{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "K2s1A9eLRPEj"
},
"source": [
"##### Copyright 2018 The TensorFlow Authors.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "VRLVEKiTEn04"
},
"outputs": [],
"source": [
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# https://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License."
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "EFwSaNB8jF7s"
},
"source": [
"<style> td { text-align: center; } th { text-align: center; } </style>"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Cffg2i257iMS"
},
"source": [
"# 使用视觉注意力生成图像描述\n",
"\n",
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "QASbY_HGo4Lq"
},
"source": [
"给定一个类似以下示例的图像,我们的目标是生成一个类似“一名正在冲浪的冲浪者”的描述。\n",
"\n",
"\n",
"\n",
"  | \n",
"
\n",
"\n",
" | 一个冲浪的人,来自 Wikimedia | \n",
"
\n",
"
\n",
"\n",
"此处使用的模型架构的灵感来自 [Show, Attend and Tell: Neural Image Caption Generation with Visual Attention](https://arxiv.org/abs/1502.03044),但已更新为使用 2 层 Transformer 解码器。要充分利用本教程,您应该对[文本生成](https://tensorflow.google.cn/text/tutorials/text_generation)、[seq2seq 模型和注意力](https://tensorflow.google.cn/text/tutorials/nmt_with_attention)或 [Transformer](https://tensorflow.google.cn/text/tutorials/transformer) 有一定的经验。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6HbD8n0w7d3F"
},
"source": [
"本教程中构建的模型架构如下所示。从图像中提取特征,并传递到 Transformer 解码器的交叉注意力层。\n",
"\n",
"\n",
"\n",
" | 模型架构 | \n",
"
\n",
"\n",
"  | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1IxifZKT6vXQ"
},
"source": [
"Transformer 解码器主要由注意力层构建。它使用自注意力处理正在生成的序列,并使用交叉注意力处理图像。\n",
"\n",
"通过检查交叉注意力层的注意力权重,您将看到模型在生成单词时正在查看图像的哪些部分。\n",
"\n",
"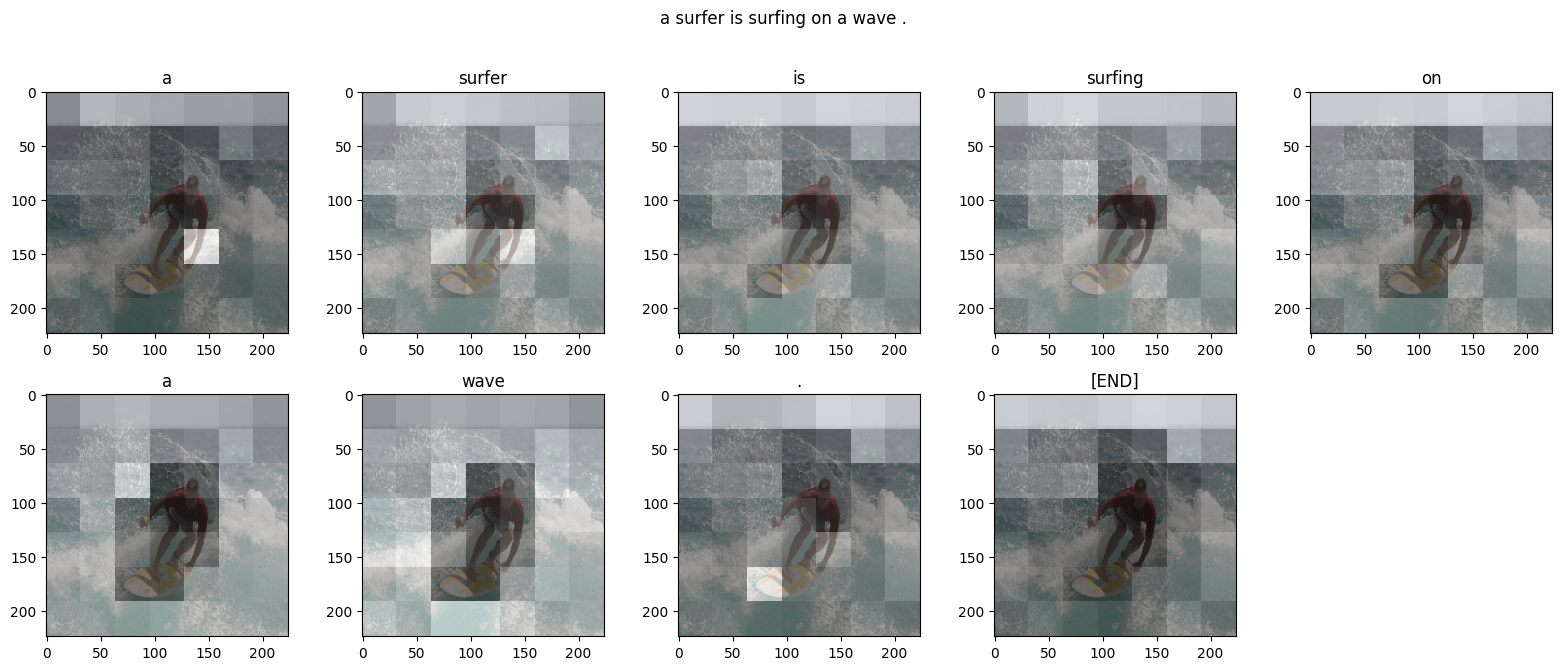"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "87us2sLVdwME"
},
"source": [
"此笔记本是一个端到端示例。当您运行此笔记本时,它会下载数据集、提取和缓存图像特征,并训练解码器模型。随后,它会使用该模型在新的图像上生成描述。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5bwwk4uxRz6A"
},
"source": [
"## 安装"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "gc06pTaBbl72"
},
"outputs": [],
"source": [
"!apt install --allow-change-held-packages libcudnn8=8.1.0.77-1+cuda11.2"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2R1hQGtZEi8Y"
},
"outputs": [],
"source": [
"!pip uninstall -y tensorflow estimator keras"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "5Xbt8BkPv8Ou"
},
"outputs": [],
"source": [
"!pip install -U tensorflow_text tensorflow tensorflow_datasets"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "7TGZmOuqMia9"
},
"outputs": [],
"source": [
"!pip install einops"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nQ6q39Vd-y-7"
},
"source": [
"本教程使用大量导入,主要用于加载数据集。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"cellView": "form",
"id": "U8l4RJ0XRPEm"
},
"outputs": [],
"source": [
"#@title\n",
"import concurrent.futures\n",
"import collections\n",
"import dataclasses\n",
"import hashlib\n",
"import itertools\n",
"import json\n",
"import math\n",
"import os\n",
"import pathlib\n",
"import random\n",
"import re\n",
"import string\n",
"import time\n",
"import urllib.request\n",
"\n",
"import einops\n",
"import matplotlib.pyplot as plt\n",
"import numpy as np\n",
"import pandas as pd\n",
"from PIL import Image\n",
"import requests\n",
"import tqdm\n",
"\n",
"import tensorflow as tf\n",
"import tensorflow_hub as hub\n",
"import tensorflow_text as text\n",
"import tensorflow_datasets as tfds"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Kl9qGnjWrv80"
},
"source": [
"## [可选] 数据处理\n",
"\n",
"本部分下载描述数据集并为训练做准备。它将输入文本词例化,并缓存通过预训练的特征提取程序模型运行所有图像的结果。理解本部分中的所有内容并不是非常重要。\n",
"\n",
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "q5e_SigQFiWf"
},
"source": [
"### 选择数据集\n",
"\n",
"本教程旨在提供数据集的选择。[Flickr8k](https://www.ijcai.org/Proceedings/15/Papers/593.pdf) 或 [Conceptual Captions](https://ai.google.com/research/ConceptualCaptions/) 数据集的一小部分。这两个数据集需要从头开始下载和转换,但是将教程转换为使用 [TensorFlow 数据集](https://tensorflow.google.cn/datasets)中可用的描述数据集([Coco Captions](https://tensorflow.google.cn/datasets/catalog/coco_captions) 和完整的 [Conceptual Captions](https://tensorflow.google.cn/datasets/community_catalog/huggingface/conceptual_captions))并不难。\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "wqGXX9Dc5c0v"
},
"source": [
"#### Flickr8k"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kaNy_l7tGuAZ"
},
"outputs": [],
"source": [
"def flickr8k(path='flickr8k'):\n",
