed pre-hashed to specify the hashing method |
| password_issue_date | string | The date in which the password was set . (read-only) |
| role_uids | array of integer | List of role uids associated with the LDAP group |
| account_id | integer | SM account ID |
| action_uid | string | Action uid. If exists - progress can be tracked by the GET /actions/<uid> API (read-only) |
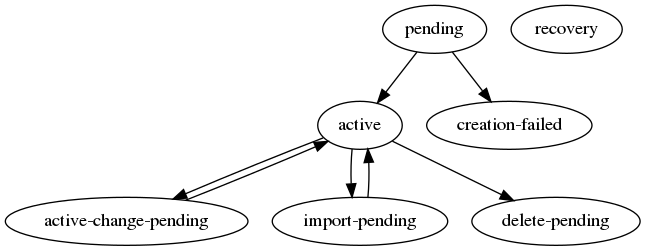
bdb -> status¶
The bdb status field is a read-only field representing database status and can have one of the following possible values:
- ‘pending’: temporary status while the database is initially created
- Can change to:
- ‘active’
- ‘creation-failed’
- ‘creation-failed’ - status if the initial database creation failed
- Can change to:
- N/A
- ‘active’ - status when the database is active and no special action it taking place
- Can change to:
- ‘active-change-pending’
- ‘import-pending’
- ‘delete-pending’
- ‘active-change-pending’
- Can change to:
- ‘active’
- ‘import-pending’ - status while a dataset import is taking place
- Can change to:
- ‘active’
- ‘delete-pending’ - status while the database is being deleted
- Can change to:
- Not applicable
- ‘recovery’ - not relevant, intended for future use.
bdb -> replica_sync¶
The bdb replica_sync field is related to the “Replica of” feature which enables enables creating a Redis database (single or multi shard) that keeps synchronizing data from another Redis database (single or multi shard). You can read more about the replica of concepts, statuses, and errors, in the Replica of documentation.
The bdb crdt_sync field has a similar purpose for the Redis CRDB.
The field represents the replica of sync process and using it you can enable, disable or pause the process.
The bdb sync field can have one of the following possible values:
- ‘disabled’ - default value. Used to disable the sync process and represents that no sync is currently configured or running.
- Can change to:
- ‘enabled’
- ‘enabled’ - used to enable the sync process and represents that the process is currently active.
- Can change to:
- ‘stopped’
- ‘paused’
- ‘paused’ - used to pause the sync process and represents that the process is configured but is currently not executing the sync commands.
- Can change to:
- ‘enabled’
- ‘stopped’
- ‘stopped’ - represents that an unrecoverable error occurred in the sync process that caused the sync to be stopped by the system.
- Can change to:
- ‘enabled’
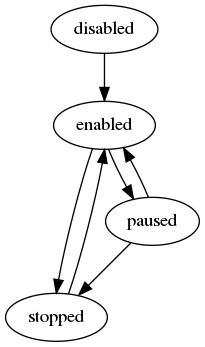
When the sync is in ‘stopped’ or ‘paused’ state, then the the last_error field in the relevant source entry in the sync_sources “status” field holds the specific error message.
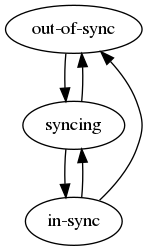
bdb -> replica_sources -> “status”¶
The status field is related to the “Replica of” feature which enables enables creating a Redis database (single or multi shard) that keeps synchronizing data from another Redis database (single or multi shard). You can read more about the replica of concepts, statuses, and errors, in the Replica of documentation.
The field represents the replica of sync process for a specific sync source and can have one of the following possible values:
- ’out-of-sync’ - temporary status when the sync process is disconnected from source and trying reconnect
- Can change to:
- ‘syncing’
- ‘syncing’ - temporary status when the sync process is running the initial sync and valid until the initial sync is done
- Can change to:
- ‘in-sync’
- ’out-of-sync’
- ‘in-sync’ - initial sync process finished successfully and currently new commands are syncing on a regular basis.
- Can change to:
- ‘syncing’
- ’out-of-sync’
bdb -> backup_location, bdbs/(int: uid)/actions/export -> export_location¶
You can backup or export a database’s dataset to one of the following location types:
- FTP/S
- Amazon S3
- Microsoft Azure Storage
- Google Cloud Storage
- OpenStack Object Storage (“Swift”)
- SFTP
- NAS/Local Storage
Each of these location types requires a different set of parameters to be sent.
First you need to define the location type by setting the “type” (string) field to one of the following possible values:.
- “url” - for FTP/S
- “s3” - for Amazon S3
- “abs” - for Microsoft Azure Storage
- “gs” - for Google Cloud Storage
- “swift” - OpenStack Object Storage (“Swift”)
- “sftp” - for SFTP
- “mount_point” - for NAS/Local Storage
Then, depending on the option you are using there is a different set of values you need to provide:
- FTP
- “url” (string) - a uri representing FTP/S location with the following format: ftp://user:password@host:port/path/. The user and password can be omitted if not needed.
- AWS S3
- “bucket_name” (string) - S3 bucket name
- “subdir” (string) - (Optional) Path to the backup directory in the S3 bucket
- “access_key_id” (string) - The AWS Access Key ID with access to the bucket
- “secret_access_key” (string) - The AWS Secret Access Key that matches the Access Key ID
- Azure Blob Storage
- “container” (string) - Blob Storage container name
- “subdir” (string) - (Optional) Path to the backup directory in the Blob Storage container
- “account_name” (string) - Storage account name with access to the container
- “account_key” (string) - Access key for the storage account
- Google Cloud Storage
- “bucket_name” (string) - Cloud Storage bucket name
- “subdir” (string) - (Optional) Path to the backup directory in the Cloud Storage bucket
- “client_id” (string) - Cloud Storage client ID with access to the Cloud Storage bucket
- “client_email” (string) - Email address for the Cloud Storage client ID
- “private_key_id” (string) - Cloud Storage private key ID with access to the Cloud Storage bucket
- “private_key” (string) - Cloud Storage private key that matches the private key ID
- Swift
- “auth_url” (string) - Swift service authentication URL.
- “user” (string) - Swift service username to use to access the storage.
- “key” (string) - Swift service key corresponding to the username to use to access the storage.
- “container” (string) - Swift object store container name to backup to.
- “prefix” (string) - (Optional) Swift path used a prefix for the file name for the backup files to be created.
- SFTP
- “sftp_url” (string) - SFTP URL in the format ‘sftp://user:password@host[:port][/path/]’). The default port number is 22 and the default path is ‘/’.
- “key” (string) - (Optional) SSH private key to secure the SFTP server connection. If you do not specify an SSH private key, the auto-generated private key of the cluster is used, and you must add the SSH public key of the cluster to the SFTP server configuration.
- NAS/Local Storage
- “path” (string) - Path to the local mount point. You must create the mount point on all nodes, and the redislabs:redislabs user must have read and write permissions on the local mount point.
bdbs/(int: uid)/actions/import -> dataset_import_sources¶
You can import data to a database from one of the following location types:
- HTTP/S
- FTP
- Amazon S3
- Microsoft Azure Storage
- Google Cloud Storage
- OpenStack Object Storage (“Swift”)
- SFTP
- NAS/Local Storage
Each of these location types requires a different set of parameters to be sent.
The file to import from should be in the RDB format. It can also be in a compressed (gz) RDB file. You can import data to a database from multiple files by supplying an array of the object described below.
First you need to define the location type by setting the “type” (string) field to one of the following possible values:.
- “url” - for FTP/S
- “s3” - for Amazon S3
- “abs” - for Microsoft Azure Storage
- “gs” - for Google Cloud Storage
- “swift” - OpenStack Object Storage (“Swift”)
- “sftp” - for SFTP
- “mount_point” - for NAS/Local Storage
Then, depending on the option you are using there is a different set of values you need to provide:
- FTP
- “url” (string) - a uri representing FTP/S location with the following format: ftp://user:password@host:port/path/. The user and password can be omitted if not needed.
- AWS S3
- “bucket_name” (string) - S3 bucket name
- “subdir” (string) - (Optional) Path to the backup directory in the S3 bucket
- “access_key_id” (string) - The AWS Access Key ID with access to the bucket
- “secret_access_key” (string) - The AWS Secret Access that matches the Access Key ID
- Azure Blob Storage
- “container” (string) - Blob Storage container name
- “subdir” (string) - (Optional) Path to the backup directory in the Blob Storage container
- “account_name” (string) - Storage account name with access to the container
- “account_key” (string) - Access key for the storage account
- Google Cloud Storage
- “bucket_name” (string) - Cloud Storage bucket name
- “subdir” (string) - (Optional) Path to the backup directory in the Cloud Storage bucket
- “client_id” (string) - Cloud Storage client ID with access to the Cloud Storage bucket
- “client_email” (string) - Email address for the Cloud Storage client ID
- “private_key_id” (string) - Cloud Storage private key ID with access to the Cloud Storage bucket
- “private_key” (string) - Private key for the Cloud Storage matching the private key ID
- Swift
- “auth_url” (string) - Swift service authentication URL.
- “user” (string) - Swift service username to use to access the storage.
- “key” (string) - Swift service key corresponding to the username to use to access the storage.
- “container” (string) - Swift object store container name holding the file to be imported.
- “objname” (string) - Swift object name (file name) of the file to be imported.
- “prefix” (string) - (Optional) Swift path used a prefix to the object name for the file be imported.
- SFTP
- “sftp_url” (string) - SFTP URL in the format of ‘sftp://user:password@host[:port]/path/filename.rdb’). The default port number is 22 and the default path is ‘/’.
- “key” (string) - (Optional) SSH private key to secure the SFTP server connection. If you do not specify an SSH private key, the auto-generated private key of the cluster is used, and you must add the SSH public key of the cluster to the SFTP server configuration.
- NAS/Local Storage
- “path” (string) - Path to the locally mounted file name to import. You must create the mount point on all nodes, and the redislabs:redislabs user must have read permissions on the local mount point.
Statistics¶
Statistics Overview¶
Statistics returned from API calls will always have the following fields:
- interval – a string the time interval represented in this result. This can be one of the following values: 1sec / 10sec / 5min / 15min / 1hour / 12hour / 1week.
- stime – a timestamp representing the beginning of the interval. Format is: “2015-05-27T12:00:00Z”.
- etime – a timestamp representing the end of the interval. Format is: “2015-05-27T12:00:00Z”.
The difference between the stime and the etime is equal to the interval.
In addition, there is a set of fields representing the values of the different metrics for this interval and object. The set of metrics relevant to each object is different, and listed below for each object type.
Optionally, you can pass an stime and/or an etime to the different GET stats calls. When provided, the returned results will fall within the range provided, meaning no earlier than the provided stime, and no later than the provided etime.
For each interval type (1sec / 10sec / 5min / 15min / 1hour / 12hour / 1week) there is a maximum number of samples (X) kept in the system, see the exact maximum number of values available for each interval type in the table below. These X samples are kept from the most current sample back.
The actual number of samples returned by a stats GET call can vary depending on the number of samples available in the system, and the number of samples that fall between stime and the etime, if provided. For example, if an object (Cluster / Node / DB / Shard) was just created, not all samples will be available yet, depending on how much time elapsed since creation. Or, if the stime and etime provided are pretty close, only samples that fall within this range, out of all the available samples, will be returned.
An exception to the above is that in order to reduce load generated by stats collection, for relatively inactive DBs or Shards (less than 5 ops/sec), 1sec stats are not collected at a 1sec interval. For those inactive DBs or shards 1sec stats are collected at a reduced interval of once every 2 to 5 seconds, but the same number of maximum number of samples (X) is kept.
Note: There are certain statistics that are returned from the API that are intended for internal use. These statistics are not documented below and should be ignored.
Note: There are certain statistics that are not always returned by the API, but are returned only when they are relevant, see more details in the specific statistics below. You should not expect all statistics to always be returned.
Maximum number of samples per interval¶
| Interval | Maximum available number of samples |
|---|---|
| 1sec | 10 |
| 10sec | 30 |
| 5min | 12 |
| 15min | 96 |
| 1hour | 168 |
| 12hour | 62 |
| 1week | 53 |
Object Metrics¶
Cluster Metrics
| Metric Name | Description | Type |
|---|---|---|
| free_memory | sum of free memory in all cluster nodes (bytes) | float |
| available_memory | sum of available_memory in all nodes (bytes) | float |
| provisional_memory | sum of provisional_memory in all nodes (bytes) | float |
| available_flash | sum of available_flash in all nodes (bytes) | float |
| provisional_flash | sum of provisional_flash in all nodes (bytes) | float |
| cpu_user | cpu time portion spent by users-pace processes on cluster, the value is weighted between all nodes based on number of cores in each node (0-1, multiply by 100 to get percent) | float |
| cpu_system | cpu time portion spent in kernel on cluster, the value is weighted between all nodes based on number of cores in each node (0-1, multiply by 100 to get percent) | float |
| cpu_idle | cpu idle time portion, , the value is weighted between all nodes based on number of cores in each node (0-1, multiply by 100 to get percent) | float |
| ephemeral_storage_avail | sum of disk space available to RLEC processes on configured ephemeral disk on all cluster nodes (bytes) | float |
| persistent_storage_avail | sum of disk space available to RLEC processes on configured persistent disk on all cluster nodes (bytes) | float |
| ephemeral_storage_free | sum of free disk space on configured ephemeral disk on all cluster nodes (bytes) | float |
| persistent_storage_free | sum of free disk space on configured persistent disk on all cluster nodes (bytes) | float |
| total_req | request rate handled by all endpoints on cluster (ops/sec) | float |
| avg_latency | average latency of requests handled by all cluster endpoints (micro-sec); returned only when there is traffic | float |
| conns | total number of clients connected to all cluster endpoints | float |
| ingress_bytes | sum of rate of incoming network traffic on all cluster nodes (bytes/sec) | float |
| egress_bytes | sum of rate of outgoing network traffic on all cluster nodes (bytes/sec) | float |
| bigstore_kv_ops | rate of value read/write operations against back-end flash for all shards which are part of a flash based DB (BigRedis) in cluster (ops/sec); returned only when BigRedis is enabled | float |
| bigstore_iops | rate of i/o operations against back-end flash for all shards which are part of a flash based DB (BigRedis) in cluster (ops/sec); returned only when BigRedis is enabled | float |
| bigstore_throughput | throughput i/o operations against back-end flash for all shards which are part of a flash based DB (BigRedis) in cluster (bytes/sec); returned only when BigRedis is enabled | float |
| bigstore_free | sum of free space of back-end flash (used by flash DB’s [BigRedis]) on all cluster nodes (bytes); returned only when BigRedis is enabled | float |
Node Metrics
| Metric Name | Description | Type |
|---|---|---|
| free_memory | free memory in node (bytes) | float |
| available_memory | available ram in node (bytes) | float |
| provisional_memory | amount of ram available for new shards on this node, taking into account overbooking, max redis servers, reserved memory and provision and migration thresholds (bytes) | float |
| available_flash | available flash in node (bytes) | float |
| provisional_flash | amount of flash available for new shards on this node, taking into account overbooking, max redis servers, reserved flash and provision and migration thresholds (bytes) | float |
| cpu_user | cpu time portion spent by users-pace processes (0-1, multiply by 100 to get percent) | float |
| cpu_system | cpu time portion spent in kernel (0-1, multiply by 100 to get percent) | float |
| cpu_idle | cpu idle time portion (0-1, multiply by 100 to get percent) | float |
| ephemeral_storage_avail | disk space available to RLEC processes on configured ephemeral disk (bytes) | float |
| persistent_storage_avail | disk space available to RLEC processes on configured persistent disk (bytes) | float |
| ephemeral_storage_free | free disk space on configured ephemeral disk (bytes) | float |
| persistent_storage_free | free disk space on configured persistent disk (bytes) | float |
| total_req | request rate handled by endpoints on node (ops/sec) | float |
| avg_latency | average latency of requests handled by endpoints on node (micro-sec); returned only when there is traffic | float |
| conns | number of clients connected to endpoints on node | float |
| ingress_bytes | rate of incoming network traffic to node (bytes/sec) | float |
| egress_bytes | rate of outgoing network traffic to node (bytes/sec) | float |
| bigstore_kv_ops | rate of value read/write operations against back-end flash for all shards which are part of a flash based DB (BigRedis) on node (ops/sec); returned only when BigRedis is enabled | float |
| bigstore_iops | rate of i/o operations against back-end flash for all shards which are part of a flash based DB (BigRedis) on node (ops/sec); returned only when BigRedis is enabled | float |
| bigstore_throughput | throughput of i/o operations against back-end flash for all shards which are part of a flash based DB (BigRedis) on node (bytes/sec); returned only when BigRedis is enabled | float |
| bigstore_free | free space of back-end flash (used by flash DB’s [BigRedis]) (bytes) returned only when BigRedis is enabled | float |
| cur_aof_rewrites | number of aof rewrites that are currently performed by shards on this node | float |
DB Metrics
| Metric Name | Description | Type | |
|---|---|---|---|
| no_of_keys | number of keys in DB | float | |
| no_of_expires | number of volatile keys in the DB | float | |
| evicted_objects | rate of key evictions from DB (evictions/sec) | float | |
| expired_objects | rate keys expired in DB (expirations/sec) | float | |
| instantaneous_ops_per_sec | request rate handled by all shards of DB (ops/sec) | float | |
| read_hits | rate of read operations accessing an existing key (ops/sec) | float | |
| read_misses | rate of read operations accessing a non-existing key (ops/sec) | float | |
| write_hits | rate of write operations accessing an existing key (ops/sec) | float | |
| write_misses | rate of write operations accessing a non- existing key (ops/sec) | float | |
| pubsub_channels | Count the pub/sub channels with subscribed clients. | float | |
| pubsub_patterns | Count the pub/sub patterns with subscribed clients. | float | |
| mem_not_counted_for_evict | Portion of used_memory (in bytes) that’s not counted for eviction and OOM error. | float | |
