{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "g_nWetWWd_ns"
},
"source": [
"##### Copyright 2019 The TensorFlow Authors."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "2pHVBk_seED1"
},
"outputs": [],
"source": [
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "M7vSdG6sAIQn"
},
"source": [
"# TensorFlow Lite による芸術的スタイル転移"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fwc5GKHBASdc"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "31O0iaROAw8z"
},
"source": [
"最近開発されたディープラーニングの中で最も面白い開発の 1 つとして、[芸術的スタイル転移](https://arxiv.org/abs/1508.06576)または [パスティーシュ(模倣)](https://en.wikipedia.org/wiki/Pastiche)として知られる能力があります。これは芸術的スタイルを表現する画像とコンテンツを表現する画像から成る 2 つの入力画像に基づいて新しい画像を創造するものです。\n",
"\n",
"\n",
"\n",
"この手法を使用すると、様々なスタイルの美しく新しい作品を生成することができます。\n",
"\n",
"\n",
"\n",
"TensorFlow Lite を初めて使用する場合、Android を使用する場合は、以下のサンプルアプリをご覧ください。\n",
"\n",
"Android の例 iOS の例\n",
"\n",
"Android や iOS 以外のプラットフォームを使用する場合、または、すでに TensorFlow Lite API に精通している場合は、このチュートリアルに従い、事前トレーニング済みの TensorFlow Lite モデル を使用して、任意のコンテンツ画像とスタイル画像のペアにスタイル転移を適用する方法を学ぶことができます。モデルを使用して、独自のモバイルアプリにスタイル転移を追加することができます。\n",
"\n",
"モデルは [GitHub](https://github.com/tensorflow/magenta/tree/master/magenta/models/arbitrary_image_stylization#train-a-model-on-a-large-dataset-with-data-augmentation-to-run-on-mobile) でオープンソース化されています。異なるパラメータを使用してモデルの再トレーニング(例えば、コンテンツレイヤーの重みを増やしてよりコンテンツ画像に近い出力画像にするなど)が可能です。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ak0S4gkOCSxs"
},
"source": [
"## モデルアーキテクチャの理解"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "oee6G_bBCgAM"
},
"source": [
"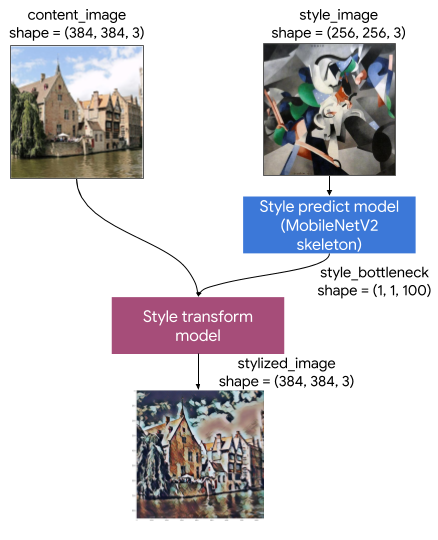\n",
"\n",
"この芸術的スタイル転移モデルは、2 つのサブモデルで構成されています。\n",
"\n",
"1. **スタイル予測モデル**: 入力スタイル画像を 100 次元スタイルのボトルネックベクトルに変換する MobilenetV2 ベースのニューラルネットワーク。\n",
"2. **スタイル変換モデル**: コンテンツ画像にスタイルのボトルネックベクトルを適用し、スタイル化された画像を生成するニューラルネットワーク。\n",
"\n",
"アプリが特定のスタイル画像セットのみをサポートする必要がある場合は、それらのスタイルのボトルネックベクトルを事前に計算して、そのスタイル予測モデルをアプリのバイナリから除外します。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "a7ZETsRVNMo7"
},
"source": [
"## セットアップ"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3n8oObKZN4c8"
},
"source": [
"依存関係をインポートします。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "xz62Lb1oNm97"
},
"outputs": [],
"source": [
"import tensorflow as tf\n",
"print(tf.__version__)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1Ua5FpcJNrIj"
},
"outputs": [],
"source": [
"import IPython.display as display\n",
"\n",
"import matplotlib.pyplot as plt\n",
"import matplotlib as mpl\n",
"mpl.rcParams['figure.figsize'] = (12,12)\n",
"mpl.rcParams['axes.grid'] = False\n",
"\n",
"import numpy as np\n",
"import time\n",
"import functools"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1b988wrrQnVF"
},
"source": [
"コンテンツ画像とスタイル画像、および事前トレーニング済みの TensorFlow Lite モデルをダウンロードします。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "16g57cIMQnen"
},
"outputs": [],
"source": [
"content_path = tf.keras.utils.get_file('belfry.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/belfry-2611573_1280.jpg')\n",
"style_path = tf.keras.utils.get_file('style23.jpg','https://storage.googleapis.com/khanhlvg-public.appspot.com/arbitrary-style-transfer/style23.jpg')\n",
"\n",
"style_predict_path = tf.keras.utils.get_file('style_predict.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/prediction/1?lite-format=tflite')\n",
"style_transform_path = tf.keras.utils.get_file('style_transform.tflite', 'https://tfhub.dev/google/lite-model/magenta/arbitrary-image-stylization-v1-256/int8/transfer/1?lite-format=tflite')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MQZXL7kON-gM"
},
"source": [