" path = pathlib.Path(path)\n",
"\n",
" if len(list(path.rglob('*'))) < 16197:\n",
" tf.keras.utils.get_file(\n",
" origin='https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_Dataset.zip',\n",
" cache_dir='.',\n",
" cache_subdir=path,\n",
" extract=True)\n",
" tf.keras.utils.get_file(\n",
" origin='https://github.com/jbrownlee/Datasets/releases/download/Flickr8k/Flickr8k_text.zip',\n",
" cache_dir='.',\n",
" cache_subdir=path,\n",
" extract=True)\n",
" \n",
" captions = (path/\"Flickr8k.token.txt\").read_text().splitlines()\n",
" captions = (line.split('\\t') for line in captions)\n",
" captions = ((fname.split('#')[0], caption) for (fname, caption) in captions)\n",
"\n",
" cap_dict = collections.defaultdict(list)\n",
" for fname, cap in captions:\n",
" cap_dict[fname].append(cap)\n",
"\n",
" train_files = (path/'Flickr_8k.trainImages.txt').read_text().splitlines()\n",
" train_captions = [(str(path/'Flicker8k_Dataset'/fname), cap_dict[fname]) for fname in train_files]\n",
"\n",
" test_files = (path/'Flickr_8k.testImages.txt').read_text().splitlines()\n",
" test_captions = [(str(path/'Flicker8k_Dataset'/fname), cap_dict[fname]) for fname in test_files]\n",
"\n",
" train_ds = tf.data.experimental.from_list(train_captions)\n",
" test_ds = tf.data.experimental.from_list(test_captions)\n",
"\n",
" return train_ds, test_ds"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zQICBAF4FmSL"
},
"source": [
"#### Conceptual Captions"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "vQwnxXZXRl12"
},
"outputs": [],
"source": [
"def conceptual_captions(*, data_dir=\"conceptual_captions\", num_train, num_val):\n",
" def iter_index(index_path):\n",
" with open(index_path) as f:\n",
" for line in f:\n",
" caption, url = line.strip().split('\\t')\n",
" yield caption, url\n",
"\n",
" def download_image_urls(data_dir, urls):\n",
" ex = concurrent.futures.ThreadPoolExecutor(max_workers=100)\n",
" def save_image(url):\n",
" hash = hashlib.sha1(url.encode())\n",
" # Name the files after the hash of the URL.\n",
" file_path = data_dir/f'{hash.hexdigest()}.jpeg'\n",
" if file_path.exists():\n",
" # Only download each file once.\n",
" return file_path\n",
"\n",
" try:\n",
" result = requests.get(url, timeout=5)\n",
" except Exception:\n",
" file_path = None\n",
" else:\n",
" file_path.write_bytes(result.content)\n",
" return file_path\n",
" \n",
" result = []\n",
" out_paths = ex.map(save_image, urls)\n",
" for file_path in tqdm.tqdm(out_paths, total=len(urls)):\n",
" result.append(file_path)\n",
"\n",
" return result\n",
"\n",
" def ds_from_index_file(index_path, data_dir, count):\n",
" data_dir.mkdir(exist_ok=True)\n",
" index = list(itertools.islice(iter_index(index_path), count))\n",
" captions = [caption for caption, url in index]\n",
" urls = [url for caption, url in index]\n",
"\n",
" paths = download_image_urls(data_dir, urls)\n",
"\n",
" new_captions = []\n",
" new_paths = []\n",
" for cap, path in zip(captions, paths):\n",
" if path is None:\n",
" # Download failed, so skip this pair.\n",
" continue\n",
" new_captions.append(cap)\n",
" new_paths.append(path)\n",
" \n",
" new_paths = [str(p) for p in new_paths]\n",
"\n",
" ds = tf.data.Dataset.from_tensor_slices((new_paths, new_captions))\n",
" ds = ds.map(lambda path,cap: (path, cap[tf.newaxis])) # 1 caption per image\n",
" return ds\n",
"\n",
" data_dir = pathlib.Path(data_dir)\n",
" train_index_path = tf.keras.utils.get_file(\n",
" origin='https://storage.googleapis.com/gcc-data/Train/GCC-training.tsv',\n",
" cache_subdir=data_dir,\n",
" cache_dir='.')\n",
" \n",
" val_index_path = tf.keras.utils.get_file(\n",
" origin='https://storage.googleapis.com/gcc-data/Validation/GCC-1.1.0-Validation.tsv',\n",
" cache_subdir=data_dir,\n",
" cache_dir='.')\n",
" \n",
" train_raw = ds_from_index_file(train_index_path, data_dir=data_dir/'train', count=num_train)\n",
" test_raw = ds_from_index_file(val_index_path, data_dir=data_dir/'val', count=num_val)\n",
"\n",
" return train_raw, test_raw"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "rBAagBw5p-TM"
},
"source": [
"#### 下载数据集"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WFtTZaobquNr"
},
"source": [
"Flickr8k 是一个不错的选择,因为它每个图像包含 5 个描述,下载更少,数据更多。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "EJySPbzJ4Wxw"
},
"outputs": [],
"source": [
"choose = 'flickr8k'\n",
"\n",