| mem_frag_ratio | RAM fragmentation ratio (RSS / allocated RAM) | float | |
| disk_frag_ratio | Flash fragmentation ratio (used / required) returned only when BigRedis is enabled | float | |
| bigstore_kv_ops | rate of value read/write/del operations against back-end flash for all shards of DB (BigRedis) (key access / sec); returned only when BigRedis is enabled | float | |
| bigstore_iops | rate of i/o operations against back-end flash for all shards of DB (BigRedis) (ops/sec); returned only when BigRedis is enabled | float | |
| bigstore_throughput | throughput of i/o operations against back-end flash for all shards of DB (BigRedis) (bytes/sec) returned only when BigRedis is enabled | float | |
|
float | ||
|
float | ||
| big_write_ram | rate of key writes for keys that happen to be in ram (bigredis) (key access / sec); this includes write misses (new keys created); returned only when BigRedis is enabled | float | |
| big_write_flash | rate of key writes for keys that happen to be on flash (bigredis) (key access / sec); returned only when BigRedis is enabled | float | |
| big_del_ram | rate of key deletes for keys that happen to be in ram (bigredis) (key access / sec); this includes write misses (new keys created); returned only when BigRedis is enabled | float | |
| big_del_flash | rate of key deletes for keys that happen to be on flash (bigredis) (key access / sec); returned only when BigRedis is enabled | float | |
| big_io_ratio_redis | rate of redis operations on keys. can be used to compute ratio of io operations) (key access / sec); returned only when BigRedis is enabled | float | |
| big_io_ratio_flash | rate of key operations on flash. can be used to compute ratio of io operations (key access / sec); returned only when BigRedis is enabled | float | |
| bigstore_io_reads | rate of key reads from flash (key access / sec); returned only when BigRedis is enabled | float | |
| bigstore_io_writes | rate of key writes from flash (key access / sec); returned only when BigRedis is enabled | float | |
| bigstore_io_dels | rate of key deletions from flash (key access / sec); returned only when BigRedis is enabled | float | |
| bigstore_io_read_bytes | throughput of i/o read operations against back-end flash for all shards of DB (BigRedis) (bytes/sec); returned only when BigRedis is enabled | float | |
| bigstore_io_write_bytes | throughput of i/o write operations against back-end flash for all shards of DB (BigRedis) (bytes/sec); returned only when BigRedis is enabled | float | |
| ram_overhead | Non values RAM overhead (bigredis) (bytes) returned only when BigRedis is enabled | float | |
| bigstore_objs_ram | value count in ram (bigredis) returned only when BigRedis is enabled | float | |
| bigstore_objs_flash | value count on flash (bigredis) returned only when BigRedis is enabled | float | |
| used_memory | memory used by db (in bigredis this includes flash) (bytes) | float | |
| mem_size_lua | redis lua scripting heap size (bytes) | float | |
| used_ram | RAM used by db (bigredis) (bytes) returned only when BigRedis is enabled | float | |
| used_bigstore | Flash used by db (bigredis) (bytes) returned only when BigRedis is enabled | float | |
| last_req_time | last request time received to DB (ISO format 2015-07-05T22:16:18Z”)”; when not available returns 1/1/1970 | date, ISO_8601 format | |
| last_res_time | last response time received from DB (ISO format 2015-07-05T22:16:18Z”)”; when not available returns 1/1/1970 | date, ISO_8601 format | |
| conns | number of client connections to DB’s endpoints. | float | |
| total_connections_received | rate of new client connections to DB (connections/sec) | float | |
| ingress_bytes | rate of incoming network traffic to DB’s endpoint (bytes/sec) | float | |
| egress_bytes | rate of outgoing network traffic to DB’s endpoint (bytes/sec) | float | |
| read_req | rate of read requests on DB (ops/sec) | float | |
| read_res | rate of read responses on DB (ops/sec) | float | |
| write_req | rate of write requests on DB (ops/sec) | float | |
| write_res | rate of write responses on DB (ops/sec) | float | |
| other_req | rate of other (non read/write) requests on DB (ops/sec) | float | |
| other_res | rate of other (non read/write) responses on DB (ops/sec) | float | |
| total_req | rate of all requests on DB (ops/sec) | float | |
| total_res | rate of all responses on DB (ops/sec) | float | |
| monitor_sessions_count | number of client connected in monitor mode to the DB | float | |
| avg_read_latency | average latency of read operations (microsecond); returned only when there is traffic | float | |
| avg_write_latency | average latency of write operations (microsecond); returned only when there is traffic | float | |
| avg_other_latency | average latency of other (non read/write) operations (microsecond); returned only when there is traffic | float | |
| avg_latency | average latency of operations on the DB (microsecond); returned only when there is traffic | float | |
| shard_cpu_user | % cores utilization in user mode for the redis shard process | float | |
| shard_cpu_system | % cores utilization in system mode for all redis shard processes of this database | float | |
| main_thread_cpu_user | % cores utilization in user mode for all redis shard main threads of this database | float | |
| main_thread_cpu_system | % cores utilization in system mode for all redis shard main threads of this database | float | |
| fork_cpu_user | % cores utilization in user mode for all redis shard fork child processes of this database | float | |
| fork_cpu_system | % cores utilization in system mode for all redis shard fork child processes of this database | float | |
Shard Metrics
| Metric Name | Description | Type |
|---|---|---|
| aof_rewrite_inprog | The number of simultaneous AOF rewrites that are in progress. | float |
| avg_ttl | Estimated average time to live of a random key (msec). | float |
| bigstore_iops | rate of i/o operations against back-end flash for all shards of DB (BigRedis) (ops/sec); returned only when BigRedis is enabled | float |
| bigstore_throughput | throughput of i/o operations against back-end flash for all shards of DB (BigRedis) (bytes/sec) returned only when BigRedis is enabled | float |
| bigstore_kv_ops | rate of value read/write/del operations against back-end flash for all shards of DB (BigRedis) (key access / sec); returned only when BigRedis is enabled | float |
| bigstore_objs_flash | key count on flash (bigredis); returned only when BigRedis is enabled | float |
| bigstore_objs_ram | key count in ram (bigredis); returned only when BigRedis is enabled | float |
| big_fetch_ram | rate of key reads / updates for keys that happen to be in ram (bigredis) (key access / sec); returned only when BigRedis is enabled | float |
| big_fetch_flash | rate of key reads / updates for keys that happen to be on flash (bigredis) (key access / sec); returned only when BigRedis is enabled | float |
| big_write_ram | rate of key writes for keys that happen to be in ram (bigredis) (key access / sec); this includes write misses (new keys created); returned only when BigRedis is enabled | float |
| big_write_flash | rate of key writes for keys that happen to be on flash (bigredis) (key access / sec); returned only when BigRedis is enabled | float |
| big_del_ram | rate of key deletes for keys that happen to be in ram (bigredis) (key access / sec); this includes write misses (new keys created); returned only when BigRedis is enabled | float |
| big_del_flash | rate of key deletes for keys that happen to be on flash (bigredis) (key access / sec); returned only when BigRedis is enabled | float |
| big_io_ratio_redis | rate of redis operations on keys. can be used to compute ratio of io operations) (key access / sec); returned only when BigRedis is enabled | float |
| big_io_ratio_flash | rate of key operations on flash. can be used to compute ratio of io operations (key access / sec); returned only when BigRedis is enabled | float |
| bigstore_io_reads | rate of key reads from flash (key access / sec); returned only when BigRedis is enabled | float |
| bigstore_io_writes | rate of key writes from flash (key access / sec); returned only when BigRedis is enabled | float |
| bigstore_io_dels | rate of key deletions from flash (key access / sec); returned only when BigRedis is enabled | float |
| bigstore_io_read_bytes | throughput of i/o read operations against back-end flash for all shards of DB (BigRedis) (bytes/sec); returned only when BigRedis is enabled | float |
| bigstore_io_write_bytes | throughput of i/o write operations against back-end flash for all shards of DB (BigRedis) (bytes/sec); returned only when BigRedis is enabled | float |
| blocked_clients | Count the clients waiting on a blocking call. | float |
| connected_clients | number of client connections to the specific shard. | float |
| evicted_objects | rate of key evictions from DB (evictions/sec) | float |
| expired_objects | rate keys expired in DB (expirations/sec) | float |
| last_save_time | Time of the last RDB save. | float |
| used_memory | memory used by shard (in bigredis this includes flash) (bytes) | float |
| mem_size_lua | redis lua scripting heap size (bytes) | float |
| used_memory_peak | The largest amount of memory used by this shard (bytes). | float |
| used_memory_rss | resident set size of this shard (bytes) | float |
| no_of_keys | number of keys in DB | float |
| no_of_expires | number of volatile keys on the shard | float |
| pubsub_channels | Count the pub/sub channels with subscribed clients. | float |
| pubsub_patterns | Count the pub/sub patterns with subscribed clients. | float |
| rdb_changes_since_last_save | Count changes since last RDB save. | float |
| read_hits | rate of read operations accessing an existing key (ops/sec) | float |
| read_misses | rate of read operations accessing a non-existing key (ops/sec) | float |
| total_req | rate of operations on DB (ops/sec) | float |
| write_hits | rate of write operations accessing an existing key (ops/sec) | float |
| write_misses | rate of write operations accessing a non- existing key (ops/sec) | float |
| mem_not_counted_for_evict | Portion of used_memory (in bytes) that’s not counted for eviction and OOM error. | float |
| mem_frag_ratio | RAM fragmentation ratio (RSS / allocated RAM) | float |
| disk_frag_ratio | Flash fragmentation ratio (used / required) returned only when BigRedis is enabled | float |
| shard_cpu_user | % cores utilization in user mode for the redis shard process | float |
| shard_cpu_system | % cores utilization in system mode for the redis shard process | float |
| main_thread_cpu_user | % cores utilization in user mode for the redis shard main thread | float |
| main_thread_cpu_system | % cores utilization in system mode for the redis shard main thread | float |
| fork_cpu_user | % cores utilization in user mode for the redis shard fork child process | float |
| fork_cpu_system | % cores utilization in system mode for the redis shard fork child process | float |
Actions¶
The cluster provides support for invoking general maintenance actions such as rebalance cluster, take a node offline by moving all of its entities to other nodes, etc.
Actions are implemented in the cluster as tasks. Every task has a a unique task_id which is assigned by the cluster, a task name which describes the task, status, and additional task-specific parameters.
The REST API provides a simplified interface that allows callers to invoke actions and query their status without explicitly task_id handles. This is described in detail on a per-request basis.
Action life-cycle is based on the following status and status transitions:
| Field | Description |
|---|---|
| status |
|
| progress | Integer (0-100) representing percentage completed. |
When a task is failed, the error_code and error_message fields may be present in order to describe the encountered error.
The following error_code field value are used:
| Value | Description |
|---|---|
| internal_error | An internal error that cannot be mapped to a more precise error code has been encountered. |
| insufficient_resources | The cluster does not have sufficient resources to complete the required operation. |
Alerts¶
The cluster supports getting, configuring and enabling various alerts. Alerts can go on or off depending on the state of the cluster. And alert is bound to a cluster object (such as a bdb or node). Alerts objects are retrieved and in JSON format. The following table describes the Alert json object:
| Field | Description | Writable |
|---|---|---|
| enabled | true if alert is enabled. | x |
| state | true if alert is currently triggered. | |
| threshold | String representing an alert threshold when applicable. | x |
| change_time | Timestamp when alert state last changed. | |
| severity | The alert’s severity: DEBUG, INFO, WARNING, ERROR, CRITICAL | |
| change_value | object containing data relevant to the evaluation time when the alert went on/off (thresholds/sampled values/etc.). |
Supported Requests¶
-
GET/v1/cluster/certificates¶ Get the clusters certificates.
Example request:
GET /cluster/certificates HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "api_cert": "-----BEGIN CERTIFICATE-----...-----END CERTIFICATE-----", "api_key": "-----BEGIN RSA PRIVATE KEY-----...-----END RSA PRIVATE KEY-----" // additional certificates... }
Status Codes: - 200 OK – no error
Required permissions: view_cluster_info
-
PUT/v1/cluster/update_cert¶ Replaces specified cluster certificate with given one, the new certificate will be replaced on all nodes within the cluster. This end point will make sure given certificate is valid before actually updating the cluster.
We respond with 200 OK if we’ve managed to replace certificate across the entire cluster 403/4 otherwise, it is highly recommended to retry updating the certificate in case of a failure as the cluster might be in undesired state.
Status Codes: - 200 OK – no error
- 400 Bad Request – failed, invalid certificate.
- 403 Forbidden – failed, unknown certificate.
- 404 Not Found – failed, invalid certificate.
- 406 Not Acceptable – failed, expired certificate.
- 409 Conflict – failed, not all nodes been updated.
-
DELETE/v1/cluster/certificates/(string: certificate_name)¶ Removes specified cluster certificate both from CCS and from disk across all nodes. Only optional certificates can be deleted through this endpoint.
Example request:
DELETE /cluster/certificates/<certificate_name> Host: cnm.cluster.fqdn Accept: application/json
Status Codes: - 200 OK – operation successful
- 404 Not Found – failed, requested deletion of an unknown certificate
- 403 Forbidden – failed, requested deletion of a non-optional certificate
- 500 Internal Server Error – failed, error while deleting certificate from disk
-
POST/v1/cluster/certificates/rotate¶ Regenerates all internal cluster certificates. the certificate rotation will be performed on all nodes within the cluster. If “name” is provided, rotate only the specified certificate on all nodes within the cluster.
We respond with 200 OK if we’ve managed to rotate the internal certificate(s) across the entire cluster
Example request:
POST /cluster/certificates/rotate Host: cnm.cluster.fqdn Accept: application/json
Status Codes: - 200 OK – no error
- 400 Bad Request – failed, not all nodes been updated.
- 403 Forbidden – unsupported internal certificate rotation.
-
PUT/v1/users/password¶ Reset the password list of an internal user to include a (single) new password.
The request must contain a single JSON with the username, a currently valid password and the new password:
Example request:
PUT /users/password HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "username": "johnsmith" "old_password": "a password that exists in the current list", "new_password": "the new (single) password", }
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description password_not_complex The given password is not complex enough (Only work when the password_complexity feature is enabled). new_password_same_as_current The given new password is identical to one of the already existing passwords. Status Codes: - 200 OK – success, password changed
- 400 Bad Request – bad or missing parameters.
- 401 Unauthorized – the user is unauthorized.
- 404 Not Found – attempting to reset password to a non-existing user.
-
POST/v1/users/password¶ Add a new password to an internal user’s passwords list.
The request must contain a single JSON with the username, an existing password and a new password to be added.
Example request:
POST /users/password HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "username": "johnsmith" "old_password": "an existing password", "new_password": "a password to add", }
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description password_not_complex The given password is not complex enough (Only work when the password_complexity feature is enabled). new_password_same_as_current The given new password is identical to one of the already existing passwords. Status Codes: - 200 OK – success, new password was added to the list of valid passwords.
- 400 Bad Request – bad or missing parameters.
- 401 Unauthorized – the user is unauthorized.
- 404 Not Found – attempting to add a password to a non-existing user.
-
DELETE/v1/users/password¶ Delete a password from the list of an internal user’s passwords.
The request must contain a single JSON with the username and an existing password to be deleted.
Example request:
DELETE /users/password HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "username": "johnsmith" "old_password": "an existing password", }
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description cannot_delete_last_password Cannot delete the last password of a user Status Codes: - 200 OK – success, new password was deleted from the list of valid passwords.
- 400 Bad Request – bad or missing parameters.
- 401 Unauthorized – the user is unauthorized.
- 404 Not Found – attempting to delete a password to a non-existing user.
-
GET/v1/bdbs¶ Get all databases in the cluster.
The response body contains a JSON array with all databases, represented as bdb objects.
Query Parameters: - fields – Optional comma separated list of field names to return (by default all fields are returned).
Example request:
GET /bdbs?fields=uid,name HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 1, "name": "name of database #1", // additional fields... }, { "uid": 2, "name": "name of database #2", // additional fields... } ]
Status Codes: - 200 OK – no error
Required permissions: view_all_bdbs_info
-
GET/v1/bdbs/(int: uid)¶ Get single database (bdb object) as json.
Parameters: - uid (int) – The unique ID of the database requested.
Query Parameters: - fields – Optional comma separated list of field names to return (by default all fields are returned).
Example request:
GET /bdbs/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 1, "name": "name of database #1", // additional fields... }
See Object Attributes for more details on additional db parameters
Status Codes: - 200 OK – no error
- 404 Not Found – database uid does not exist
Required permissions: view_bdb_info
-
POST/v1/bdbs¶ Create a new database in the cluster.
The request must contain a single JSON bdb object with the configuration parameters for the new database.
If passed with the dry_run URL query string, the function will validate the bdb object, but will not invoke the state machine that will create it.