"## 入力を前処理する\n",
"\n",
"- コンテンツ画像とスタイル画像は RGB 画像である必要があります。ピクセル値は [0..1] 間の float32 の数値です。\n",
"- スタイル画像のサイズは (1, 256, 256, 3) である必要があります。画像を中央でクロップしてサイズを変更します。\n",
"- コンテンツ画像は (1, 384, 384, 3) である必要があります。画像を中央でクロップしてサイズを変更します。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Cg0Vi-rXRUFl"
},
"outputs": [],
"source": [
"# Function to load an image from a file, and add a batch dimension.\n",
"def load_img(path_to_img):\n",
" img = tf.io.read_file(path_to_img)\n",
" img = tf.io.decode_image(img, channels=3)\n",
" img = tf.image.convert_image_dtype(img, tf.float32)\n",
" img = img[tf.newaxis, :]\n",
"\n",
" return img\n",
"\n",
"# Function to pre-process by resizing an central cropping it.\n",
"def preprocess_image(image, target_dim):\n",
" # Resize the image so that the shorter dimension becomes 256px.\n",
" shape = tf.cast(tf.shape(image)[1:-1], tf.float32)\n",
" short_dim = min(shape)\n",
" scale = target_dim / short_dim\n",
" new_shape = tf.cast(shape * scale, tf.int32)\n",
" image = tf.image.resize(image, new_shape)\n",
"\n",
" # Central crop the image.\n",
" image = tf.image.resize_with_crop_or_pad(image, target_dim, target_dim)\n",
"\n",
" return image\n",
"\n",
"# Load the input images.\n",
"content_image = load_img(content_path)\n",
"style_image = load_img(style_path)\n",
"\n",
"# Preprocess the input images.\n",
"preprocessed_content_image = preprocess_image(content_image, 384)\n",
"preprocessed_style_image = preprocess_image(style_image, 256)\n",
"\n",
"print('Style Image Shape:', preprocessed_style_image.shape)\n",
"print('Content Image Shape:', preprocessed_content_image.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xE4Yt8nArTeR"
},
"source": [
"## 入力を可視化する"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ncPA4esJRcEu"
},
"outputs": [],
"source": [
"def imshow(image, title=None):\n",
" if len(image.shape) > 3:\n",
" image = tf.squeeze(image, axis=0)\n",
"\n",
" plt.imshow(image)\n",
" if title:\n",
" plt.title(title)\n",
"\n",
"plt.subplot(1, 2, 1)\n",
"imshow(preprocessed_content_image, 'Content Image')\n",
"\n",
"plt.subplot(1, 2, 2)\n",
"imshow(preprocessed_style_image, 'Style Image')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "CJ7R-CHbjC3s"
},
"source": [
"## TensorFlow Lite でスタイル転移を実行する"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "euu00ldHjKwD"
},
"source": [
"### スタイルを予測する"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "o3zd9cTFRiS_"
},
"outputs": [],
"source": [
"# Function to run style prediction on preprocessed style image.\n",
"def run_style_predict(preprocessed_style_image):\n",
" # Load the model.\n",
" interpreter = tf.lite.Interpreter(model_path=style_predict_path)\n",
"\n",
" # Set model input.\n",
" interpreter.allocate_tensors()\n",
" input_details = interpreter.get_input_details()\n",
" interpreter.set_tensor(input_details[0][\"index\"], preprocessed_style_image)\n",
"\n",
" # Calculate style bottleneck.\n",
" interpreter.invoke()\n",
" style_bottleneck = interpreter.tensor(\n",
" interpreter.get_output_details()[0][\"index\"]\n",
" )()\n",
"\n",
" return style_bottleneck\n",
"\n",
"# Calculate style bottleneck for the preprocessed style image.\n",
"style_bottleneck = run_style_predict(preprocessed_style_image)\n",
"print('Style Bottleneck Shape:', style_bottleneck.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "00t8S2PekIyW"
},
"source": [
"### スタイルを変換する"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "cZp5bCj8SX1w"
},
"outputs": [],
"source": [
"# Run style transform on preprocessed style image\n",
"def run_style_transform(style_bottleneck, preprocessed_content_image):\n",