"if choose == 'flickr8k':\n",
" train_raw, test_raw = flickr8k()\n",
"else:\n",
" train_raw, test_raw = conceptual_captions(num_train=10000, num_val=5000)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-UAc275FHxm8"
},
"source": [
"上面两个数据集的加载程序都返回包含 `(image_path, captions)` 对的 `tf.data.Dataset`。Flickr8k 数据集每个图像包含 5 个描述,而 Conceptual Captions 有 1 个:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "sAQSps5F8RQI"
},
"outputs": [],
"source": [
"train_raw.element_spec"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "xIa0ZaP4tBez"
},
"outputs": [],
"source": [
"for ex_path, ex_captions in train_raw.take(1):\n",
" print(ex_path)\n",
" print(ex_captions)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8cSW4u-ORPFQ"
},
"source": [
"### 图像特征提取程序\n",
"\n",
"您将使用图像模型(在 imagenet 上预训练)从每个图像中提取特征。该模型被训练为图像分类器,但设置 `include_top=False` 会返回没有最终分类层的模型,因此您可以使用特征映射的最后一层:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "IlUckK8Zfikv"
},
"outputs": [],
"source": [
"IMAGE_SHAPE=(224, 224, 3)\n",
"mobilenet = tf.keras.applications.MobileNetV3Small(\n",
" input_shape=IMAGE_SHAPE,\n",
" include_top=False,\n",
" include_preprocessing=True)\n",
"mobilenet.trainable=False"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Dojkiou9gL3R"
},
"source": [
"下面是一个加载图像并为模型调整大小的函数:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "zXR0217aRPFR"
},
"outputs": [],
"source": [
"def load_image(image_path):\n",
" img = tf.io.read_file(image_path)\n",
" img = tf.io.decode_jpeg(img, channels=3)\n",
" img = tf.image.resize(img, IMAGE_SHAPE[:-1])\n",
" return img"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-JyQ7zS6gzZh"
},
"source": [
"该模型为输入批次中的每个图像返回一个特征映射:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "sY86n2i6wJNm"
},
"outputs": [],
"source": [
"test_img_batch = load_image(ex_path)[tf.newaxis, :]\n",
"\n",
"print(test_img_batch.shape)\n",
"print(mobilenet(test_img_batch).shape)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "nyqH3zFwRPFi"
},
"source": [
"### 设置文本分词器/向量化程序\n",
"\n",
"使用 [TextVectorization](https://tensorflow.google.cn/api_docs/python/tf/keras/layers/TextVectorization) 层将文本描述转换为整数序列,步骤如下:\n",
"\n",
"- 使用 [adapt](https://tensorflow.google.cn/api_docs/python/tf/keras/layers/TextVectorization#adapt) 迭代所有描述,将描述拆分为字词,并计算最热门字词的词汇表。\n",
"- 通过将每个字词映射到它在词汇表中的索引对所有描述进行词例化。所有输出序列将被填充到长度 50。\n",
"- 创建字词到索引和索引到字词的映射以显示结果。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "NroZIzB90hD3"
},
"outputs": [],
"source": [
"def standardize(s):\n",
" s = tf.strings.lower(s)\n",
" s = tf.strings.regex_replace(s, f'[{re.escape(string.punctuation)}]', '')\n",
" s = tf.strings.join(['[START]', s, '[END]'], separator=' ')\n",
" return s"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "n9SQOXFsyS36"
},
"outputs": [],
"source": [
"# Use the top 5000 words for a vocabulary.\n",
"vocabulary_size = 5000\n",
"tokenizer = tf.keras.layers.TextVectorization(\n",
" max_tokens=vocabulary_size,\n",
" standardize=standardize,\n",
" ragged=True)\n",
"# Learn the vocabulary from the caption data."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "oJGE34aiRPFo"
},
"outputs": [],
"source": [
"tokenizer.adapt(train_raw.map(lambda fp,txt: txt).unbatch().batch(1024))"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "oRahTDtWhJIf"
},
"outputs": [],
"source": [
"tokenizer.get_vocabulary()[:10]"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "-2mGxD33JCxN"
},
"outputs": [],
"source": [
"t = tokenizer([['a cat in a hat'], ['a robot dog']])\n",
"t"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "8Q44tNQVRPFt"
},
"outputs": [],
"source": [
"# Create mappings for words to indices and indices to words.\n",
"word_to_index = tf.keras.layers.StringLookup(\n",
" mask_token=\"\",\n",
" vocabulary=tokenizer.get_vocabulary())\n",
"index_to_word = tf.keras.layers.StringLookup(\n",
" mask_token=\"\",\n",
" vocabulary=tokenizer.get_vocabulary(),\n",
" invert=True)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "qo-cfCX3LnHs"
},
"outputs": [],
"source": [
"w = index_to_word(t)\n",
"w.to_list()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "rrUUfGc65vAT"
},
"outputs": [],
"source": [
"tf.strings.reduce_join(w, separator=' ', axis=-1).numpy()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "uEWM9xrYcg45"
},
"source": [
"### 准备数据集"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6aX0Z_98S2tN"