Tracking this request’s progress is done by polling the /actions/<action_uid> API with the action_uid returned by this API.
The cluster will use default configuration for any missing bdb field. The database uid will be created by the cluster if it is missing.
The response includes the newly created bdb object.
Example request:
POST /bdbs HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "name": "test-database", "type": "redis", "memory_size": 1073741824 }
Example response:
HTTP/1.1 200 OK { "uid": 1, "name": "test-database", "type": "redis", "memory_size": 1073741824, // additional fields... }
The above request is an attempt to create a Redis database with a user- specified name and a memory limit of 1GB.
The uid of the database is auto-assigned by the cluster because it was not explicitly listed in the request. If you specify the database ID (uid) then you must specify the database ID for every subsequent database and you must make sure that the database ID does not conflict with an existing database. If you do not specify the database ID, then the database ID is automatically assigned in sequential order.
Defaults are used for all other configuration parameters.
See Object Attributes for more details on additional db parameters
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description uid_exists The specified database UID is already in use. missing_db_name DB name is a required property. missing_memory_size Memory Size is a required property. missing_module Modules missing from the cluster port_unavailable The specified database port is reserved or already in use. invalid_sharding Invalid sharding configuration was specified. bad_shards_blueprint The sharding blueprint is broken. not_rack_aware Cluster is not rack aware and a rack aware database was requested. invalid_version An invalid database version was requested. busy The request failed because another request is being processed at the same time on the same database. invalid_data_persistence Invalid data persistence configuration. invalid_proxy_policy Invalid proxy_policy value. invalid_sasl_credentials SASL credentials are missing or invalid. invalid_replication Not enough nodes to perform replication. insufficient_resources Not enough resources in cluster to host the database. rack_awareness_violation - Rack awareness violation.
- Not enough nodes in unique racks.
invalid_certificate SSL client certificate is missing or malformed. certificate_expired SSL client certificate has expired. duplicated_certs An SSL client certificate appears more than once. replication_violation CRDT database must use replication. eviction_policy_violation LFU eviction policy is not supported on bdb version<4 invalid_oss_cluster_configuration BDB configuration does not meet the requirements for oss cluster mode memcached_cannot_use_modules Cannot create a memcached database with modules missing_backup_interval BDB backup is enabled but backup interval is missing. wrong_cluster_state_id The given CLUSTER-STATE-ID does not match the current one invalid_bdb_tags Tag objects with the same key parameter were passed. unsupported_module_capabilities Not all modules configured for the database support the capabilities needed for the database configuration redis_acl_unsupported Redis ACL is not supported for this database Status Codes: - 403 Forbidden – redislabs license expired.
- 409 Conflict – database with the same uid already exists.
- 406 Not Acceptable – invalid configuration parameters provided.
- 200 OK – success, database is being created.
Required permissions: create_bdb
-
PUT/v1/bdbs/(int: uid)¶ Update the configuration of an active database. This is the simplified version of the update request which contains no additional action.
Tracking this request’s progress is done by polling the /actions/<action_uid> API with the action_uid returned by this API.
Parameters: - uid – The unique ID of the database for which update is requested.
Example request:
PUT /bdbs/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "replication": true, "data_persistence": "aof" }
The above request attempts to modify a database configuration to enable in-memory data replication and Append-Only File data persistence.
Example response:
HTTP/1.1 200 OK { "uid": 1, "replication": true, "data_persistence": "aof", // additional fields... }
Status Codes: - 200 OK – the request is accepted and is being processed. The database state will be ‘active-change-pending’ until the request has been fully processed.
- 404 Not Found – attempting to change a non-existing database.
- 406 Not Acceptable – the requested configuration is invalid.
- 409 Conflict – attempting to change a database while it is busy with another configuration change. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: update_bdb
-
PUT/v1/bdbs/(int: uid)/(any: action)¶ Update the configuration of an active database.
Parameters: - uid – The unique ID of the database for which update is requested.
- action – Additional action to perform. Currently the supported actions are: flush, reset_admin_pass.
If passed with the dry_run URL query string, the function will validate the bdb object against the existing bdb, but will not invoke the state machine that will update it.
Example request:
PUT /bdbs/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "replication": true, "data_persistence": "aof" }
The above request attempts to modify a database configuration to enable in-memory data replication and Append-Only File data persistence.
Note: Changing the shard hashing policy requires flushing all keys from the database.
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description rack_awareness_violation - Non rack aware cluster.
- Not enough nodes in unique racks.
invalid_certificate SSL client certificate is missing or malformed. certificate_expired | SSL client certificate has expired. duplicated_certs | An SSL client certificate appears more than once. insufficient_resources Shards count exceeds shards limit per bdb. not_supported_action_on_crdt reset_admin_pass action is not allowed on CRDT enabled BDB. name_violation CRDT database name can not be changed. bad_shards_blueprint The sharding blueprint is broken or doesn’t fit the BDB. replication_violation CRDT database must use replication. eviction_policy_violation LFU eviction policy is not supported on bdb version<4 replication_node_violation Not enough nodes for replication. replication_size_violation Database limit too small for replication invalid_oss_cluster_configuration BDB configuration does not meet the requirements for oss cluster mode missing_backup_interval BDB backup is enabled but backup interval is missing. crdt_sharding_violation CRDB created without sharding cannot be changed to use sharding invalid_proxy_policy Invalid proxy_policy value. invalid_bdb_tags Tag objects with the same key parameter were passed - unsupported_module_capabilities | Not all modules configured for the database support the
- capabilities needed for the database configuration
redis_acl_unsupported | Redis ACL is not supported for this database Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – the request is accepted and is being processed. The database state will be ‘active-change-pending’ until the request has been fully processed.
- 403 Forbidden – redislabs license expired.
- 404 Not Found – attempting to change a non-existing database.
- 406 Not Acceptable – the requested configuration is invalid.
- 409 Conflict – attempting to change a database while it is busy with another configuration change. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: update_bdb_with_action
-
POST/v1/bdbs/(int: uid)/passwords¶ Add a password to the bdb’s default user (i.e., for AUTH <password> authentications).
Parameters: - uid – The unique ID of the database to which the password is to be added.
Example request:
POST /bdbs/1/passwords HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "password": "password to add" }
The above request adds a password to the bdb.
Example response:
HTTP/1.1 200 OK
Status Codes: - 200 OK – the password was added.
- 404 Not Found – a non-existing database.
- 406 Not Acceptable – invalid configuration parameters provided.
Required permissions: update_bdb
-
DELETE/v1/bdbs/(int: uid)/passwords¶ Delete a password from the bdb’s default user (i.e., for AUTH <password> authentications).
Parameters: - uid – The unique ID of the database to which the password is to be added.
Example request:
DELETE /bdbs/1/passwords HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "password": "password to delete" }
The above request deletes a password from the bdb.
Example response:
HTTP/1.1 200 OK
Status Codes: - 200 OK – the password was deleted.
- 404 Not Found – a non-existing database.
- 406 Not Acceptable – invalid configuration parameters provided.
Required permissions: update_bdb
-
PUT/v1/bdbs/(int: uid)/passwords¶ Set a (single) password to the bdb’s default user (i.e., for AUTH <password> authentications).
Parameters: - uid – The unique ID of the database to which the password is to be added.
Example request:
PUT /bdbs/1/passwords HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "password": "new password" }
The above request resets the password of the bdb to ‘new password’
Example response:
HTTP/1.1 200 OK
Status Codes: - 200 OK – the password was changed.
- 404 Not Found – a non-existing database.
- 406 Not Acceptable – invalid configuration parameters provided.
Required permissions: update_bdb
-
DELETE/v1/bdbs/(int: uid)¶ Delete an active database.
Parameters: - uid – The unique ID of the database to delete.
Example request:
DELETE /bdbs/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
The above request attempts to completely delete database with unique ID 1.
Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – the request is accepted and is being processed. The database state will be ‘delete-pending’ until the request has been fully processed.
- 403 Forbidden – attempting to delete an internal database.
- 404 Not Found – attempting to delete a non-existing database.
- 409 Conflict – the database is not in ‘active’ state and cannot be delete or attempting to change a database while it is busy with another configuration change. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: delete_bdb
-
POST/v1/bdbs/(int: uid)/actions/export¶ Initiate a database export.
Parameters: - uid – The unique ID of the database
The request body should contain a JSON object, with the following export parameters:
- export_location - details for the export destination. GET /jsonschema on the bdb object and review the
- backup_location field to retrieve the object’s structure.
- email_notification - optional, when true an email on failure/completion will be sent when export is done.
See Backup Location for more details on the backup location types.
Example request:
POST /bdbs/1/actions/export HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "export_location": {"type": "url", "url": "ftp://..."}, "email_notification": true }
Example response:
HTTP/1.1 200 OK Content-Length: 0
The above request initiates an export operation to the specified location.
Status Codes: - 200 OK – the request is accepted and is being processed. In order to monitor progress, the BDB’s export_status, export_progress and export_failure_reason attributes can be consulted.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 406 Not Acceptable – not all the modules loaded to the database support ‘backup_restore’ capability
- 409 Conflict – database is currently busy with another action. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: start_bdb_export
-
PUT/v1/bdbs/(int: uid)/actions/export_reset_status¶ Reset database current export status (export_status) to idle if not in progress. As well clear exiting export_failure_reason if exits
Parameters: - uid – The unique ID of the database
Example request:
PUT /bdbs/1/actions/export_reset_status HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
The above request resets export_status to idle value and clear failure reason message if exist from export_failure_reason.
Status Codes: - 200 OK – the request is accepted and is being processed.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 406 Not Acceptable – not all the modules loaded to the database support ‘backup_restore’ capability
- 409 Conflict – database is currently busy with another action. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: reset_bdb_current_export_status
-
PUT/v1/bdbs/(int: uid)/actions/backup_reset_status¶ Reset database current backup status (backup_status) to idle if not in progress. As well clear exiting backup_failure_reason if exits
Parameters: - uid – The unique ID of the database
Example request:
PUT /bdbs/1/actions/backup_reset_status HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
The above request resets backup_status to idle value and clear failure reason message if exist from backup_failure_reason.
Status Codes: - 200 OK – the request is accepted and is being processed.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 406 Not Acceptable – not all the modules loaded to the database support ‘backup_restore’ capability
- 409 Conflict – database is currently busy with another action. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: reset_bdb_current_backup_status
-
POST/v1/bdbs/(int: uid)/actions/import¶ Initiate a manual import process.
Parameters: - uid – The unique ID of the database
The request may contain a subset of the bdb JSON object, which includes the following import-related attributes:
- dataset_import_sources - details for the import sources. GET /jsonschema on the bdb object and review the
- dataset_import_sources field to retrieve the object’s structure.
- email_notification - optional, when true an email on failure/completion will be sent when import is done.
See Import Sources for more details on the import location types.
Other attributes are not allowed and will fail the request.
Example request:
POST /bdbs/1/actions/import HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json Content-Length: 0 { "dataset_import_sources": [{"type": "url", "url": "http://..."}, {"type": "url", "url": "redis://..."}], "email_notification": true }
Example response:
HTTP/1.1 200 OK Content-Length: 0
The above request initiates an import process using dataset_import_sources values that were previously configured for the database.
Status Codes: - 200 OK – the request is accepted and is being processed. In order to monitor progress, the import_status, import_progress and import_failure_reason attributes can be consulted.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 406 Not Acceptable – not all the modules loaded to the database support ‘backup_restore’ capability
- 409 Conflict – database is currently busy with another action. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: start_bdb_import
-
POST/v1/bdbs/(int: uid)/actions/recover¶ Initiate recovery for a database in recovery state.
The request body may be empty, in which case the database will be recovered automatically:
- Databases with no persistence are recovered with no data.
- Persistent files (aof, rdb) will be loaded from their expected storage locations (i.e. where slave or master shards were last active).
- If persistent files are not found where expected but can be located on other cluster nodes, they will be used.
In addition, the request may include a request body with an explicit recovery plan.
Parameters: - uid – The unique ID of the database to recover.
Status Codes: - 200 OK – the request is accepted and is being processed. When the database is recovered, its status will become active.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 409 Conflict – database is currently busy with another action (e.g. recovery already in progress) or is not in recoverable state.
Example request, no recovery plan:
POST /bdbs/1/actions/recover HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example request, detailed recovery plan:
POST /bdbs/1/actions/recover HTTP/1.1 Host: cnm.cluster.fqdn Content-Type: application/json { "data_files": [ { "filename": "appendonly-1.aof", "node_uid": "1", "shard_slots": "1-2048" }, { "filename": "appendonly-2.aof", "node_uid": "2", "shard_slots": "2049-4096" } ], "ignore_errors": false, "recover_without_data": false }
Required permissions: start_bdb_recovery
-
GET/v1/bdbs/(int: uid)/actions/recover¶ Fetch the recovery plan for a database in recovery mode. The recovery plan provides information about the recovery status (if it is possible) and specific detail on which available files to recovery from have been found.
Parameters: - uid – The unique ID of the database for which recovery plan is required. The database must be in recovery mode.
Required permissions: view_bdb_recovery_plan
-
POST/v1/bdbs/(int: uid)/command¶ Execute a redis/memcached command, per the db type.
The request must contain a redis command JSON representation consists of a ‘command’ field. It may also consist of an ‘args’ array.
Parameters: - uid (int) – The uid of the db on which the command will be performed.
1. Redis Example request:
POST /bdbs/<int:uid>/command HTTP/1.1 Accept: application/json { "command": "INFO" }
Example response:
HTTP/1.1 200 OK { "response": { "aof_current_rewrite_time_sec": -1, "aof_enabled": 0, "aof_last_bgrewrite_status": "ok", // Additional fields } }
2. Redis Example request:
POST /bdbs/<int:uid>/command HTTP/1.1 Accept: application/json { "command": "HSET", "args": ["myhash", "foo", "bar"] }
Example response:
HTTP/1.1 200 OK { "response": 1 }
2. Memcached Example request:
POST /bdbs/<int:uid>/command HTTP/1.1 Accept: application/json { "command": "flush_all" }
Example response:
HTTP/1.1 200 OK { "response": true }
Status Codes: - 200 OK – OK
- 400 Bad Request – Malformed or bad command
- 503 Service Unavailable – Redis connection error, service unavailable
- 500 Internal Server Error – Internal error
Required permissions: execute_redis_or_memcached_command
-
GET/v1/bdbs/(int: uid)/actions/optimize_shards_placement¶ Get optimized shards placement for the given database.
Example request:
GET /bdbs/1/actions/optimize_shards_placement HTTP/1.1
Example response:
HTTP/1.1 200 OK Content-Length: 352 [{"nodes":[{"node_uid":"3","role":"master"},{"node_uid":"1","role":"slave"}],"slot_range":"5461-10922"}, {"nodes":[{"node_uid":"3","role":"master"},{"node_uid":"1","role":"slave"}],"slot_range":"10923-16383"}, {"nodes":[{"node_uid":"3","role":"master"},{"node_uid":"1","role":"slave"}],"slot_range":"0-5460"}]
The blueprint returned as the result of this call can be submitted via PUT to the database as the shards_blueprint field. This will cause the shards to be rearranged according to this blueprint. One should use the cluster-state-id feature when trying to optimize the shards placement using the plan returned by this api call. The cluster-state-id returned in the header of this api call, should be passed in the headers of the PUT request on the database, in order to make sure that the optimized shard placement is relevant for the current cluster state. The cluster will reject the update if its state was changed since the optimal shards placement was obtained.
Example request for rearranging the shards of the database:
PUT /bdbs/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json cluster-state-id: 30 {"shards_blueprint": [{"nodes":[{"node_uid":"2","role":"master"}],"slot_range":"0-8191"}, ...]}
Note that submitting such an optimized blueprint may cause strain on the cluster and its resources, and should therefore be used with caution.
Status Codes: - 200 OK – no error
- 404 Not Found – database uid does not exist
- 406 Not Acceptable – not enough resources in the cluster to host the database
Required permissions: view_bdb_info
-
POST/v1/bdbs/(int: uid)/upgrade¶ Upgrade a BDB
Example request:
POST /bdbs/1/upgrade HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "swap_roles": true, "may_discard_data": false }
Example response:
HTTP/1.1 200 OK { "uid": 1, "replication": true, "data_persistence": "aof", // additional fields... }
The allowed parameters are: force_restart: restart shards even if no version change (default: False) keep_redis_version: keep current redis version (default: False) keep_crdt_protocol_version: keep current crdt protocol version (default: False) may_discard_data: discard data in a non-replicated non-persistent bdb (default: False) force_discard: discard data even if the bdb is replicated and/or persistent (default: False) preserve_roles: should preserve shards’ master/slave roles (requires and extra failover) (default: False) parallel_shards_upgrade: max number of many shards to upgrade in parallel (default: all) modules: list of dicts representing the modules that will be upgraded. Each dict will include: * current_module: uid of a module to upgrade * new_module: uid of the module we want to upgrade to * new_module_args: args list for the new module (no defaults for the three module-related parameters). redis_version: explicitly specify which redis version to upgrade to.
Status Codes: - 200 OK – success, bdb upgrade initiated (action_uid can be used to track progress)
- 400 Bad Request – Malformed or bad command. If the cluster is configured with the “major” upgrade policy, specifying a non-major redis_version will result in a 400 response.