" # Load the model.\n",
" interpreter = tf.lite.Interpreter(model_path=style_transform_path)\n",
"\n",
" # Set model input.\n",
" input_details = interpreter.get_input_details()\n",
" interpreter.allocate_tensors()\n",
"\n",
" # Set model inputs.\n",
" interpreter.set_tensor(input_details[0][\"index\"], preprocessed_content_image)\n",
" interpreter.set_tensor(input_details[1][\"index\"], style_bottleneck)\n",
" interpreter.invoke()\n",
"\n",
" # Transform content image.\n",
" stylized_image = interpreter.tensor(\n",
" interpreter.get_output_details()[0][\"index\"]\n",
" )()\n",
"\n",
" return stylized_image\n",
"\n",
"# Stylize the content image using the style bottleneck.\n",
"stylized_image = run_style_transform(style_bottleneck, preprocessed_content_image)\n",
"\n",
"# Visualize the output.\n",
"imshow(stylized_image, 'Stylized Image')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "vv_71Td-QtrW"
},
"source": [
"### スタイルをブレンドする\n",
"\n",
"コンテンツ画像のスタイルをスタイル化された出力にブレンドさせることができます。こうすると、出力がよりコンテンツ画像のように見えるようになります。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "eJcAURXQQtJ7"
},
"outputs": [],
"source": [
"# Calculate style bottleneck of the content image.\n",
"style_bottleneck_content = run_style_predict(\n",
" preprocess_image(content_image, 256)\n",
" )"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4S3yg2MgkmRD"
},
"outputs": [],
"source": [
"# Define content blending ratio between [0..1].\n",
"# 0.0: 0% style extracts from content image.\n",
"# 1.0: 100% style extracted from content image.\n",
"content_blending_ratio = 0.5 #@param {type:\"slider\", min:0, max:1, step:0.01}\n",
"\n",
"# Blend the style bottleneck of style image and content image\n",
"style_bottleneck_blended = content_blending_ratio * style_bottleneck_content \\\n",
" + (1 - content_blending_ratio) * style_bottleneck\n",
"\n",
"# Stylize the content image using the style bottleneck.\n",
"stylized_image_blended = run_style_transform(style_bottleneck_blended,\n",
" preprocessed_content_image)\n",
"\n",
"# Visualize the output.\n",
"imshow(stylized_image_blended, 'Blended Stylized Image')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "9k9jGIep8p1c"
},
"source": [
"## パフォーマンスベンチマーク\n",
"\n",
"パフォーマンスベンチマークの数値は、[ここで説明する](https://www.tensorflow.org/lite/performance/benchmarks)ツールで生成されます。\n",
"\n",
"\n",
"\n",
"\n",
"| モデル名 | モデルサイズ | デバイス | NNAPI | CPU | GPU | \n",
"
\n",
" | スタイル予測モデル (int8) | \n",
"2.8 Mb | \n",
"Pixel 3 (Android 10) | 142ms | \n",
"14ms* | \n",
" | \n",
"
\n",
"\n",
"| Pixel 4 (Android 10) | 5.2ms | \n",
"6.7ms* | \n",
" | \n",
"
\n",
"\n",
"| iPhone XS (iOS 12.4.1) | | \n",
"10.7ms** | \n",
" | \n",
"
\n",
" | スタイル変換モデル (int8) | \n",
"0.2 Mb | \n",
"Pixel 3 (Android 10) | | \n",
"540ms* | \n",
" | \n",
"
\n",
"\n",
"| Pixel 4 (Android 10) | | \n",
"405ms* | \n",
" | \n",
"
\n",
"\n",
"| iPhone XS (iOS 12.4.1) | | \n",
"251ms** | \n",
" | \n",
"
\n",
" | スタイル予測モデル (float16) | \n",
"4.7 Mb | \n",
"Pixel 3 (Android 10) | 86ms | \n",
"28ms* | \n",
"9.1ms | \n",
"
\n",
"\n",
"| Pixel 4 (Android 10) | \n",
"32ms | \n",
"12ms* | \n",
"10ms | \n",
"
\n",
" | スタイル予測モデル (float16) | \n",
"0.4 Mb | \n",
"Pixel 3 (Android 10) | 1095ms | \n",
"545ms* | \n",
"42ms | \n",
"
\n",
"\n",
"| Pixel 4 (Android 10) | \n",
"603ms | \n",
"377ms* | \n",
"42ms | \n",
"
\n",
"
\n",
"\n",
"** 4 つのスレッドを使用。*\n",
"** 4 つのスレッドを使用。
** 最高のパフォーマンス結果を得るために、iPhone では 2 つのスレッドを使用。*\n"
]
}
],
"metadata": {
"colab": {
"collapsed_sections": [],
"name": "overview.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
 GitHub でソースを表示
GitHub でソースを表示