},
"source": [
"`train_raw` 和 `test_raw` 数据集包含一对多 `(image, captions)` 对。\n",
"\n",
"此函数将复制图像,因此描述中有 1:1 的图像:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3_Lqwl9NiGT0"
},
"outputs": [],
"source": [
"def match_shapes(images, captions):\n",
" caption_shape = einops.parse_shape(captions, 'b c')\n",
" captions = einops.rearrange(captions, 'b c -> (b c)')\n",
" images = einops.repeat(\n",
" images, 'b ... -> (b c) ...',\n",
" c = caption_shape['c'])\n",
" return images, captions"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CZGUsuGzUfzt"
},
"outputs": [],
"source": [
"for ex_paths, ex_captions in train_raw.batch(32).take(1):\n",
" break\n",
"\n",
"print('image paths:', ex_paths.shape)\n",
"print('captions:', ex_captions.shape)\n",
"print()\n",
"\n",
"ex_paths, ex_captions = match_shapes(images=ex_paths, captions=ex_captions)\n",
"\n",
"print('image_paths:', ex_paths.shape)\n",
"print('captions:', ex_captions.shape)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8ENR_-swVhnm"
},
"source": [
"为了与 keras 训练兼容,数据集应包含 `(inputs, labels)` 对。对于文本生成,词例既是输入又是标签,且移动了一步。此函数会将 `(images, texts)` 对转换为 `((images, input_tokens), label_tokens)` 对:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2DsgQ_hZT4C2"
},
"outputs": [],
"source": [
"def prepare_txt(imgs, txts):\n",
" tokens = tokenizer(txts)\n",
"\n",
" input_tokens = tokens[..., :-1]\n",
" label_tokens = tokens[..., 1:]\n",
" return (imgs, input_tokens), label_tokens"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DA1x2j0JXX-N"
},
"source": [
"此函数会将运算添加到数据集。步骤如下:\n",
"\n",
"1. 加载图像(忽略加载失败的图像)。\n",
"2. 复制图像以匹配描述的数量。\n",
"3. 对 `image, caption` 对执行重排和重新批处理。\n",
"4. 将文本词例化,移动词例并添加 `label_tokens`。\n",
"5. 将文本从 `RaggedTensor` 表示转换为填充的密集 `Tensor` 表示。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "4_Pt9zldjQ0q"
},
"outputs": [],
"source": [
"def prepare_dataset(ds, tokenizer, batch_size=32, shuffle_buffer=1000):\n",
" # Load the images and make batches.\n",
" ds = (ds\n",
" .shuffle(10000)\n",
" .map(lambda path, caption: (load_image(path), caption))\n",
" .apply(tf.data.experimental.ignore_errors())\n",
" .batch(batch_size))\n",
"\n",
" def to_tensor(inputs, labels):\n",
" (images, in_tok), out_tok = inputs, labels\n",
" return (images, in_tok.to_tensor()), out_tok.to_tensor()\n",
"\n",
" return (ds\n",
" .map(match_shapes, tf.data.AUTOTUNE)\n",
" .unbatch()\n",
" .shuffle(shuffle_buffer)\n",
" .batch(batch_size)\n",
" .map(prepare_txt, tf.data.AUTOTUNE)\n",
" .map(to_tensor, tf.data.AUTOTUNE)\n",
" )"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "LrQ85t1GNfpQ"
},
"source": [
"您可以在模型中安装特征提取程序并在数据集上进行训练,如下所示:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1KlhOG5cjQ0r"
},
"outputs": [],
"source": [
"train_ds = prepare_dataset(train_raw, tokenizer)\n",
"train_ds.element_spec"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "d7Zy9F3zX7i2"
},
"outputs": [],
"source": [
"test_ds = prepare_dataset(test_raw, tokenizer)\n",
"test_ds.element_spec"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XZyKygJ8S8zW"
},
"source": [
"### [可选] 缓存图像特征"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "eHKhSKhti6NS"
},
"source": [
"由于图像特征提取程序没有更改,并且本教程没有使用图像增强,可以缓存图像特征。文本词例化也是如此。在训练和验证期间,每个周期都可以重新获得设置缓存所需的时间。下面的代码定义了两个函数 (`save_dataset` 和 `load_dataset`): "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9N1MX5ym6xm5"
},
"outputs": [],
"source": [
"def save_dataset(ds, save_path, image_model, tokenizer, shards=10, batch_size=32):\n",
" # Load the images and make batches.\n",
" ds = (ds\n",
" .map(lambda path, caption: (load_image(path), caption))\n",
" .apply(tf.data.experimental.ignore_errors())\n",
" .batch(batch_size))\n",
"\n",
" # Run the feature extractor on each batch\n",
" # Don't do this in a .map, because tf.data runs on the CPU. \n",
" def gen():\n",
" for (images, captions) in tqdm.tqdm(ds): \n",
" feature_maps = image_model(images)\n",
"\n",
" feature_maps, captions = match_shapes(feature_maps, captions)\n",
" yield feature_maps, captions\n",
"\n",
" # Wrap the generator in a new tf.data.Dataset.\n",
" new_ds = tf.data.Dataset.from_generator(\n",
" gen,\n",
" output_signature=(\n",
" tf.TensorSpec(shape=image_model.output_shape),\n",
" tf.TensorSpec(shape=(None,), dtype=tf.string)))\n",
"\n",
" # Apply the tokenization \n",
" new_ds = (new_ds\n",
" .map(prepare_txt, tf.data.AUTOTUNE)\n",