- 404 Not Found – bdb not found
- 406 Not Acceptable – new module version capabilities don’t comply with the database configuration
- 500 Internal Server Error – internal error
Required permissions: update_bdb_with_action
-
POST/v2/bdbs¶ Create a new database in the cluster. See /v1/bdbs for more information. The database’s configuration should be under the “bdb” field.
Including a recovery_plan within the request body will result in the database being loaded from the persistence files according to the recovery plan. The recovery plan must match the number of shards requested for the database. The persistence files must exist in the locations specified by the recovery plan. The persistence files must belong to a database with the same shard settings as the one being created (slot range distribution and shard_key_regex), otherwise the operation will fail or yield unpredictable results.
Creating a database with a shards_blueprint and a recovery plan may result in the shards_blueprint’s shard placement only partially fulfilled.
In order to retrieve a recovery plan according to the database’s existing persistence files, use the GET /bdbs/<uid>/actions/recover API.
Example request:
POST /v2/bdbs HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "bdb": { "name": "test-database", "type": "redis", "memory_size": 1073741824, "shards_count": 1 }, "recovery_plan": { {"data_files": [{"shard_slots": "0-16383", "node_uid": "1", "filename": "redis-4.rdb"}]} } }
Example response:
HTTP/1.1 200 OK { "uid": 1, "name": "test-database", "type": "redis", "memory_size": 1073741824, "shards_count": 1, // additional fields... }
-
GET/v1/bdbs/alerts¶ Get all alert states for all bdbs.
Returns a hash of alert uid’s and the alerts states for each BDB.
See REST API alerts overview for a description of the alert state object.
Example request:
GET /bdbs/alerts HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "bdb_size": { "enabled": true, "state": true, "threshold": "80", "change_time": "2014-08-29T11:19:49Z", "severity": "WARNING", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }, ... }
Status Codes: - 200 OK – no error
Required permissions: view_all_bdbs_alerts
-
GET/v1/bdbs/alerts/(int: uid)¶ Get all alert states for bdb.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Example request:
GET /bdbs/alerts/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "bdb_size": { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/alerts/(int: uid)/(alert)¶ Get bdb alert state.
See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
- alert – The alert name
Example request:
GET /bdbs/alerts/1/bdb_size HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }
Status Codes: - 200 OK – no error
- 400 Bad Request – bad request
- 404 Not Found – specified alert or bdb does not exist
Required permissions: view_bdb_alerts
-
POST/v1/bdbs/alerts/(int: uid)¶ Updates database’s one or many alerts configuration
Parameters: - uid (int) – the database ID
The request must contain a single JSON bdb object with one or many database alert objects in it. Each alert configuration object must be according to the following schema
If passed with the dry_run URL query string, the function will validate the alert thresholds, but not commit them
{ "enabled": { "description": "Alert enabled or disabled", "type": "string", "enum": [ "enabled", "disabled" ] }, "threshold": { "description": "Threshold for alert to indicate when it should turn on or off", "type": "string" } }
The response includes the updated database alerts.
Example request for database with ID=1:
POST /bdbs/alerts/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "bdb_size":{ "threshold":"80", "enabled":true }, "bdb_high_syncer_lag":{ "threshold":"", "enabled":false }, "bdb_low_throughput":{ "threshold":"1", "enabled":true }, "bdb_high_latency":{ "threshold":"3000", "enabled":true }, "bdb_high_throughput":{ "threshold":"1", "enabled":true }, "bdb_backup_delayed":{ "threshold":"1800", "enabled":true } }
The above request is an attempt to modify 6 different alerts for database with ID=1.
See Object Attributes for more details on additional database alert types
Status Codes: - 404 Not Found – specified database was not found.
- 406 Not Acceptable – invalid configuration parameters provided.
- 200 OK – success, database alerts updated.
Required permissions: update_bdb_alerts
-
GET/v1/nodes/alerts¶ Get all alert states for all nodes.
Returns a hash of node uid’s and the alerts states for each node.
See REST API alerts overview for a description of the alert state object.
Query Parameters: - ignore_settings – Optional retrieve updated alert state regardless if alert is enabled in cluster’s alert_settings. When not present a disabled alert will always be retrieved as disabled with a false state.
Example request:
GET /nodes/alerts HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "node_cpu_utilization": { "change_time": "2014-12-22T10:42:00Z", "change_value": { "cpu_util": 2.500000000145519, "global_threshold": "1", "state": true }, "enabled": true, "state": true, "severity": "WARNING" }, ... }, ... }
Status Codes: - 200 OK – no error
Required permissions: view_all_nodes_alerts
-
GET/v1/nodes/alerts/(int: uid)¶ Get all alert states for a node.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Query Parameters: - ignore_settings – Optional retrieve updated alert state regardless if alert is enabled in cluster’s alert_settings. When not present a disabled alert will always be retrieved as disabled with a false state.
Example request:
GET /nodes/alerts/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "node_cpu_utilization": { "change_time": "2014-12-22T10:42:00Z", "change_value": { "cpu_util": 2.500000000145519, "global_threshold": "1", "state": true }, "enabled": true, "state": true "severity": "WARNING", }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified node does not exist
Required permissions: view_node_alerts
-
GET/v1/nodes/alerts/(int: uid)/(alert)¶ Get node alert state.
See REST API alerts overview for a description of the alert state object.
Query Parameters: - ignore_settings – Optional retrieve updated alert state regardless if alert is enabled in cluster’s alert_settings. When not present a disabled alert will always be retrieved as disabled with a false state.
Example request:
GET /nodes/alerts/1/node_cpu_utilization HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "change_time": "2014-12-22T10:42:00Z", "change_value": { "cpu_util": 2.500000000145519, "global_threshold": "1", "state": true }, "enabled": true, "state": true "severity": "WARNING", }
Status Codes: - 200 OK – no error
- 404 Not Found – specified alert or node does not exist
Required permissions: view_node_alerts
-
GET/v1/cluster/alerts¶ Get all alert states for the cluster object.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Query Parameters: - ignore_settings – Optional retrieve updated alert state regardless if alert is enabled in cluster’s alert_settings. When not present a disabled alert will always be retrieved as disabled with a false state.
Example request:
GET /cluster/alerts HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "cluster_too_few_nodes_for_replication": { "change_time": "2014-12-22T11:48:00Z", "change_value": { "state": false }, "enabled": true, "state": "off" "severity": "WARNING", }, ... }
Status Codes: - 200 OK – no error
Required permissions: view_cluster_alerts
-
GET/v1/cluster/alerts/(alert)¶ Get cluster alert state.
See REST API alerts overview for a description of the alert state object.
Query Parameters: - ignore_settings – Optional retrieve updated alert state regardless if alert is enabled in cluster’s alert_settings. When not present a disabled alert will always be retrieved as disabled with a false state.
Example request:
GET /cluster/alerts/cluster_too_few_nodes_for_replication HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "change_time": "2014-12-22T11:48:00Z", "change_value": { "state": false }, "enabled": true, "state": "off" "severity": "WARNING", }
Status Codes: - 200 OK – no error
- 404 Not Found – specified alert does not exist
Required permissions: view_cluster_alerts
-
GET/v1/bdbs/crdt_sources/alerts¶ Get all alert states for all crdt sources of all CRDBs.
Returns a hash of alert uid’s and the alerts states for each local BDB of CRDB.
See REST API alerts overview for a description of the alert state object.
Example request:
GET /bdbs/crdt_sources/alerts HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "crdt_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "change_time": "2014-08-29T11:19:49Z", "severity": "WARNING", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }, ... }
Status Codes: - 200 OK – no error
Required permissions: view_all_bdbs_alerts
-
GET/v1/bdbs/crdt_sources/alerts/(int: uid)¶ Get all alert states for all crdt source for specific local bdb of CRDB.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
Example request:
GET /bdbs/crdt_sources/alerts/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "crdt_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/crdt_sources/alerts/(int: uid)/(int: crdt_src_id)¶ Get all alert states for specific crdt source for specific local bdb of CRDB.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
- crdt_src_id – The ID of the crdt source in this BDB
Example request:
GET /bdbs/crdt_sources/alerts/1/2 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "crdt_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/crdt_sources/alerts/(int: uid)/(int: crdt_src_id)/(alert)¶ Get bdb alert state.
See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
- crdt_src_id – The ID of the crdt source in this BDB
- alert – The alert name
Example request:
GET /bdbs/crdt_sources/alerts/1/2/crdt_src_syncer_connection_error HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }
Status Codes: - 200 OK – no error
- 400 Bad Request – bad request
- 404 Not Found – specified alert or bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/replica_sources/alerts¶ Get all alert states for all replica sources of all BDBs.
Returns a hash of alert uid’s and the alerts states for each BDB.
See REST API alerts overview for a description of the alert state object.
Example request:
GET /bdbs/replica_sources/alerts HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "replica_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "change_time": "2014-08-29T11:19:49Z", "severity": "WARNING", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }, ... }
Status Codes: - 200 OK – no error
Required permissions: view_all_bdbs_alerts
-
GET/v1/bdbs/replica_sources/alerts/(int: uid)¶ Get all alert states for all replica source of specific bdb.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
Example request:
GET /bdbs/replica_sources/alerts/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "replica_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/replica_sources/alerts/(int: uid)/(int: replica_src_id)¶ Get all alert states for specific replica source of bdb.
Returns a hash of alert objects and their state. See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
- replica_src_id – The ID of the replica source in this BDB
Example request:
GET /bdbs/replica_sources/alerts/1/2 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "replica_src_syncer_connection_error": { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }, ... }
Status Codes: - 200 OK – no error
- 404 Not Found – specified bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/bdbs/replica_sources/alerts/(int: uid)/(int: replica_src_id)/(alert)¶ Get replica source alert state of specific bdb.
See REST API alerts overview for a description of the alert state object.
Parameters: - uid – The unique ID of the database
- replica_src_id – The ID of the replica source in this BDB
- alert – The alert name
Example request:
GET /bdbs/replica_sources/alerts/1/2/replica_src_syncer_connection_error HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "enabled": true, "state": true, "threshold": "80", "severity": "WARNING", "change_time": "2014-08-29T11:19:49Z", "change_value": { "state": true, "threshold": "80", "memory_util": 81.2 } }
Status Codes: - 200 OK – no error
- 400 Bad Request – bad request
- 404 Not Found – specified alert or bdb does not exist
Required permissions: view_bdb_alerts
-
GET/v1/nodes¶ Get all cluster nodes.
Example request:
GET /nodes HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 1, "status": "active", "uptime": 262735, "total_memory": 6260334592, "software_version": "0.90.0-1", "ephemeral_storage_size": 20639797248.0, "persistent_storage_path": "/var/opt/redislabs/persist", "persistent_storage_size": 20639797248.0, "os_version": "Ubuntu 14.04.2 LTS", "ephemeral_storage_path": "/var/opt/redislabs/tmp", "architecture": "x86_64", "shard_count": 23, "public_addr": "", "cores": 4, "rack_id": "", "supported_database_versions": [ { "db_type": "memcached", "version": "1.4.17" }, { "db_type": "redis", "version": "2.6.16" }, { "db_type": "redis", "version": "2.8.19" } ], shard_list": [1, 3, 4] "addr": "10.0.3.61" }, { "uid": 1, "status": "active", // additional fields... } ]
Status Codes: - 200 OK – no error
Required permissions: view_all_nodes_info
-
GET/v1/nodes/(int: uid)¶ Get single cluster node.
Parameters: - uid – The unique ID of the node requested.
Example request:
GET /nodes/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 1, "name": "node:1", // additional fields... }
Status Codes: - 200 OK – no error
- 404 Not Found – node uid does not exist
Required permissions: view_node_info
-
GET/v1/bdbs/stats/(int: uid)¶ Get stats for BDB.
Parameters: - uid – The unique ID of the BDB requested.
Query Parameters: - interval – Optional time interval for for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week
- stime – Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /bdbs/stats/1?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": "1", "intervals": [ { "interval": "1hour", "stime": "2015-05-27T12:00:00Z", "etime": "2015-05-28T12:59:59Z", "avg_latency": 0.0, "conns": 0.0, "egress_bytes": 0.0, "evicted_objects": 0.0, "pubsub_channels": 0, "pubsub_patterns": 0, "expired_objects": 0.0, "ingress_bytes": 0.0, "instantaneous_ops_per_sec": 0.00011973180076628352, "last_req_time": "1970-01-01T00:00:00Z", "last_res_time": "1970-01-01T00:00:00Z", "used_memory": 5656299.362068966, "mem_size_lua": 35840.0, "monitor_sessions_count": 0.0, "no_of_keys": 0.0, "other_req": 0.0, "other_res": 0.0, "read_hits": 0.0, "read_misses": 0.0, "read_req": 0.0, "read_res": 0.0, "total_connections_received": 0.0, "total_req": 0.0, "total_res": 0.0, "write_hits": 0.0, "write_misses": 0.0, "write_req": 0.0, "write_res": 0.0 }, { "interval": "1hour", "stime": "2015-05-27T13:00:00Z", "etime": "2015-05-28T13:59:59Z", // additional fields... } ] }
Status Codes: - 200 OK – no error
- 404 Not Found – bdb does not exist
- 406 Not Acceptable – bdb isn’t currently active
- 503 Service Unavailable – bdb is in recovery state
Required permissions: view_bdb_stats
-
GET/v1/bdbs/stats¶ Get stats for all BDBs.
Query Parameters: - interval – Optional time interval for for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /bdbs/stats?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": "1", "intervals": [ { "interval": "1hour", "stime": "2015-05-27T12:00:00Z", "etime": "2015-05-28T12:59:59Z", "avg_latency": 0.0, "conns": 0.0, "egress_bytes": 0.0, "etime": "2015-05-28T00:00:00Z", "evicted_objects": 0.0, "expired_objects": 0.0, "ingress_bytes": 0.0, "instantaneous_ops_per_sec": 0.00011973180076628352, "last_req_time": "1970-01-01T00:00:00Z", "last_res_time": "1970-01-01T00:00:00Z", "used_memory": 5656299.362068966, "mem_size_lua": 35840.0, "monitor_sessions_count": 0.0, "no_of_keys": 0.0, "other_req": 0.0, "other_res": 0.0, "read_hits": 0.0, "read_misses": 0.0, "read_req": 0.0, "read_res": 0.0, "total_connections_received": 0.0, "total_req": 0.0, "total_res": 0.0, "write_hits": 0.0, "write_misses": 0.0, "write_req": 0.0, "write_res": 0.0 }, { "interval": "1hour", "interval": "1hour", "stime": "2015-05-27T13:00:00Z", "etime": "2015-05-28T13:59:59Z", "avg_latency": 599.08, // additional fields... } ] }, { "uid": "2", "intervals": [ { "interval": "1hour", "stime": "2015-05-27T12:00:00Z", "etime": "2015-05-28T12:59:59Z", "avg_latency": 0.0, // additional fields... }, { "interval": "1hour", "stime": "2015-05-27T13:00:00Z", "etime": "2015-05-28T13:59:59Z", // additional fields... } ] } ]
Status Codes: - 200 OK – no error
- 404 Not Found – no bdbs exist
Required permissions: view_all_bdb_stats
-
GET/v1/bdbs/stats/last/(int: uid)¶ Get the most recent statistic information for BDB.
Parameters: - uid – The unique ID of the requested BDB.
Query Parameters: - metrics – Optional comma separated list of metric names for which we want statistics (default is all).
Example request:
GET /bdbs/stats/last/1?metrics=no_of_keys,used_memory HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "etime": "2015-06-23T12:05:08Z", "used_memory": 5651576.0, "no_of_keys": 0.0, "stime": "2015-06-23T12:05:03Z" } }
Status Codes: - 200 OK – no error
- 404 Not Found – bdb does not exist
- 406 Not Acceptable – bdb isn’t currently active
- 503 Service Unavailable – bdb is in recovery state
Required permissions: view_bdb_stats
-
GET/v1/bdbs/stats/last¶ Get the most recent statistic information for all BDBs.
Query Parameters: - metrics – Optional comma separated list of metric names for which we want statistics (default is all).
1. Example request:
GET /bdbs/stats/last HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "stime": "2015-05-28T08:06:37Z", "etime": "2015-05-28T08:06:44Z", "conns": 0.0, "egress_bytes": 0.0, "etime": "2015-05-28T08:06:44Z", "evicted_objects": 0.0, "expired_objects": 0.0, "ingress_bytes": 0.0, "instantaneous_ops_per_sec": 0.0, "last_req_time": "1970-01-01T00:00:00Z", "last_res_time": "1970-01-01T00:00:00Z", "used_memory": 5651336.0, "mem_size_lua": 35840.0, "monitor_sessions_count": 0.0, "no_of_keys": 0.0, "other_req": 0.0, "other_res": 0.0, "read_hits": 0.0, "read_misses": 0.0, "read_req": 0.0, "read_res": 0.0, "total_connections_received": 0.0, "total_req": 0.0, "total_res": 0.0, "write_hits": 0.0, "write_misses": 0.0, "write_req": 0.0, "write_res": 0.0 }, "2": { "stime": "2015-05-28T08:06:37Z", "etime": "2015-05-28T08:06:44Z", // additional fields... }, // Additional BDBs... }
2. Example request:
GET /bdbs/stats/last?metrics=no_of_keys,used_memory HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "etime": "2015-05-28T08:06:44Z", "used_memory": 5651576.0, "no_of_keys": 0.0, "stime": "2015-05-28T08:06:37Z"" }, "2": { "etime": "2015-05-28T08:06:44ZZ", "used_memory": 5651440.0, "no_of_keys": 0.0, "stime": "2015-05-28T08:06:37Z" }, // Additional BDBs.. }
Status Codes: - 200 OK – no error
- 404 Not Found – no bdbs exist
Required permissions: view_all_bdb_stats
-
GET/v1/shards/stats/(int: uid)¶ Get stats for a specific shard.