" .unbatch()\n",
" .shuffle(1000))\n",
"\n",
" # Save the dataset into shard files.\n",
" def shard_func(i, item):\n",
" return i % shards\n",
" new_ds.enumerate().save(save_path, shard_func=shard_func)\n",
"\n",
"def load_dataset(save_path, batch_size=32, shuffle=1000, cycle_length=2):\n",
" def custom_reader_func(datasets):\n",
" datasets = datasets.shuffle(1000)\n",
" return datasets.interleave(lambda x: x, cycle_length=cycle_length)\n",
" \n",
" ds = tf.data.Dataset.load(save_path, reader_func=custom_reader_func)\n",
"\n",
" def drop_index(i, x):\n",
" return x\n",
"\n",
" ds = (ds\n",
" .map(drop_index, tf.data.AUTOTUNE)\n",
" .shuffle(shuffle)\n",
" .padded_batch(batch_size)\n",
" .prefetch(tf.data.AUTOTUNE))\n",
" return ds"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "tNdzrenxB3Yy"
},
"outputs": [],
"source": [
"save_dataset(train_raw, 'train_cache', mobilenet, tokenizer)\n",
"save_dataset(test_raw, 'test_cache', mobilenet, tokenizer)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "798DtfH51UI8"
},
"source": [
" \n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "GI265LiDslr2"
},
"source": [
"## 准备好训练的数据\n",
"\n",
"在这些预处理步骤之后,下面是数据集:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Pwic2YCjHZmV"
},
"outputs": [],
"source": [
"train_ds = load_dataset('train_cache')\n",
"test_ds = load_dataset('test_cache')"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3B80JXj7HloX"
},
"outputs": [],
"source": [
"train_ds.element_spec"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "5jfb8qknlsKi"
},
"source": [
"数据集现在返回适合使用 keras 进行训练的 `(input, label)` 对。`inputs` 是 `(images, input_tokens)` 对。`images` 已使用特征提取程序模型进行处理。对于 `input_tokens` 中的每个位置,模型会查看到目前为止的文本,并尝试预测在 `labels` 中相同位置排列的下一个文本。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "YJBEwuXLZQdw"
},
"outputs": [],
"source": [
"for (inputs, ex_labels) in train_ds.take(1):\n",
" (ex_img, ex_in_tok) = inputs\n",
"\n",
"print(ex_img.shape)\n",
"print(ex_in_tok.shape)\n",
"print(ex_labels.shape)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "22R58DzZoF17"
},
"source": [
"输入词例和标签相同,只移动了 1 步:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "V7h5UGftn1hT"
},
"outputs": [],
"source": [
"print(ex_in_tok[0].numpy())\n",
"print(ex_labels[0].numpy())"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "DfICM49WFpIb"
},
"source": [
"## Transformer 解码器模型"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ONyjuWsmZoyO"
},
"source": [
"此模型假设预训练的图像编码器已足够,并且只专注于构建文本解码器。本教程使用 2 层 Transformer 解码器。\n",
"\n",
"这些实现几乎与 [Transformer 教程](https://tensorflow.google.cn/text/tutorials/transformer)中的实现相同。请参阅该教程以了解更多详细信息。\n",
"\n",
"\n",
"\n",
" | Transformer 编码器和解码器 | \n",
"
\n",
"\n",
"  | \n",
"
\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qiRXWwIKNybB"
},
"source": [
"该模型将分以下三个主要部分实现:\n",
"\n",
"1. 输入 - 词例嵌入向量和位置编码 (`SeqEmbedding`)。\n",
"2. 解码器 - Transformer 解码器层堆叠 (`DecoderLayer`),其中每层包含:\n",
" 1. 一个因果自注意力层 (`CausalSelfAttention`),其中,每个输出位置都可以注意目前为止的输出。\n",
" 2. 一个交叉注意力层 (`CrossAttention`),其中每个输出位置都可以注意输入图像。\n",
" 3. 一个前馈网络 (`FeedForward`) 层,它进一步独立处理每个输出位置。\n",
"3. 输出 - 对输出词汇的多类分类。\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "_ngm3SQMCaYU"
},
"source": [
"### 输入"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "i9suaARZGPKw"
},
"source": [
"输入文本已被拆分为词例并转换为 ID 序列。\n",
"\n",
"请记住,与 CNN 或 RNN 不同,Transformer 的注意力层对序列的顺序是不变的。如果没有一些位置输入,它只会看到无序集而不是序列。因此,除了每个词例 ID 的简单向量嵌入之外,嵌入向量层还将包括序列中每个位置的嵌入向量。\n",
"\n",
"`SeqEmbedding` 层定义如下:\n",
"\n",
"- 它查找每个词例的嵌入向量。\n",
"- 它为每个序列位置查找一个嵌入向量。\n",
"- 将两者相加。\n",
"- 它使用 `mask_zero=True` 来初始化模型的 keras-mask。\n",
"\n",
"注:此实现学习位置嵌入向量,而不是像 [Transformer 教程](https://tensorflow.google.cn/text/tutorials/transformer)中那样使用固定嵌入向量。学习嵌入向量的代码略少,但不能泛化到更长的序列。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "P91LU2F0a9Ga"
},
"outputs": [],
"source": [
"class SeqEmbedding(tf.keras.layers.Layer):\n",
" def __init__(self, vocab_size, max_length, depth):\n",
" super().__init__()\n",
" self.pos_embedding = tf.keras.layers.Embedding(input_dim=max_length, output_dim=depth)\n",
"\n",
" self.token_embedding = tf.keras.layers.Embedding(\n",
" input_dim=vocab_size,\n",
" output_dim=depth,\n",
" mask_zero=True)\n",
" \n",
" self.add = tf.keras.layers.Add()\n",
"\n",
" def call(self, seq):\n",
" seq = self.token_embedding(seq) # (batch, seq, depth)\n",
"\n",