Parameters: - uid – The unique ID of the shard requested.
Query Parameters: Example request:
GET /shards/stats/1?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": "1", "status": "active", "node_uid": "1", "role": "master",, "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:24:13Z", "etime": "2015-05-28T08:24:18Z", "avg_ttl": 0.0, "blocked_clients": 0.0, "connected_clients": 9.0, "etime": "2015-05-28T08:24:18Z", "evicted_objects": 0.0, "expired_objects": 0.0, "last_save_time": 1432541051.0, "used_memory": 5651440.0, "mem_size_lua": 35840.0, "used_memory_peak": 5888264.0, "used_memory_rss": 5888264.0, "no_of_expires": 0.0, "no_of_keys": 0.0, "pubsub_channels": 0.0, "pubsub_patterns": 0.0, "rdb_changes_since_last_save": 0.0, "read_hits": 0.0, "read_misses": 0.0, "stime": "2015-05-28T08:24:13Z", "sync_full": 0.0, "sync_partial_err": 0.0, "sync_partial_ok": 0.0, "total_req": 0.0, "write_hits": 0.0, "write_misses": 0.0 }, { interval": "1sec", "stime": "2015-05-28T08:24:18Z",, "etime": "2015-05-28T08:24:23Z", // additional fields... } ] }
Status Codes: - 200 OK – no error
- 404 Not Found – shard does not exist
- 406 Not Acceptable – shard isn’t currently active
Required permissions: view_shard_stats
-
GET/v1/shards/stats¶ Get stats for all shards.
Query Parameters: - parent_uid – Optional return only shard from the given BDB ID.
- interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
- metrics – Optional comma separated list of metric names for which we want statistics (default is all).
Example request:
GET /shards/stats?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "status": "active", "uid": "1", "node_uid": "1", "assigned_slots": "0-8191", "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:27:35Z", "etime": "2015-05-28T08:27:40Z", "used_memory_peak": 5888264.0, "used_memory_rss": 5888264.0, "read_hits": 0.0, "pubsub_patterns": 0.0, "no_of_keys": 0.0, "mem_size_lua": 35840.0, "last_save_time": 1432541051.0, "sync_partial_ok": 0.0, "connected_clients": 9.0, "avg_ttl": 0.0, "write_misses": 0.0, "used_memory": 5651440.0, "sync_full": 0.0, "expired_objects": 0.0, "total_req": 0.0, "blocked_clients": 0.0, "pubsub_channels": 0.0, "evicted_objects": 0.0, "no_of_expires": 0.0, "interval": "1sec", "write_hits": 0.0, "read_misses": 0.0, "sync_partial_err": 0.0, "rdb_changes_since_last_save": 0.0 }, { "interval": "1sec", "stime": "2015-05-28T08:27:40Z", "etime": "2015-05-28T08:27:45Z", // additional fields... } ] }, { "uid": "2", "status": "active", "node_uid": "1", "assigned_slots": "8192-16383" "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:27:35Z", "etime": "2015-05-28T08:27:40Z",, // additional fields... }, { "interval": "1sec", "stime": "2015-05-28T08:27:40Z", "etime": "2015-05-28T08:27:45Z", // additional fields... } ] } ]
Status Codes: - 200 OK – no error
- 404 Not Found – no shards exist
Required permissions: view_all_shard_stats
-
GET/v1/nodes/stats/(int: uid)¶ Get stats for node.
Parameters: - uid – The unique ID of the node requested.
Query Parameters: Example request:
GET /nodes/stats/1?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": "1", "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:40:11Z", "etime": "2015-05-28T08:40:12Z", "conns": 0.0, "cpu_idle": 0.5499999999883585, "cpu_system": 0.03499999999985448, "cpu_user": 0.38000000000101863, "egress_bytes": 0.0, "ephemeral_storage_avail": 2929315840.0, "ephemeral_storage_free": 3977830400.0, "free_memory": 893485056.0, "ingress_bytes": 0.0, "persistent_storage_avail": 2929315840.0, "persistent_storage_free": 3977830400.0, "total_req": 0.0. }, { "interval": "1sec", "stime": "2015-05-28T08:40:12Z", "etime": "2015-05-28T08:40:13Z", "cpu_idle": 1.2, // additional fields... } ] }
Status Codes: - 200 OK – no error
- 404 Not Found – node does not exist
- 406 Not Acceptable – node isn’t currently active
- 503 Service Unavailable – node is in recovery state
Required permissions: view_node_stats
-
GET/v1/nodes/stats¶ Get stats for all nodes.
Query Parameters: Example request:
GET /nodes/stats?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": "1", "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:40:11Z", "etime": "2015-05-28T08:40:12Z", "conns": 0.0, "cpu_idle": 0.5499999999883585, "cpu_system": 0.03499999999985448, "cpu_user": 0.38000000000101863, "egress_bytes": 0.0, "ephemeral_storage_avail": 2929315840.0, "ephemeral_storage_free": 3977830400.0, "free_memory": 893485056.0, "ingress_bytes": 0.0, "persistent_storage_avail": 2929315840.0, "persistent_storage_free": 3977830400.0, "total_req": 0.0. }, { "interval": "1sec", "stime": "2015-05-28T08:40:12Z", "etime": "2015-05-28T08:40:13Z", "cpu_idle": 1.2, // additional fields... } ] }, { "uid": "2", "intervals": [ { "interval": "1sec", "stime": "2015-05-28T08:40:11Z", "etime": "2015-05-28T08:40:12Z", "conns": 0.0, "cpu_idle": 0.5499999999883585, "cpu_system": 0.03499999999985448, "cpu_user": 0.38000000000101863, "egress_bytes": 0.0, "ephemeral_storage_avail": 2929315840.0, "ephemeral_storage_free": 3977830400.0, "free_memory": 893485056.0, "ingress_bytes": 0.0, "persistent_storage_avail": 2929315840.0, "persistent_storage_free": 3977830400.0, "total_req": 0.0. }, { "interval": "1sec", "stime": "2015-05-28T08:40:12Z", "etime": "2015-05-28T08:40:13Z", "cpu_idle": 1.2, // additional fields... } ] } ]
Status Codes: - 200 OK – no error
- 404 Not Found – no nodes exist
Required permissions: view_all_nodes_stats
-
GET/v1/cluster/stats¶ Get cluster stats.
Query Parameters: Example request:
GET /cluster/stats/1?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "intervals": [ { "interval": "1hour", "stime": "2015-05-27T12:00:00Z", "etime": "2015-05-28T12:59:59Z", "conns": 0.0, "cpu_idle": 0.8533959401503577, "cpu_system": 0.01602159448549579, "cpu_user": 0.08721123782294203, "egress_bytes": 1111.2184745131947, "ephemeral_storage_avail": 3406676307.1449075, "ephemeral_storage_free": 4455091440.360014, "free_memory": 2745470765.673594, "ingress_bytes": 220.84083194769272, "interval": "1week", "persistent_storage_avail": 3406676307.1533995, "persistent_storage_free": 4455091440.088265, "total_req": 0.0 }, { "interval": "1hour", "stime": "2015-05-27T13:00:00Z", "etime": "2015-05-28T13:59:59Z", // additional fields... } ] }
Status Codes: - 200 OK – no error
- 500 Internal Server Error – Internal Server Error
Required permissions: view_cluster_stats
-
GET/v1/bootstrap¶ Get the local node’s bootstrap status.
This request is accepted as soon the cluster software is installed, and before the node is part of an active cluster.
Once the node is part of an active cluster authentication is required.
The JSON response object contains two other objects: bootstrap_status which is described below, and local_node_info which is a subset of a node object that provides information about the node configuration.
The bootstrap_status object contains the following fields:
Field Description state Current bootstrap state. idle: No bootstrapping started. initiated: Bootstrap request received. creating_cluster: In the process of creating a new cluster. joining_cluster: In the process of joining an existing cluster. error: The last bootstrap action failed. completed: The last bootstrap action completed successfully. start_time Bootstrap process start time end_time Bootstrap process end time error_code If state is error, this is an error code that describes the type of error encountered. config_error: An error related to the bootstrap configuration provided (e.g. bad JSON). connect_error: Failed to connect to cluster (e.g. FQDN DNS could not resolve, no/wrong node IP provided, etc. access_denied: Invalid credentials supplied. invalid_license: The license string provided is invalid. Additional info can be fetched from the error_details object, which includes the violation code in case the license is valid but it terms are violated. repair_required: Cluster is in degraded mode and can only accept replacement nodes. When this happens, error_details contains two fields: failed_nodes and ‘replace_candidate’. The failed_nodes field is an array of objects, each describing a failed node with at least a uid field and an optional rack_id. replace_candidate is the uid of the node most suitable for replacement. ‘insufficient_node_memory’: An attempt to replace a dead node fails because the replaced node does not have enough memory. When this happens, error_details contains a required_memory field which indicates the node memory requirement. ‘insufficient_node_flash’: An attempt to replace a dead node fails because the replaced node does not have enough flash. When this happens, error_details contains a required_flash field which indicates the node flash requirement. ‘time_not_sync’: An attempt to join a node with system time not synchronized with the rest of the cluster. ‘rack_id_required’: An attempt to join a node with no rack_id in a rack-aware cluster. In addition, a ‘current_rack_ids’ field will include an array of currently used rack ids. ‘socket_directory_mismatch’: An attempt to join a node with a socket directory setting that differs from the cluster ‘node_config_mismatch’: An attempt to join a node with a configuration setting (e.g. confdir, osuser, installdir) that differs from the cluster path_error: A needed path does not exist or is not accessable. internal_error: A different, unspecified internal error was encountered. error_details An error-specific object that may contain additional information about the error. A common field in use is message which provides a more verbose error message. Example request
GET /bootstrap HTTP/1.1 Accept: application/json
Example response:
HTTP/1.1 200 OK { "bootstrap_status": { "start_time": "2014-08-29T11:19:49Z", "end_time": "2014-08-29T11:19:49Z", "state": "completed" }, "local_node_info": { "uid": 3, "software_version": "0.90.0-1", "cores": 2, "ephemeral_storage_path": "/var/opt/redislabs/tmp", "ephemeral_storage_size": 1018889.8304, "os_version": "Ubuntu 14.04 LTS", "persistent_storage_path": "/var/opt/redislabs/persist/redis", "persistent_storage_size": 1018889.8304, "total_memory": 24137, "uptime": 50278, "available_addrs": [{ 'address': '172.16.50.122', 'format': 'ipv4', 'if_name': 'eth0', 'private': True }, { 'address': '10.0.3.1', 'format': 'ipv4', 'if_name': 'lxcbr0', 'private': True }, { 'address': '172.17.0.1', 'format': 'ipv4', 'if_name': 'docker0', 'private': True }, { 'address': '2001:db8:0:f101::1', 'format': 'ipv6', 'if_name': 'eth0', 'private': False }] } }
-
POST/v1/bootstrap/(action)¶ Initiate bootstrapping.
The request must contain a bootstrap configuration JSON object, as described in
node.Bootstrapor a minimal subset.Bootstrapping is permitted only when the current bootstrap state is idle or error (in which case the process will restart with the new configuration).
This request is asynchronous - once the request has been accepted, the caller is expected to poll bootstrap status waiting for it to complete
1. Example request- Join Cluster:
POST /bootstrap/join_cluster HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "action": "join_cluster", "cluster": { "nodes":[ "1.1.1.1", "2.2.2.2" ] }, "node": { "paths": { "persistent_path": "/path/to/persistent/storage", "ephemeral_path": "/path/to/ephemeral/storage" "bigstore_path": "/path/to/bigstore/storage" }, "bigstore_driver": "rocksdb" "identity": { "addr":"1.2.3.4" "external_addr":["2001:0db8:85a3:0000:0000:8a2e:0370:7334", "3.4.5.6"] } }, "credentials": { "username": "my_username", "password": "my_password" } }
2. Example request- Create Cluster:
POST /bootstrap/create_cluster HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "action": "create_cluster", "cluster": { "nodes": [], "name": "my.cluster" }, "node": { "paths": { "persistent_path": "/path/to/persistent/storage", "ephemeral_path": "/path/to/ephemeral/storage" "bigstore_path": "/path/to/bigredis/storage" }, "identity": { "addr":"1.2.3.4" "external_addr":["2001:0db8:85a3:0000:0000:8a2e:0370:7334", "3.4.5.6"] }, "bigstore_driver": "rocksdb" }, "license": "", "credentials": { "username": "my_username", "password": "my_password" } }
See Object Attributes for more details on the Bootstrap object properties.
Status Codes: - 200 OK – request received and processing begins.
- 409 Conflict – bootstrap already in progress (check state)>
-
GET/v1/cluster¶ Get cluster info.
Example request:
GET /cluster HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "name": "my-rlec-cluster", "alert_settings": { ... }, "created_time": "2015-04-29T09:09:25Z", "email_alerts": false, "email_from": "", "rack_aware": false, "smtp_host": "", "smtp_password": "", "smtp_port": 25, "smtp_tls_mode": "none", "smtp_username": "", "crdt_rest_client_retries": "3", "crdt_rest_client_timeout": "20" }
Status Codes: - 200 OK – no error
Required permissions: view_cluster_info
-
PUT/v1/cluster¶ Update cluster settings.
If passed with the dry_run URL query string, the function will validate the cluster object, but will not apply the requested changes.
Example request:
PUT /cluster HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "email_alerts": true, "alert_settings": { "node_failed": true, "node_memory": { "enabled": true, "threshold": "80" } } }
The above request will enable email alerts and alert reporting for node failures and node removals.
Note that crdt_rest_client_timeout is in seconds.
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description bad_conf - Designated port is already bound.
bad_debuginfo_path - Debuginfo path doesn’t exist.
- Debuginfo path is inaccessible.
config_edit_conflict Cluster config was edited by another source simultaneously. Example response:
HTTP/1.1 200 OK { "name": "mycluster.mydomain.com", "email_alerts": true, "alert_settings": { "node_failed": true, "node_memory": { "enabled": true, "threshold": "80" } }, // additional fields... }
Status Codes: - 200 OK – no error.
- 400 Bad Request – bad content provided.
Required permissions: update_cluster
-
POST/v1/cluster/actions/(action)¶ Initiate a cluster-wide action.
The API allows only a single instance of any action type to be invoked at the same time, and violations of this requirement will result with a 409 CONFLICT response.
The caller is expected to query and process the results of the previously executed instance of the same action, which will be removed as soon as the new one is submitted.
Parameters: - action – The name of the action required.
The body content may provide additional action details. Currently it is not used.
Status Codes: - 200 OK – no error, action was initiated.
- 400 Bad Request – bad action or content provided.
- 409 Conflict – a conflicting action is already in progress.
Required permissions: start_cluster_action
-
GET/v1/cluster/actions/(action)¶
-
GET/v1/cluster/actions¶ Get the status of a currently executing, queued or completed cluster action.
Parameters: - action – The action to check.
If no action is specified, a JSON array of actions is returned, contained in an object such as this:
{ "actions": [ { "name": "action_name", "status": "queued", "progress": 0.0 } ] }
The response body for the action is a JSON object, as described in REST API actions overview.
Status Codes: - 200 OK – no error, response provides about an on-going action.
- 404 Not Found – action does not exist (i.e. not currently running and no available status of last run).
Required permissions: view_status_of_cluster_action
-
DELETE/v1/cluster/actions/(action)¶ Cancel a queued or executing cluster action, or remove the status of a previously executed and completed action.
Parameters: - action – The name of the action to cancel, currently no actions are supported.
Status Codes: - 200 OK – action will be cancelled when possible.
- 404 Not Found – action unknown or not currently running.
Required permissions: cancel_cluster_action
-
GET/v1/cluster/services_configuration¶ Get cluster services settings.
Example request:
GET /cluster/services_configuration HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "cm_server": { "operating_mode": "disabled" } "mdns_server": { "operating_mode": "enabled" } // additional services... }
Status Codes: - 200 OK – no error
Required permissions: view_cluster_info
-
PUT/v1/cluster/services_configuration¶ Update the cluster services settings.
Example request:
PUT /cluster/services_configuration HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "cm_server": "disabled", }
Example response:
HTTP/1.1 200 OK { "cm_server": { "operating_mode": "disabled" } "mdns_server": { "operating_mode": "enabled" } // additional services... }
Status Codes: - 200 OK – no error
Required permissions: update_cluster
-
GET/v1/logs¶ Get cluster events log. Returns an array of events.
The following table describes the event object:
Field Description time Timestamp when event happened. type Event type. Based on this additional fields may be available. additional fields Additional fields may be present based on event type. Each event contains a timestamp, and event code. Based on the code the event object may contain additional fields describing the event.
Query Parameters: - stime – Optional start time before which we don’t want events.
- etime – Optional end time after which we don’t want events.
- order – desc/asc - get events in descending or ascending order. Defaults to asc.
- limit – Optional maximum number of events to return.
- offset – Optional. Skip offset events before returning first one (useful for pagination).
Example request:
GET /logs?order=desc HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "time": "2014-08-29T11:19:49Z", "type": "bdb_name_updated", "severity": "INFO", "bdb_uid": "1" "old_val": "test", "new_val": "test123" }, { "time": "2014-08-29T11:18:48Z", "type": "cluster_bdb_created", "severity": "INFO", "bdb_uid": "1", "bdb_name": "test" }, { "time": "2014-08-29T11:17:49Z", "type": "cluster_node_joined", "severity": "INFO", "node_uid": 2 } ]
Status Codes: - 200 OK – no error
Required permissions: view_logged_events
-
GET/v1/jsonschema¶ Get the jsonschema of RLEC objects.
Query Parameters: - object – Optional. The RLEC object name: ‘cluster’, ‘node’, ‘bdb’ etc.
Example request:
GET /jsonschema?object=bdb HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "type": "object", "description": "An API object that represents a managed database in the cluster.", "properties": { .... } .... }
Status Codes: - 200 OK – success.
- 406 Not Acceptable – Invalid object.
-
PUT/v1/bdbs/(int: uid)/actions/import_reset_status¶ Reset database current import status (import_status) to idle if not in progress. As well clear exiting import_failure_reason if exits
Parameters: - uid – The unique ID of the database
Example request:
PUT /bdbs/1/actions/import_reset_status HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
The above request resets import_status to idle value if not in progress and clear failure reason message if exist from import_failure_reason.
Status Codes: - 200 OK – the request is accepted and is being processed.
- 404 Not Found – attempting to perform an action on a non-existing database.
- 406 Not Acceptable – not all the modules loaded to the database support ‘backup_restore’ capability
- 409 Conflict – database is currently busy with another action. In this context, this is a temporary condition and the request should be re-attempted later.
Required permissions: reset_bdb_current_import_status
-
POST/v1/nodes/(node_uid)/actions/(action)¶ Initiate a node action.
The API allows only a single instance of any action type to be invoked at the same time, and violations of this requirement will result with a 409 CONFLICT response.
The caller is expected to query and process the results of the previously executed instance of the same action, which will be removed as soon as the new one is submitted.
Parameters: - action –
The name of the action required. Currently supported actions are:
- remove: removes the node from the cluster after migrating
- all bound resources to other nodes. As soon as a successful remove request is received, the cluster will no longer automatically migrate resources (shards/endpoints) to the node, even if the remove task fails at some point.
maintenance_on: creates a snapshot of the node, migrate shards to other nodes and makes sure it can undergo maintenance.
If there aren’t enough resources to migrate shards out of the maintained node, set “keep_slave_shards”: true to keep the slave shards in place but demote any master shards.- maintenance_off: restores node to the state it was before maintenance started.
- By default it uses the latest node snapshot. Using “snapshot_name”: “…” can be used to restore from a different snapshot. To avoid restoring shards at the node, use “skip_shards_restore”: true.
enslave_node: enslave all bound resources.
The body content may provide additional action details. Currently it is not used.
Required permissions: start_node_action - action –
-
GET/v1/nodes/(node_uid)/actions/(action)¶
-
GET/v1/nodes/(node_uid)/actions¶ Get the status of a currently executing, queued or completed action, or all actions, on a specific node.
Parameters: - action – The action to check.
If no action is specified, an array with all actions for the specified node is returned, encapsualted in a JSON object as follows:
{ "actions": [ { "name": "remove_node", "node_uid": "1", "status": "running", "progress": 10 } ] }
In this form, if no actions are available the response will include an empty array.
See REST API actions overview for more details on action status and error codes.
Status Codes: - 200 OK – no error, response provides about an on-going action.
- 404 Not Found – action does not exist (i.e. not currently running and no available status of last run).
Required permissions: view_status_of_node_action
-
GET/v1/nodes/actions¶ Get the status of all currently executing, pending or completed actions on all nodes.
See /nodes/(node_uid)/actions for reference.
Status Codes: - 200 OK – no error, response provides about an on-going action.
Required permissions: view_status_of_all_node_actions
-
DELETE/v1/nodes/(node_uid)/actions/(action)¶ Cancel a queued or executing node action, or remove the status of a previously executed and completed action.
Parameters: - action – The name of the action to cancel.
Status Codes: - 200 OK – action will be cancelled when possible.
- 404 Not Found – action unknown or not currently running.
Required permissions: cancel_node_action
-
GET/v1/license¶ Returns the license details, including license string, expiration, and supported features.
Example request:
GET /license HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "license": "----- LICENSE START -----\ndi+iK...KniI9\n----- LICENSE END -----\n", "expired": true, "activation_date":"2018-12-31T00:00:00Z", "expiration_date":"2019-12-31T00:00:00Z" "shards_limit": 300, "features": ["bigstore"] }
Status Codes: - 200 OK – license is returned in the response body.
- 404 Not Found – no license is installed.
Required permissions: view_license
-
PUT/v1/license¶ Install a new license string.
The license is being validated on this call and if not acceptable, an error is immediately returned.
The request must be a JSON object with a single key named “license”.
Example request:
PUT /license HTTP/1.1 Accept: application/json { "license": "----- LICENSE START -----\ndi+iK...KniI9\n----- LICENSE END -----\n" }
Example response:
HTTP/1.1 200 OK
Status Codes: - 200 OK – license installed successfully.
- 400 Bad Request – invalid request, either bad JSON object or corrupted license was supplied.
- 406 Not Acceptable – license violation. A response body provides more details on the specific cause.
Required permissions: install_new_license
-
PUT/v1/nodes/(int: uid)¶ Update a node object.
Currently this operation supports editing the following attributes:
# addr
# external_addr
# recovery_path
# accept_servers
The addr attribute can only be updated for offline nodes and an error will be returned otherwise.
If an error status is returned, the body may contain a JSON object that describes the error.
Example request:
PUT /nodes/1 HTTP/1.1 Host: cluster.fqdn Accept: application/json Content-Type: application/json { "addr": "10.0.0.1" }
Example response:
HTTP/1.1 406 UNACCEPTABLE Content-Type: application/json { "error_code": "node_not_offline", "description": "Attempted to change node address while it is online" }
Parameters: - uid – The unique ID of the updated node.
Status Codes: - 200 OK – no error, the request has been processed.
- 406 Not Acceptable – update request cannot be processed.
- 400 Bad Request – bad content provided.
Required permissions: update_node
-
POST/v1/bootstrap/validate/(action)¶ Perform bootstrap validation.
The request must contain a bootstrap configuration JSON object similar to the one used for actual bootstrapping.
Unlike actual bootstrapping, this request blocks and immediately returns with a response.
When an error is encountered, a bootstrap status JSON object is returned.
Status Codes: - 200 OK – no error, validation was successful.
- 406 Not Acceptable – validation failed, bootstrap status is returned as body.
-
GET/v1/debuginfo/all¶ Fetch debuginfo from all nodes.
Example request:
GET /debuginfo/all HTTP/1.1
Example response:
HTTP/1.1 200 OK Content-Type: application/x-gzip Content-Length: 653350 Content-Disposition: attachment; filename=debuginfo.tar.gz
Status Codes: - 200 OK – success.
- 500 Internal Server Error – failed to get debuginfo.
Required permissions: view_debugging_info
-
GET/v1/debuginfo/all/bdb/(int: bdb_uid)¶ Fetch debuginfo from all nodes that are relevent to given bdb uid.
Example request:
GET /debuginfo/all/bdb/1 HTTP/1.1
Example response:
HTTP/1.1 200 OK Content-Type: application/x-gzip Content-Length: 653350 Content-Disposition: attachment; filename=debuginfo.tar.gz
Status Codes: - 200 OK – success.
- 500 Internal Server Error – failed to get debuginfo.
Required permissions: view_debugging_info
-
GET/v1/debuginfo/node¶ Fetch debuginfo tarfile which contains logs and other system information used for troubleshooting.
Required permissions: view_debugging_info
-
GET/v1/debuginfo/node/bdb/(int: bdb_uid)¶ Fetch debuginfo tarfile which contains logs and other system information used for troubleshooting, for the given bdb.
Required permissions: view_debugging_info
-
GET/v1/cluster/stats/last¶ Get the last cluster stat.
Query Parameters: - interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week. Default: 1sec.
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /cluster/stats/1?interval=1sec&stime=2015-10-14T06:44:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "conns": 0.0, "cpu_idle": 0.8424999999988358, "cpu_system": 0.01749999999992724, "cpu_user": 0.08374999999978172, "egress_bytes": 7403.0, "ephemeral_storage_avail": 151638712320.0, "ephemeral_storage_free": 162375925760.0, "etime": "2015-10-14T06:44:01Z", "free_memory": 5862400000.0, "ingress_bytes": 7469.0, "interval": "1sec", "persistent_storage_avail": 151638712320.0, "persistent_storage_free": 162375925760.0, "stime": "2015-10-14T06:44:00Z", "total_req": 0.0 }
Status Codes: - 200 OK – no error
- 500 Internal Server Error – Internal Server Error
Required permissions: view_cluster_stats
-
GET/v1/shards/stats/last/(int: uid)¶ Get stats for a specific shard.
Parameters: - uid – The unique ID of the shard requested.
Query Parameters: - interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week. Default: 1sec.
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /shards/stats/last/1?interval=1sec&stime=2015-05-28T08:27:35Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "interval": "1sec", "stime": "2015-05-28T08:27:35Z", "etime": "2015-05-28T08:27:36Z", "used_memory_peak": 5888264.0, "used_memory_rss": 5888264.0, "read_hits": 0.0, "pubsub_patterns": 0.0, "no_of_keys": 0.0, "mem_size_lua": 35840.0, "last_save_time": 1432541051.0, "sync_partial_ok": 0.0, "connected_clients": 9.0, "avg_ttl": 0.0, "write_misses": 0.0, "used_memory": 5651440.0, "sync_full": 0.0, "expired_objects": 0.0, "total_req": 0.0, "blocked_clients": 0.0, "pubsub_channels": 0.0, "evicted_objects": 0.0, "no_of_expires": 0.0, "interval": "1sec", "write_hits": 0.0, "read_misses": 0.0, "sync_partial_err": 0.0, "rdb_changes_since_last_save": 0.0 } } :statuscode 200: no error :statuscode 404: shard does not exist :statuscode 406: shard isn't currently active :statuscode 406: shard isn't currently active :required permissions: view_shard_stats
-
GET/v1/shards/stats/last¶ Get last stats for all shards.
Query Parameters: - interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week. Default: 1sec.
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /shards/stats/last?interval=1sec&stime=015-05-27T08:27:35Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "interval": "1sec", "stime": "2015-05-28T08:27:35Z", "etime": "2015-05-28T08:28:36Z", "used_memory_peak": 5888264.0, "used_memory_rss": 5888264.0, "read_hits": 0.0, "pubsub_patterns": 0.0, "no_of_keys": 0.0, "mem_size_lua": 35840.0, "last_save_time": 1432541051.0, "sync_partial_ok": 0.0, "connected_clients": 9.0, "avg_ttl": 0.0, "write_misses": 0.0, "used_memory": 5651440.0, "sync_full": 0.0, "expired_objects": 0.0, "total_req": 0.0, "blocked_clients": 0.0, "pubsub_channels": 0.0, "evicted_objects": 0.0, "no_of_expires": 0.0, "interval": "1sec", "write_hits": 0.0, "read_misses": 0.0, "sync_partial_err": 0.0, "rdb_changes_since_last_save": 0.0 }, "2": { "interval": "1sec", "stime": "2015-05-28T08:27:40Z", "etime": "2015-05-28T08:28:45Z", // additional fields... } } :statuscode 200: no error :statuscode 404: no shards exist :required permissions: view_all_shard_stats
-
GET/v1/nodes/stats/last/(int: uid)¶ Get the last stats of a node.
Parameters: - uid – The unique ID of the node requested.
Query Parameters: - interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week. Default: 1sec.
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /nodes/stats/last/1?interval=1sec&stime=2015-10-13T09:01:54Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "conns": 0.0, "cpu_idle": 0.8049999999930151, "cpu_system": 0.02750000000014552, "cpu_user": 0.12000000000080036, "cur_aof_rewrites": 0.0, "egress_bytes": 2169.0, "ephemeral_storage_avail": 75920293888.0, "ephemeral_storage_free": 81288900608.0, "etime": "2015-10-13T09:01:55Z", "free_memory": 3285381120.0, "ingress_bytes": 3020.0, "interval": "1sec", "persistent_storage_avail": 75920293888.0, "persistent_storage_free": 81288900608.0, "stime": "2015-10-13T09:01:54Z", "total_req": 0.0 } } :statuscode 200: no error :statuscode 404: node does not exist :statuscode 406: node isn't currently active :statuscode 503: node is in recovery state :required permissions: view_node_stats
-
GET/v1/nodes/stats/last¶ Get stats for all nodes.
Query Parameters: - interval – Optional time interval for which we want stats: 1sec/10sec/5min/15min/1hour/12hour/1week. Default: 1sec.
- stime –
Optional start time from which we want the stats. Should comply with the ISO_8601 format
- etime –
Optional end time after which we don’t want the stats. Should comply with the ISO_8601 format
Example request:
GET /nodes/stats/last?interval=1sec&stime=2015-10-14T06:29:43Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "1": { "conns": 0.0, "cpu_idle": 0.922500000015134, "cpu_system": 0.007499999999708962, "cpu_user": 0.01749999999810825, "cur_aof_rewrites": 0.0, "egress_bytes": 7887.0, "ephemeral_storage_avail": 75821363200.0, "ephemeral_storage_free": 81189969920.0, "etime": "2015-10-14T06:29:44Z", "free_memory": 2956963840.0, "ingress_bytes": 4950.0, "interval": "1sec", "persistent_storage_avail": 75821363200.0, "persistent_storage_free": 81189969920.0, "stime": "2015-10-14T06:29:43Z", "total_req": 0.0 }, "2": { "conns": 0.0, "cpu_idle": 0.922500000015134, // additional fields... } }
Status Codes: - 200 OK – no error
- 404 Not Found – no nodes exist
Required permissions: view_all_nodes_stats
-
GET/v1/endpoints/stats¶ Get stats for all endpoint-proxy links. Note: this method will return both endpoints and listeners stats for backwards compatability.
Query Parameters: - endpoint uid note: the uid format in the response is as follows: “BDB_UID:ENDPOINT_UID:PROXY_UID”,
- for example: “1:2:3” is BDB_uid=1, ENDPOINT_UID=2, PROXY_UID=3
Example request:
GET /endpoints/stats?interval=1hour&stime=2014-08-28T10:00:00Z HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid" : "365:1:1", "intervals" : [ { "interval" : "10sec", "total_req" : 0, "egress_bytes" : 0, "cmd_get" : 0, "monitor_sessions_count" : 0, "auth_errors" : 0, "acc_latency" : 0, "stime" : "2017-01-12T14:59:50Z", "write_res" : 0, "total_connections_received" : 0, "cmd_set" : 0, "read_req" : 0, "max_connections_exceeded" : 0, "acc_write_latency" : 0, "write_req" : 0, "other_res" : 0, "cmd_flush" : 0, "acc_read_latency" : 0, "other_req" : 0, "conns" : 0, "write_started_res" : 0, "cmd_touch" : 0, "read_res" : 0, "auth_cmds" : 0, "etime" : "2017-01-12T15:00:00Z", "total_started_res" : 0, "ingress_bytes" : 0, "last_res_time" : 0, "read_started_res" : 0, "acc_other_latency" : 0, "total_res" : 0, "last_req_time" : 0, "other_started_res" : 0 } ] }, { "intervals" : [ { "acc_read_latency" : 0, "other_req" : 0, "etime" : "2017-01-12T15:00:00Z", "auth_cmds" : 0, "total_started_res" : 0, "write_started_res" : 0, "cmd_touch" : 0, "conns" : 0, "read_res" : 0, "total_res" : 0, "other_started_res" : 0, "last_req_time" : 0, "read_started_res" : 0, "last_res_time" : 0, "ingress_bytes" : 0, "acc_other_latency" : 0, "egress_bytes" : 0, "interval" : "10sec", "total_req" : 0, "acc_latency" : 0, "auth_errors" : 0, "cmd_get" : 0, "monitor_sessions_count" : 0, "read_req" : 0, "max_connections_exceeded" : 0, "total_connections_received" : 0, "cmd_set" : 0, "acc_write_latency" : 0, "write_req" : 0, "stime" : "2017-01-12T14:59:50Z", "write_res" : 0, "cmd_flush" : 0, "other_res" : 0 } ], "uid" : "333:1:2" } ]
Status Codes: - 200 OK – no error
Required permissions: view_endpoint_stats
-
GET/v1/bdbs/(bdb_uid)/peer_stats/(int: uid)¶ Get stats for a specific CRDB peer instance.
Parameters: - bdb_uid – The unique ID of the local CRDB instance.
- uid – The peer instance uid, as specified in the CRDB instance list.