" x = tf.range(tf.shape(seq)[1]) # (seq)\n",
" x = x[tf.newaxis, :] # (1, seq)\n",
" x = self.pos_embedding(x) # (1, seq, depth)\n",
"\n",
" return self.add([seq,x])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "II1mD-bBCdMB"
},
"source": [
"### 解码器"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "GHMLeMtKPTCW"
},
"source": [
"解码器是一个标准的 Transformer 解码器,它包含 `DecoderLayers` 堆叠,其中每层包含三个子层:`CausalSelfAttention`、`CrossAttention` 和 `FeedForward`。实现几乎与 [Transformer 教程](https://tensorflow.google.cn/text/tutorials/transformer)相同,请参阅该教程以了解更多详细信息。\n",
"\n",
"`CausalSelfAttention` 层如下:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6JTLiX3lKooQ"
},
"outputs": [],
"source": [
"class CausalSelfAttention(tf.keras.layers.Layer):\n",
" def __init__(self, **kwargs):\n",
" super().__init__()\n",
" self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)\n",
" # Use Add instead of + so the keras mask propagates through.\n",
" self.add = tf.keras.layers.Add() \n",
" self.layernorm = tf.keras.layers.LayerNormalization()\n",
" \n",
" def call(self, x):\n",
" attn = self.mha(query=x, value=x,\n",
" use_causal_mask=True)\n",
" x = self.add([x, attn])\n",
" return self.layernorm(x)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8c66OTRwQfd8"
},
"source": [
"`CrossAttention` 层如下。注意 `return_attention_scores` 的使用。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "rIY6Vu2pLBAO"
},
"outputs": [],
"source": [
"class CrossAttention(tf.keras.layers.Layer):\n",
" def __init__(self,**kwargs):\n",
" super().__init__()\n",
" self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)\n",
" self.add = tf.keras.layers.Add() \n",
" self.layernorm = tf.keras.layers.LayerNormalization()\n",
" \n",
" def call(self, x, y, **kwargs):\n",
" attn, attention_scores = self.mha(\n",
" query=x, value=y,\n",
" return_attention_scores=True)\n",
" \n",
" self.last_attention_scores = attention_scores\n",
"\n",
" x = self.add([x, attn])\n",
" return self.layernorm(x)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8Hn5p6f-RE0C"
},
"source": [
"`FeedForward` 层如下。请记住,`layers.Dense` 层应用于输入的最后一个轴。输入的形状是 `(batch, sequence, channels)`,因此它会自动在 `batch` 和 `sequence` 轴上逐点应用。 "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "cWKrl7teOnH2"
},
"outputs": [],
"source": [
"class FeedForward(tf.keras.layers.Layer):\n",
" def __init__(self, units, dropout_rate=0.1):\n",
" super().__init__()\n",
" self.seq = tf.keras.Sequential([\n",
" tf.keras.layers.Dense(units=2*units, activation='relu'),\n",
" tf.keras.layers.Dense(units=units),\n",
" tf.keras.layers.Dropout(rate=dropout_rate),\n",
" ])\n",
"\n",
" self.layernorm = tf.keras.layers.LayerNormalization()\n",
" \n",
" def call(self, x):\n",
" x = x + self.seq(x)\n",
" return self.layernorm(x)\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "lbXoiVNPRoJc"
},
"source": [
"接下来将这三层排列成一个更大的 `DecoderLayer`。每个解码器层依次应用三个较小的层。在每个子层之后,`out_seq` 的形状是 `(batch, sequence, channels)`。解码器层还会返回 `attention_scores` 以用于后续呈现。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ydcW5KZZHou7"
},
"outputs": [],
"source": [
"class DecoderLayer(tf.keras.layers.Layer):\n",
" def __init__(self, units, num_heads=1, dropout_rate=0.1):\n",
" super().__init__()\n",
" \n",
" self.self_attention = CausalSelfAttention(num_heads=num_heads,\n",
" key_dim=units,\n",
" dropout=dropout_rate)\n",
" self.cross_attention = CrossAttention(num_heads=num_heads,\n",
" key_dim=units,\n",
" dropout=dropout_rate)\n",
" self.ff = FeedForward(units=units, dropout_rate=dropout_rate)\n",
" \n",
"\n",
" def call(self, inputs, training=False):\n",
" in_seq, out_seq = inputs\n",
"\n",
" # Text input\n",
" out_seq = self.self_attention(out_seq)\n",
"\n",
" out_seq = self.cross_attention(out_seq, in_seq)\n",
" \n",
" self.last_attention_scores = self.cross_attention.last_attention_scores\n",
"\n",
" out_seq = self.ff(out_seq)\n",
"\n",
" return out_seq"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-lgbYrF5Csqu"
},
"source": [
"### 输出"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "VcnKZkrklAQf"
},
"source": [
"输出层至少需要一个 `layers.Dense` 层来为每个位置的每个词例生成对数预测。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "6WQD87efena5"
},
"source": [
"但是,您可以添加一些其他功能来改善效果:\n",
"\n",
"1. **处理不良词例**:模型将生成文本。它绝不应该生成填充、未知或起始词例(`''`、`'[UNK]'`、`'[START]'`)。因此,将这些偏差设置为较大的负值。\n",
"\n",
" > 注:您还需要在损失函数中忽略这些词例。\n",
"\n",