Query Parameters: Example request:
GET /bdbs/1/peer_stats/3?interval=5min HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "intervals": [ { "egress_bytes": 0.0, "egress_bytes_decompressed": 0.0, "etime": "2017-10-22T19:30:00Z", "ingress_bytes": 18528, "ingress_bytes_decompressed": 185992, "interval": "5min", "local_ingress_lag_time": 0.244, "pending_local_writes_max": 0.0, "pending_local_writes_min": 0.0, "stime": "2017-10-22T19:25:00Z" }, { "egress_bytes": 0.0, "egress_bytes_decompressed": 0.0, "etime": "2017-10-22T19:35:00Z", "ingress_bytes": 18, "ingress_bytes_decompressed": 192, "interval": "5min", "local_ingress_lag_time": 0.0, "pending_local_writes_max": 0.0, "pending_local_writes_min": 0.0, "stime": "2017-10-22T19:30:00Z" } ], "uid": "3" }
Status Codes: - 200 OK – no error
- 404 Not Found – database or peer does not exist.
- 406 Not Acceptable – database is not a crdb.
Required permissions: view_bdb_stats
-
GET/v1/bdbs/(bdb_uid)/peer_stats¶ Get stats for a all peer instances of a local CRDB instance.
Parameters: - bdb_uid – The unique ID of the local CRDB instance.
Query Parameters: Example request:
GET /bdbs/1/peer_stats?interval=5min HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "peer_stats": [ { "intervals": [ { "egress_bytes": 0.0, "egress_bytes_decompressed": 0.0, "etime": "2017-10-22T19:30:00Z", "ingress_bytes": 18528, "ingress_bytes_decompressed": 185992, "interval": "5min", "local_ingress_lag_time": 0.244, "pending_local_writes_max": 0.0, "pending_local_writes_min": 0.0, "stime": "2017-10-22T19:25:00Z" }, { "egress_bytes": 0.0, "egress_bytes_decompressed": 0.0, "etime": "2017-10-22T19:35:00Z", "ingress_bytes": 18, "ingress_bytes_decompressed": 192, "interval": "5min", "local_ingress_lag_time": 0.0, "pending_local_writes_max": 0.0, "pending_local_writes_min": 0.0, "stime": "2017-10-22T19:30:00Z" } ], "uid": "3" } ] }
Status Codes: - 200 OK – no error
- 404 Not Found – database does not exist.
- 406 Not Acceptable – database is not a crdb.
Required permissions: view_bdb_stats
-
GET/v1/bdbs/(bdb_uid)/sync_source_stats/(int: uid)¶ Get stats for a specific syncer (replica-of) instance.
Parameters: - bdb_uid – The unique ID of the local database.
- uid – The sync_source uid.
Query Parameters: Example request:
GET /bdbs/1/sync_source_stats/1?interval=5min HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "intervals": [ { "etime": "2017-10-22T19:30:00Z", "ingress_bytes": 18528, "ingress_bytes_decompressed": 185992, "interval": "5min", "local_ingress_lag_time": 0.244, "stime": "2017-10-22T19:25:00Z" }, { "etime": "2017-10-22T19:35:00Z", "ingress_bytes": 18, "ingress_bytes_decompressed": 192, "interval": "5min", "local_ingress_lag_time": 0.0, "stime": "2017-10-22T19:30:00Z" } ], "uid": "1" }
Status Codes: - 200 OK – no error
- 404 Not Found – database or sync_source do not exist.
Required permissions: view_bdb_stats
-
GET/v1/bdbs/(bdb_uid)/sync_source_stats¶ Get stats for a all syncer sources of a local database.
Parameters: - bdb_uid – The unique ID of the local database.
Query Parameters: Example request:
GET /bdbs/1/sync_source_stats?interval=5min HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "sync_source_stats": [ { "intervals": [ { "etime": "2017-10-22T19:30:00Z", "ingress_bytes": 18528, "ingress_bytes_decompressed": 185992, "interval": "5min", "local_ingress_lag_time": 0.244, "stime": "2017-10-22T19:25:00Z" }, { "etime": "2017-10-22T19:35:00Z", "ingress_bytes": 18, "ingress_bytes_decompressed": 192, "interval": "5min", "local_ingress_lag_time": 0.0, "stime": "2017-10-22T19:30:00Z" } ], "uid": "1" } ] }
Status Codes: - 200 OK – no error
- 404 Not Found – database does not exist.
Required permissions: view_bdb_stats
-
POST/v1/roles¶ Create a new role.
Example request:
POST /roles HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "name": "DBA", "management": "admin" }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "DBA", "management": "admin" }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists missing_field A needed field is missing Status Codes: - 200 OK – success, role is created.
- 400 Bad Request – bad or missing configuration parameters.
- 501 Not Implemented – cluster doesn’t support roles yet.
Required permissions: create_role
-
PUT/v1/roles/(int: uid)¶ Update an existing role object.
Example request:
PUT /roles/17 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "management": "cluster_member" }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "DBA", "management": "cluster_member" }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists change_last_admin_role_not_allowed At least one user with admin role should exist. Status Codes: - 200 OK – success, role is created.
- 400 Bad Request – bad or missing configuration parameters.
- 404 Not Found – attempting to change a non-existing role.
- 501 Not Implemented – cluster doesn’t support roles yet.
Required permissions: update_role
-
DELETE/v1/roles/(int: uid)¶ Delete a role object.
Parameters: - uid – The role unique ID.
Example request:
DELETE /roles/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – success, the role is deleted.
- 404 Not Found – role does not exist.
- 406 Not Acceptable – the request is not acceptable.
- 501 Not Implemented – cluster doesn’t support roles yet.
Required permissions: delete_role
-
GET/v1/roles/(int: uid)¶ Get a single role object.
Parameters: - uid – The RLEC role unique ID.
Example request:
GET /roles/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "DBA", "management": "admin" }
Status Codes: - 200 OK – success.
- 403 Forbidden – operation is forbidden.
- 404 Not Found – role does not exist.
- 501 Not Implemented – cluster doesn’t support roles yet.
Required permissions: view_role_info
-
GET/v1/roles¶ Get all role objects.
Example request:
GET /roles HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 1, "name": "Admin", "management": "admin }, { "uid": 2, "name": "Cluster"Member', "management": "cluster_member }, { "uid": 3, "name": "Cluster"Viewer', "management": "cluster_viewer }, { "uid": 4, "name": "DB"Member', "management": "db_member }, { "uid": 5, "name": "DB"Viewer', "management": "db_viewer }, { "uid": 6, "name": "None", "management": "none }, { "uid": 17, "name": "DBA", "management": "admin" } ]
Status Codes: - 200 OK – no error
- 501 Not Implemented – cluster doesn’t support roles yet.
Required permissions: view_all_roles_info
-
POST/v1/redis_acls¶ Create a new redis_acl object (a named redis acl)
Example request:
POST /redis_acls HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "name": "Geo", "acl": "~* +@geo" }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Geo", "acl": "~* +@geo" }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists missing_field A needed field is missing invalid_param A parameter has an illegal value Status Codes: - 200 OK – success, redis_acl is created.
- 400 Bad Request – bad or missing configuration parameters.
- 501 Not Implemented – cluster doesn’t support redis_acl yet.
Required permissions: create_redis_acl
-
PUT/v1/redis_acls/(int: uid)¶ Update an existing redis_acl object.
Example request:
PUT /redis_acls/17 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "acl": "~* +@geo -@dangerous" }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Geo", "acl": "~* +@geo -@dangerous" }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists invalid_param A parameter has an illegal value Status Codes: - 200 OK – success, redis_acl was updated.
- 400 Bad Request – bad or missing configuration parameters.
- 404 Not Found – attempting to change a non-existing redis_acl.
- 409 Conflict – cannot change a read-only object
- 501 Not Implemented – cluster doesn’t support redis_acl yet.
Required permissions: update_redis_acl
-
DELETE/v1/redis_acls/(int: uid)¶ Delete a redis_acl object.
Parameters: - uid – The redis_acl unique ID.
Example request:
DELETE /redis_acls/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – success, the redis_acl is deleted.
- 406 Not Acceptable – the request is not acceptable.
- 409 Conflict – cannot delete a read-only object
- 501 Not Implemented – cluster doesn’t support redis_acl yet.
Required permissions: delete_redis_acl
-
GET/v1/redis_acls/(int: uid)¶ Get a single redis_acl object.
Parameters: - uid – The object’s unique ID.
Example request:
GET /redis_acls/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Geo", "acl": "~* +@geo" }
Status Codes: - 200 OK – success.
- 403 Forbidden – operation is forbidden.
- 404 Not Found – redis_acl does not exist.
- 501 Not Implemented – cluster doesn’t support redis_acl yet.
Required permissions: view_redis_acl_info
-
GET/v1/redis_acls¶ Get all redis_acl objects.
Example request:
GET /redis_acls HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 1, "name": "Full Access", "acl": "+@all ~*" }, { "uid": 2, "name": "Read Only", "acl": "+@read ~*" }, { "uid": 3, "name": "Not Dangerous", "acl": "+@all -@dangerous ~*" }, { "uid": 17, "name": "Geo", "acl": "~* +@geo" } ]
Status Codes: - 200 OK – no error
- 501 Not Implemented – cluster doesn’t support redis_acl yet.
Required permissions: view_all_redis_acls_info
-
POST/v1/users¶ Create a new RLEC user.
The request must contain a single JSON user object, with an email and a password:
Example request:
POST /users HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "email": "user@redislabs.com", "password": "my-password", "name": "John Doe", "email_alerts": true, "bdbs_email_alerts": ["1","2"], "role": "db_viewer", "auth_method": "regular" }
Note that with RBAC-enabled clusters the role is replaced with role_uids.
“email_alerts” can be configured either as: true - user will receive alerts for all databases configured in “bdbs_email_alerts” or for all the databases if “bdbs_email_alerts” is not configured. “bdbs_email_alerts” cab be a list of databases uids or [‘all’] meaning all databases. false - user will not receive alerts for any databases The response includes the newly created user object.
Example response:
HTTP/1.1 200 OK { "uid": 1, "password_issue_date": "2017-03-07T15:11:08Z", "email": "user@redislabs.com", "name": "Jane Poe", "email_alerts": true, "bdbs_email_alerts": ["1","2"], "role": "db_viewer", "auth_method": "regular" }
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description password_not_complex The given password is not complex enough (Only work when the password_complexity feature is enabled). email_already_exists The given email is already taken. name_already_exists The given name is already taken. Status Codes: - 200 OK – success, user is created.
- 400 Bad Request – bad or missing configuration parameters.
- 409 Conflict – user with the same email already exists.
Required permissions: create_new_user
-
PUT/v1/users/(int: uid)¶ Update a RLEC user configuration.
Parameters: - uid – The RLEC user unique ID.
Example request:
PUT /users/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "name": "Jane Poe", "email_alerts": false }
The response includes the updated user object.
Example response:
HTTP/1.1 200 OK { "uid": 1, "password_issue_date": "2017-03-07T15:11:08Z", "email": "user@redislabs.com", "name": "Jane Poe", "email_alerts": false, "role": "db_viewer", "auth_method": "regular" }
Note that with RBAC-enabled clusters the role is replaced with role_uids.
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description password_not_complex The given password is not complex enough (Only work when the password_complexity feature is enabled). new_password_same_as_current The given new password is identical to the old password. email_already_exists The given email is already taken. change_last_admin_role_not_allowed At least one user with admin role should exist. Status Codes: - 200 OK – success, the user is updated.
- 400 Bad Request – bad or missing configuration parameters.
- 404 Not Found – attempting to change a non-existing user.
- 406 Not Acceptable – the requested configuration is invalid.
Required permissions: update_user (Although any user can change his own name, password or alerts)
-
DELETE/v1/users/(int: uid)¶ Delete a RLEC user.
Parameters: - uid – The RLEC user unique ID.
Example request:
DELETE /users/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
The above request attempts to completely delete a user with unique ID 1.
Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – success, the user is deleted.
- 406 Not Acceptable – the request is not acceptable.
Required permissions: delete_user
-
GET/v1/users/(int: uid)¶ Get a single RLEC user.
Parameters: - uid – The RLEC user unique ID.
Example request:
GET /users/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 1, "password_issue_date": "2017-03-07T15:11:08Z", "role": "db_viewer", "email_alerts": true, "bdbs_email_alerts": ["1,"2"], "email": "user@redislabs.com", "name": "John Doe", "auth_method": "regular" }
Status Codes: - 200 OK – success.
- 403 Forbidden – operation is forbidden.
- 404 Not Found – user does not exist.
Required permissions: view_user_info
-
GET/v1/users¶ Get all RLEC users.
Example request:
GET /users HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 1, "password_issue_date": "2017-03-02T09:43:34Z", "email": "user@redislabs.com", "name": "John Doe", "email_alerts": true, "bdbs_email_alerts": ["1","2"], "role": "admin", "auth_method": "regular" }, { "uid": 2, "password_issue_date": "2017-03-02T09:43:34Z", "email": "user2@redislabs.com", "name": "Jane Poe", "email_alerts": true, "role": "db_viewer", "auth_method": "external" } ]
Status Codes: - 200 OK – no error
Required permissions: view_all_users_info
Authorize a RLEC user.
In order to use the rest-api a user must be authorized using JSON Web Token (JWT) In order to obtain a valid token a request should be made to /users/authorize with a valid username and password.
JSON Parameters: - username – The RLEC user’s username.
- password – The RLEC user’s password.
- ttl – Time To Live - The amount of time in seconds the token will be valid
Example request:
POST /users/authorize HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "username": "user@redislabs.com", "password": "my_password" }
Example response:
HTTP/1.1 200 OK Content-Type': 'application/json { "access_token": "eyJ5bGciOiKIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpYXViOjE0NjU0NzU0ODYsInVpZFI1IjEiLCJleHAiOjE0NjU0Nz30OTZ9.2xYXumd1rDoE0edFzcLElMOHsshaqQk2HUNgdsUKxMU" }
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description password_expired The password has expired and must be changed. Status Codes: - 200 OK – the user is authorized.
- 400 Bad Request – the request could not be understood by the server due to malformed syntax.
- 401 Unauthorized – the user is unauthorized.
-
POST/v1/users/refresh_jwt¶ Get a new authentication token.
Takes a valid token and returns a token that is issued at the time of the request.
JSON Parameters: - ttl – Time To Live - The amount of time in seconds the token will be valid
Example request:
POST /users/refresh_jwt HTTP/1.1 Host: cnm.cluster.fqdn Authorization: JWT eyJ5bGciOiKIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpYXViOjE0NjU0NzU0ODYsInVpZFI1IjEiLCJleHAiOjE0NjU0Nz30OTZ9.2xYXumd1rDoE0edFzcLElMOHsshaqQk2HUNgdsUKxMU
Example response:
HTTP/1.1 200 OK Content-Type': 'application/json { "access_token": "eyJ5bGciOiKIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpYXViOjE0NjU0NzU0ODYsInVpZFI1IjEiLCJleHAiOjE0NjU0Nz30OTZ9.2xYXumd1rDoE0edFzcLElMOHsshaqQk2HUNgdsUKxMU" }
Status Codes: - 200 OK – A new token is given.
- 401 Unauthorized – the token is invalid or password has expired.
-
GET/v1/suffixes¶ Get all DNS suffixes in the cluster.
The response body contains a JSON array with all suffixes, represented as suffix objects.
Example request:
GET /suffixes HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "name": "cluster.fqdn", // additional fields... }, { "name": "internal.cluster.fqdn", // additional fields... } ]
Status Codes: - 200 OK – no error
-
GET/v1/suffix/(string: name)¶ Get single DNS suffix.
Parameters: - name (string) – The unique Name of the suffix requested.
Example request:
GET /suffix/cluster.fqdn HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "name": "cluster.fqdn", // additional fields... }
See Object Attributes for more details on additional suffix parameters
Status Codes: - 200 OK – no error
- 404 Not Found – suffix name does not exist
-
GET/v1/modules¶ List available modules, i.e. modules stored within the CCS Example request:
GET /modules HTTP/1.1 Host: 127.0.0.1:9443 Accept: /
Required permissions: view_cluster_modules
-
GET/v1/modules/(string: uid)¶ Get specific available modules, i.e. modules stored within the CCS Example request:
curl -k -u <CREDS> https://<HOST>/modules/10682975ad54eed67391cde5bb98f93e97298008d77410ad1548e45784f3c604 .. sourcecode:: http
GET /modules HTTP/1.1 Host: 127.0.0.1:9443 User-Agent: curl/7.51.0 Accept: /
Required permissions: view_cluster_modules
-
DELETE/v1/modules/(string: uid)¶ Delete a Module.
Parameters: - uid – The Module unique ID.
Example request:
DELETE /module/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
The above request attempts to completely delete a module with unique ID.
Example response:
HTTP/1.1 200 OK Content-Length: 0
Status Codes: - 200 OK – success, the module is deleted.
- 404 Not Found – attempting to delete a non-existing module.
- 406 Not Acceptable – the request is not acceptable.
Required permissions: update_cluster
-
GET/v1/cluster/module-capabilities¶ List possible redis module capabilities Example request:
GET /cluster/module-capabilities HTTP/1.1 Host: cnm.cluster.fqdn Accept: */*
Example response:
HTTP/1.1 200 OK { "all_capabilities": [ {"name": "types", "desc": "module has its own types and not only operate on existing redis types"}, {"name": "no_multi_key", "desc": "module has no methods that operate on multiple keys"} // additional capabilities... ] }
Required permissions: view_cluster_modules
-
POST/v1/modules¶ Uploads a new module into the CCS
The request must contain a Redis module bundled using RedisModule Packer. https://github.com/RedisLabs/RAMP
Example request:
POST /modules HTTP/1.1 Host: 127.0.0.1:9443 Accept: */* Content-Length: 865 Expect: 100-continue Content-Type: multipart/form-data; boundary=------------------------4751ac3b332ace13
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description no_module module wasn’t provided invalid_module Module either corrupted or packaged files are wrong module_exists Module already in system min_redis_pack_version Module isn’t supported yet in this redis pack unsupported_module_capabilities The module does not support required capabilities os_not_supported This module is only supported with these operating systems: <list supported OSs>This endpoint does not support dependencies, see v2dependencies_not_supported Status Codes: - 400 Bad Request – either missing module file, or an invalid module file.
Required permissions: update_cluster
-
POST/v1/bdbs/(string: uid)/modules/upgrade¶
-
POST/v1/modules/upgrade/bdb/(string: uid)¶ Upgrades module version on specific BDB
Example request:
POST /bdbs/1/modules/upgrade HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "modules": [ {"module_name": "ReJson", "current_semantic_version": "2.2.1", "new_module": "aa3648d79bd4082d414587c42ea0b234"} ], // Optional fields to fine-tune restart and failover behavior: "preserve_roles": True, "may_discard_data": False }
Example response:
HTTP/1.1 200 OK { "uid": 1, "name": "name of database #1", "module_id": "aa3648d79bd4082d414587c42ea0b234", "module_name": "ReJson", "semantic_version": "2.2.2" // additional fields... }
See Object Attributes for more details on additional db parameters
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description missing_module Module is not present in cluster. module_downgrade_unsupported Module downgrade is not allowed. redis_incompatible_version Module min_redis_version is bigger the current redis version. redis_pack_incompatible_version Module min_redis_pack_version is bigger the current Redis Enterprise version. unsupported_module_capabilities New version of module does support all the capabilities needed for the database configuration Status Codes: - 200 OK – success, module updated on bdb.
- 404 Not Found – bdb or node not found.
- 400 Bad Request – bad or missing configuration parameters.
- 406 Not Acceptable – the requested configuration is invalid.
Required permissions: edit_bdb_module
-
POST/v1/bdbs/(string: uid)/modules/config¶
-
POST/v1/modules/config/bdb/(string: uid)¶ Use module runtime configuration command (if defined) to configure new arguments for the module.
Example request:
POST /bdbs/1/modules/upgrade HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "module_name": "ft", "module_args": "MINPREFIX 3 MAXEXPANSIONS 1000" }
Example response:
HTTP/1.1 200 OK Content-Length: 0
When errors are reported, the server may return a JSON object with error_code and message field that provide additional information. The following are possible error_code values:
Code Description db_not_exist Database with given uid doesn’t exist in cluster. missing_field “module_name” or “module_args” are not defined in request invalid_schema json object received is not a dict object param_error “module_args” parameter was not parsed properly module_not_exist Module with given “module_name” does not exist for the database Status Codes: - 200 OK – success, module updated on bdb.
- 404 Not Found – bdb not found.
- 400 Bad Request – bad or missing configuration parameters.
- 406 Not Acceptable – module does not support runtime configuration of arguments.
Required permissions: edit_bdb_module
-
PUT/v1/cluster/ldap¶ Set or update cluster LDAP configuration.
Example request:
POST /cluster/ldap HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "uris": [ "ldap://ldap.redislabs.com:389" ], "bind_dn": "rl_admin", "bind_pass": "secret" "user_dn_template": "cn=%u,dc=example,dc=org", "dn_group_attr": "MemberOf" }
Possible `error_code`s:
Code Description illegal_fields_combination An unacceptable combination of fields was specified for the configuration object (e.g.: two mutually-exclusive fields), or a required field is missing. Status Codes: - 200 OK – success, LDAP config has been set.
- 400 Bad Request – bad or missing configuration parameters.
Required permissions: config_ldap
-
GET/v1/cluster/ldap¶ Get the LDAP configuration, as JSON.
Example request:
GET /cluster/ldap HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "bind_dn": "rl_admin", "bind_pass": "***", "ca_cert": "", "control_plane": false, "data_plane": false, "dn_group_attr": "MemberOf", "dn_group_query": {}, "starttls": "disabled", "uris": ["ldap://ldap.example.org:636"], "user_dn_query": {}, "user_dn_template": "cn=%u, ou=users,dc=example,dc=org" }
Status Codes: - 200 OK – success
Required permissions: view_ldap_config
-
DELETE/v1/cluster/ldap¶ Clear the LDAP configuration.
Example request:
DELETE /cluster/ldap HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK
Status Codes: - 200 OK – success
Required permissions: config_ldap
-
POST/v1/ldap_mappings¶ Create a new LDAP mapping.
Example request:
POST /ldap_mappings HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "name": "Admins", "dn": "OU=ops.group,DC=redislabs,DC=com", "email": "ops.group@redislabs.com", "role_uids": ["1"] }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Admins", "dn": "OU=ops.group,DC=redislabs,DC=com", "email": "ops.group@redislabs.com", "role_uids": ["1"] }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists missing_field A needed field is missing invalid_dn_param A dn parameter has an illegal value invalid_name_param A name parameter has an illegal value invalid_role_uids_param A role_uids parameter has an illegal value Status Codes: - 200 OK – success, an LDAP-mapping object is created.
- 400 Bad Request – bad or missing configuration parameters.
- 501 Not Implemented – cluster doesn’t support LDAP mappings yet.
Required permissions: create_ldap_mapping
-
GET/v1/ldap_mappings/(int: uid)¶ Get a single ldap_mapping object.
Parameters: - uid – The object’s unique ID.
Example request:
GET /ldap_mappings/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Admins", "dn": "OU=ops.group,DC=redislabs,DC=com", "email": "ops.group@redislabs.com", "role_uids": ["1"], "email_alerts": true, "bdbs_email_alerts": ["1,"2"], "cluster_email_alerts": true }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. ldap_mapping_not_exist An object does not exist Status Codes: - 200 OK – success.
- 403 Forbidden – operation is forbidden.
- 404 Not Found – ldap_mapping does not exist.
- 501 Not Implemented – cluster doesn’t support LDAP mappings yet.
Required permissions: view_ldap_mapping_info
-
GET/v1/ldap_mappings¶ Get all ldap_mapping objects.
Example request:
GET /ldap_mappings HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK [ { "uid": 17, "name": "Admins", "dn": "OU=ops.group,DC=redislabs,DC=com", "email": "ops.group@redislabs.com", "role_uids": ["1"], "email_alerts": true, "bdbs_email_alerts": ["1,"2"], "cluster_email_alerts": true } ]
Status Codes: - 200 OK – no error
Required permissions: view_all_ldap_mappings_info
-
PUT/v1/ldap_mappings/(int: uid)¶ Update an existing ldap_mapping object.
Example request:
PUT /ldap_mappings/17 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json { "dn": "OU=ops,DC=redislabs,DC=com", "email": "ops@redislabs.com", "email_alerts": true, "bdbs_email_alerts": ["1,"2"], "cluster_email_alerts": true }
Example response:
HTTP/1.1 200 OK { "uid": 17, "name": "Admins", "dn": "OU=ops,DC=redislabs,DC=com", "email": "ops@redislabs.com" "role_uids": ["1"], "email_alerts": true, "bdbs_email_alerts": ["1,"2"], "cluster_email_alerts": true }
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. name_already_exists An object of the same type and name exists ldap_mapping_not_exist An object does not exist invalid_dn_param A dn parameter has an illegal value invalid_name_param A name parameter has an illegal value invalid_role_uids_param A role_uids parameter has an illegal value invalid_account_id_param A account_id parameter has an illegal value Status Codes: - 200 OK – success, LDAP mapping is created.
- 400 Bad Request – bad or missing configuration parameters.
- 404 Not Found – attempting to change a non-existing LDAP mapping.
- 501 Not Implemented – cluster doesn’t support LDAP mapping yet.
Required permissions: update_ldap_mapping
-
DELETE/v1/ldap_mappings/(int: uid)¶ Delete an LDAP mapping object.
Parameters: - uid – The ldap_mapping unique ID.
Example request:
DELETE /ldap_mappings/1 HTTP/1.1 Host: cnm.cluster.fqdn Accept: application/json
Example response:
HTTP/1.1 200 OK Content-Length: 0
Possible `error_code`s:
Code Description unsupported_resource The cluster is not yet capable to handle this resource type. This could happen in a partially-upgraded cluster, where some of the nodes are still of a previous version. ldap_mapping_not_exist An object does not exist Status Codes: - 200 OK – success, the ldap_mapping is deleted.
- 406 Not Acceptable – the request is not acceptable.
- 501 Not Implemented – cluster doesn’t support LDAP mappings yet.
Required permissions: delete_ldap_mapping
Roles¶
Each user in the cluster has a role assigned to it, which defines the permissions the user holds. There are 5 types of roles:
- Db_viewer - Can view bdbs related info.
- Db_member - Can create and modify bdbs, and view bdbs related info.
- Cluster_viewer - Can view cluster and bdbs related info.
- Cluster_member - Can create and modify bdbs, and view bdbs and cluster related info.
- Admin - Can modify all view and modify all elements of the cluster.
Permissions list for each role.¶
| Role name | Permissions |
|---|---|
| none | |
| db_member | view_all_nodes_stats, view_all_nodes_alerts, view_status_of_node_action, start_bdb_export, update_crdb, view_all_bdbs_info, view_all_shard_stats, create_bdb, reset_bdb_current_export_status, view_redis_acl_info, view_bdb_alerts, update_bdb_with_action, update_bdb_alerts, view_cluster_info, view_license, view_all_redis_acls_info, view_endpoint_stats, view_redis_pass, create_crdb, delete_crdb, view_all_roles_info, view_all_bdbs_alerts, flush_crdb, view_proxy_info, view_all_bdb_stats, view_status_of_all_node_actions, view_logged_events, reset_bdb_current_import_status, view_status_of_cluster_action, view_all_proxies_info, view_shard_stats, purge_instance, view_bdb_info, view_node_check, migrate_shard, view_crdb, view_crdb_list, reset_bdb_current_backup_status, view_node_stats, view_all_nodes_info, view_node_alerts, edit_bdb_module, update_bdb, view_cluster_alerts, view_role_info, view_bdb_stats, delete_bdb, view_cluster_modules, start_bdb_import, view_cluster_stats, view_node_info, view_all_nodes_checks |
| admin | create_bdb, create_redis_acl, update_user, view_all_nodes_stats, view_all_nodes_alerts, view_status_of_node_action, view_user_info, view_logged_events, delete_user, delete_cluster_module, view_all_nodes_info, update_crdb, view_all_bdbs_info, cancel_node_action, view_all_shard_stats, config_ldap, update_redis_acl, reset_bdb_current_export_status, create_ldap_mapping, view_redis_acl_info, view_bdb_alerts, update_bdb_with_action, update_bdb_alerts, view_cluster_info, view_license, view_all_redis_acls_info, update_ldap_mapping, view_redis_pass, create_crdb, delete_crdb, view_all_roles_info, start_cluster_action, view_all_bdbs_alerts, flush_crdb, start_node_action, update_node, view_proxy_info, cancel_cluster_action, view_all_bdb_stats, view_all_users_info, update_role, view_status_of_all_node_actions, view_cluster_stats, view_cluster_keys, reset_bdb_current_import_status, view_status_of_cluster_action, view_all_proxies_info, create_new_user, view_shard_stats, start_bdb_import, delete_redis_acl, view_endpoint_stats, view_node_check, migrate_shard, create_role, view_crdb, view_crdb_list, update_cluster, reset_bdb_current_backup_status, view_node_stats, view_ldap_mapping_info, view_all_ldap_mappings_info, update_proxy, add_cluster_module, view_node_alerts, edit_bdb_module, update_bdb, view_cluster_alerts, view_role_info, view_bdb_stats, delete_role, delete_bdb, delete_ldap_mapping, view_all_nodes_checks, view_cluster_modules, purge_instance, install_new_license, start_bdb_export, view_node_info, view_bdb_info, view_ldap_config |
| db_viewer | view_all_nodes_stats, view_all_nodes_alerts, view_status_of_node_action, view_all_bdbs_info, view_all_shard_stats, view_redis_acl_info, view_bdb_alerts, view_cluster_info, view_license, view_all_redis_acls_info, view_all_roles_info, view_all_bdbs_alerts, view_proxy_info, view_all_bdb_stats, view_status_of_all_node_actions, view_status_of_cluster_action, view_all_proxies_info, view_shard_stats, view_bdb_info, view_node_check, view_crdb, view_crdb_list, view_node_stats, view_all_nodes_info, view_node_alerts, view_role_info, view_cluster_alerts, view_bdb_stats, view_endpoint_stats, view_cluster_modules, view_cluster_stats, view_node_info, view_all_nodes_checks |
| cluster_member | view_all_nodes_stats, view_all_nodes_alerts, view_status_of_node_action, view_logged_events, update_crdb, view_all_bdbs_info, view_all_shard_stats, create_bdb, reset_bdb_current_export_status, view_redis_acl_info, view_bdb_alerts, update_bdb_with_action, update_bdb_alerts, view_cluster_info, view_license, view_all_redis_acls_info, view_endpoint_stats, view_redis_pass, create_crdb, delete_crdb, view_all_roles_info, view_all_bdbs_alerts, flush_crdb, view_proxy_info, start_bdb_export, view_all_bdb_stats, view_status_of_all_node_actions, view_cluster_keys, reset_bdb_current_import_status, view_status_of_cluster_action, view_all_proxies_info, view_shard_stats, purge_instance, view_bdb_info, view_node_check, migrate_shard, view_crdb, view_crdb_list, reset_bdb_current_backup_status, view_node_stats, view_all_nodes_info, view_node_alerts, edit_bdb_module, update_bdb, view_cluster_alerts, view_role_info, view_bdb_stats, delete_bdb, view_cluster_modules, start_bdb_import, view_cluster_stats, view_node_info, view_all_nodes_checks |
| cluster_viewer | view_all_nodes_stats, view_all_nodes_alerts, view_status_of_node_action, view_all_bdbs_info, view_all_shard_stats, view_redis_acl_info, view_bdb_alerts, view_cluster_info, view_license, view_all_redis_acls_info, view_all_roles_info, view_all_bdbs_alerts, view_proxy_info, view_all_bdb_stats, view_status_of_all_node_actions, view_logged_events, view_status_of_cluster_action, view_all_proxies_info, view_shard_stats, view_bdb_info, view_node_check, view_crdb, view_crdb_list, view_node_stats, view_all_nodes_info, view_node_alerts, view_role_info, view_cluster_alerts, view_bdb_stats, view_endpoint_stats, view_cluster_modules, view_cluster_stats, view_node_info, view_all_nodes_checks |
Roles list per permission¶
| Permission name | Roles |
|---|---|
| add_cluster_module | admin |
| cancel_cluster_action | admin |
| cancel_node_action | admin |
| config_ldap | admin |
| create_bdb | admin, cluster_member, db_member |
| create_crdb | admin, cluster_member, db_member |
| create_ldap_mapping | admin |
| create_new_user | admin |
| create_redis_acl | admin |
| create_role | admin |
| delete_bdb | admin, cluster_member, db_member |
| delete_cluster_module | admin |
| delete_crdb | admin, cluster_member, db_member |
| delete_ldap_mapping | admin |
| delete_redis_acl | admin |
| delete_role | admin |
| delete_user | admin |
| edit_bdb_module | admin, cluster_member, db_member |
| flush_crdb | admin, cluster_member, db_member |
| install_new_license | admin |
| migrate_shard | admin, cluster_member, db_member |
| purge_instance | admin, cluster_member, db_member |
| reset_bdb_current_backup_status | admin, cluster_member, db_member |
| reset_bdb_current_export_status | admin, cluster_member, db_member |
| reset_bdb_current_import_status | admin, cluster_member, db_member |
| start_bdb_export | admin, cluster_member, db_member |
| start_bdb_import | admin, cluster_member, db_member |
| start_cluster_action | admin |
| start_node_action | admin |
| update_bdb | admin, cluster_member, db_member |
| update_bdb_alerts | admin, cluster_member, db_member |
| update_bdb_with_action | admin, cluster_member, db_member |
| update_cluster | admin |
| update_crdb | admin, cluster_member, db_member |
| update_ldap_mapping | admin |
| update_node | admin |
| update_proxy | admin |
| update_redis_acl | admin |
| update_role | admin |
| update_user | admin |
| view_all_bdb_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_bdbs_alerts | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_bdbs_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_ldap_mappings_info | admin |
| view_all_nodes_alerts | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_nodes_checks | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_nodes_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_nodes_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_proxies_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_redis_acls_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_roles_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_shard_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_all_users_info | admin |
| view_bdb_alerts | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_bdb_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_bdb_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_cluster_alerts | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_cluster_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_cluster_keys | admin, cluster_member |
| view_cluster_modules | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_cluster_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_crdb | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_crdb_list | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_endpoint_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_ldap_config | admin |
| view_ldap_mapping_info | admin |
| view_license | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_logged_events | admin, cluster_member, cluster_viewer, db_member |
| view_node_alerts | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_node_check | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_node_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_node_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_proxy_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_redis_acl_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_redis_pass | admin, cluster_member, db_member |
| view_role_info | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_shard_stats | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_status_of_all_node_actions | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_status_of_cluster_action | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_status_of_node_action | admin, cluster_member, cluster_viewer, db_member, db_viewer |
| view_user_info | admin |