"2. **智能初始化**:密集层的默认初始化将给出一个模型,此模型最初以几乎均匀的可能性预测每个词例。实际词例分布远非均匀。输出层初始偏差的最佳值是每个词例的概率的对数。因此,请包括一种 `adapt` 方法来计算词例并设置最佳初始偏差。这可以减少从均匀分布的熵 (`log(vocabulary_size)`) 到分布的边际熵 (`-p*log(p)`) 的初始损失。\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "CeWw2SFDHUfo"
},
"outputs": [],
"source": [
"#@title\n",
"class TokenOutput(tf.keras.layers.Layer):\n",
" def __init__(self, tokenizer, banned_tokens=('', '[UNK]', '[START]'), **kwargs):\n",
" super().__init__()\n",
" \n",
" self.dense = tf.keras.layers.Dense(\n",
" units=tokenizer.vocabulary_size(), **kwargs)\n",
" self.tokenizer = tokenizer\n",
" self.banned_tokens = banned_tokens\n",
"\n",
" self.bias = None\n",
"\n",
" def adapt(self, ds):\n",
" counts = collections.Counter()\n",
" vocab_dict = {name: id \n",
" for id, name in enumerate(self.tokenizer.get_vocabulary())}\n",
"\n",
" for tokens in tqdm.tqdm(ds):\n",
" counts.update(tokens.numpy().flatten())\n",
"\n",
" counts_arr = np.zeros(shape=(self.tokenizer.vocabulary_size(),))\n",
" counts_arr[np.array(list(counts.keys()), dtype=np.int32)] = list(counts.values())\n",
"\n",
" counts_arr = counts_arr[:]\n",
" for token in self.banned_tokens:\n",
" counts_arr[vocab_dict[token]] = 0\n",
"\n",
" total = counts_arr.sum()\n",
" p = counts_arr/total\n",
" p[counts_arr==0] = 1.0\n",
" log_p = np.log(p) # log(1) == 0\n",
"\n",
" entropy = -(log_p*p).sum()\n",
"\n",
" print()\n",
" print(f\"Uniform entropy: {np.log(self.tokenizer.vocabulary_size()):0.2f}\")\n",
" print(f\"Marginal entropy: {entropy:0.2f}\")\n",
"\n",
" self.bias = log_p\n",
" self.bias[counts_arr==0] = -1e9\n",
"\n",
" def call(self, x):\n",
" x = self.dense(x)\n",
" # TODO(b/250038731): Fix this.\n",
" # An Add layer doesn't work because of the different shapes.\n",
" # This clears the mask, that's okay because it prevents keras from rescaling\n",
" # the losses.\n",
" return x + self.bias\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xzQHqANd1A6Q"
},
"source": [
"智能初始化将显著减少初始损失:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "GGnOQyc501B2"
},
"outputs": [],
"source": [
"output_layer = TokenOutput(tokenizer, banned_tokens=('', '[UNK]', '[START]'))\n",
"# This might run a little faster if the dataset didn't also have to load the image data.\n",
"output_layer.adapt(train_ds.map(lambda inputs, labels: labels))"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3gq-ICN7bD-u"
},
"source": [
"### 构建模型"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gou4fPH_SWgH"
},
"source": [
"要构建模型,您需要结合以下几个部分:\n",
"\n",
"1. 图像 `feature_extractor` 和文本 `tokenizer`。\n",
"2. `seq_embedding` 层,将词例 ID 批次转换为向量 `(batch, sequence, channels)`。\n",
"3. 将处理文本和图像数据的 `DecoderLayers` 层堆叠。\n",
"4. `output_layer` 返回下一个字词应该是什么的逐点预测。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "bHCISYehH1f6"
},
"outputs": [],
"source": [
"class Captioner(tf.keras.Model):\n",
" @classmethod\n",
" def add_method(cls, fun):\n",
" setattr(cls, fun.__name__, fun)\n",
" return fun\n",
"\n",
" def __init__(self, tokenizer, feature_extractor, output_layer, num_layers=1,\n",
" units=256, max_length=50, num_heads=1, dropout_rate=0.1):\n",
" super().__init__()\n",
" self.feature_extractor = feature_extractor\n",
" self.tokenizer = tokenizer\n",
" self.word_to_index = tf.keras.layers.StringLookup(\n",
" mask_token=\"\",\n",
" vocabulary=tokenizer.get_vocabulary())\n",
" self.index_to_word = tf.keras.layers.StringLookup(\n",
" mask_token=\"\",\n",
" vocabulary=tokenizer.get_vocabulary(),\n",
" invert=True) \n",
"\n",
" self.seq_embedding = SeqEmbedding(\n",
" vocab_size=tokenizer.vocabulary_size(),\n",
" depth=units,\n",
" max_length=max_length)\n",
"\n",
" self.decoder_layers = [\n",
" DecoderLayer(units, num_heads=num_heads, dropout_rate=dropout_rate)\n",
" for n in range(num_layers)]\n",
"\n",
" self.output_layer = output_layer"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "YW390dOz9T-x"
},
"source": [
"当您调用模型进行训练时,它会收到一个 `image, txt` 对。为了让这个函数更有用,需要灵活处理输入:\n",
"\n",
"- 如果图像有 3 个通道,则通过特征提取程序运行它。否则,假设它已经存在。类似地\n",
"- 如果文本的数据类型为 `tf.string`,则通过分词器运行它。\n",
"\n",
"之后,运行模型只需以下几个步骤:\n",
"\n",
"1. 展平提取的图像特征,以便它们可以输入到解码器层。\n",
"2. 查找词例嵌入向量。\n",
"3. 在图像特征和文本嵌入向量上运行 `DecoderLayer` 堆叠。\n",
"4. 运行输出层以预测每个位置的下一个词例。\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "lPdb7I4h9Ulo"
},
"outputs": [],
"source": [
" @Captioner.add_method\n",
" def call(self, inputs):\n",
" image, txt = inputs\n",
"\n",
" if image.shape[-1] == 3:\n",
" # Apply the feature-extractor, if you get an RGB image.\n",
" image = self.feature_extractor(image)\n",
" \n",
" # Flatten the feature map\n",
" image = einops.rearrange(image, 'b h w c -> b (h w) c')\n",
"\n",
"\n",
" if txt.dtype == tf.string:\n",
" # Apply the tokenizer if you get string inputs.\n",
" txt = tokenizer(txt)\n",
"\n",
" txt = self.seq_embedding(txt)\n",
"\n",
" # Look at the image\n",
" for dec_layer in self.decoder_layers:\n",
" txt = dec_layer(inputs=(image, txt))\n",
" \n",
" txt = self.output_layer(txt)\n",
"\n",
" return txt"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "kmM7aZQsLiyU"
},
"outputs": [],
"source": [
"model = Captioner(tokenizer, feature_extractor=mobilenet, output_layer=output_layer,\n",
" units=256, dropout_rate=0.5, num_layers=2, num_heads=2)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "xGvOcLQKghXN"
},
"source": [
"### 生成描述\n",
"\n",
"在开始训练之前,编写一些代码来生成描述。您将使用它来查看训练的进展。\n",
"\n",
"首先,下载一个测试图像:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "cwFcdMqC-jE2"
},
"outputs": [],
"source": [
"image_url = 'https://tensorflow.org/images/surf.jpg'\n",
"image_path = tf.keras.utils.get_file('surf.jpg', origin=image_url)\n",
"image = load_image(image_path)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "IRBIiTkubmxA"
},
"source": [
"要使用此模型为图像添加描述,请执行以下操作:\n",
"\n",
"- 提取 `img_features`\n",
"- 使用 `[START]` 词例初始化输出词例列表。\n",
"- 将 `img_features` 和 `tokens` 传递到模型中。\n",
" - 它返回一个对数列表。\n",
" - 根据这些对数选择下一个词例。\n",
" - 将其添加到词例列表中,然后继续循环。\n",
" - 如果它生成一个 `'[END]'` 词例,则跳出循环。\n",
"\n",
"因此,添加一个“简单”的方法来实现此目标:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "Nf1Jie9ef_Cg"
},
"outputs": [],
"source": [
"@Captioner.add_method\n",
"def simple_gen(self, image, temperature=1):\n",
" initial = self.word_to_index([['[START]']]) # (batch, sequence)\n",
" img_features = self.feature_extractor(image[tf.newaxis, ...])\n",
"\n",
" tokens = initial # (batch, sequence)\n",
" for n in range(50):\n",
" preds = self((img_features, tokens)).numpy() # (batch, sequence, vocab)\n",
" preds = preds[:,-1, :] #(batch, vocab)\n",
" if temperature==0:\n",
" next = tf.argmax(preds, axis=-1)[:, tf.newaxis] # (batch, 1)\n",
" else:\n",
" next = tf.random.categorical(preds/temperature, num_samples=1) # (batch, 1)\n",
" tokens = tf.concat([tokens, next], axis=1) # (batch, sequence) \n",
"\n",
" if next[0] == self.word_to_index('[END]'):\n",
" break\n",
" words = index_to_word(tokens[0, 1:-1])\n",
" result = tf.strings.reduce_join(words, axis=-1, separator=' ')\n",
" return result.numpy().decode()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "TxN2NPX2zB8y"
},
"source": [
"以下是为该图像生成的一些描述,该模型未经训练,因此它们还没有太大意义:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "sPm96CccvHnq"
},
"outputs": [],
"source": [
"for t in (0.0, 0.5, 1.0):\n",
" result = model.simple_gen(image, temperature=t)\n",
" print(result)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "JefwCRZ8z-Ah"
},
"source": [
"温度参数允许您在 3 种模式之间进行插值:\n",
"\n",
"1. 贪婪解码 (`temperature=0.0`) - 在每一步选择最有可能的下一个词例。\n",
"2. 根据 logit (`temperature=1.0`) 随机抽样。\n",
"3. 均匀随机抽样 (`temperature >> 1.0`)。\n",
"\n",
"由于模型未经训练,并且它使用基于频率的初始化,“贪婪”输出(第一个)通常只包含最常见的词例:`['a', '.', '[END]']`。"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "r0FpTvaPkqON"
},
"source": [
"## 训练"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "IKcwZdqObK-U"
},
"source": [
"要训练模型,您需要几个额外的组件:\n",
"\n",
"- 损失和指标\n",
"- 优化器\n",
"- 可选回调"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "g5IW2mWa2sAG"
},
"source": [
"### 损失和指标"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "XbpbDQTw1lOW"
},
"source": [
"下面是一个遮盖损失和准确率的实现:\n",
"\n",
"在计算损失的掩码时,请注意 `loss < 1e8`。此术语丢弃了 `banned_tokens` 的人为不可能高损失。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "s24im3FqxAfT"
},
"outputs": [],
"source": [
"def masked_loss(labels, preds): \n",
" loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels, preds)\n",
"\n",
" mask = (labels != 0) & (loss < 1e8) \n",
" mask = tf.cast(mask, loss.dtype)\n",
"\n",
" loss = loss*mask\n",
" loss = tf.reduce_sum(loss)/tf.reduce_sum(mask)\n",
" return loss\n",
"\n",
"def masked_acc(labels, preds):\n",
" mask = tf.cast(labels!=0, tf.float32)\n",
" preds = tf.argmax(preds, axis=-1)\n",
" labels = tf.cast(labels, tf.int64)\n",
" match = tf.cast(preds == labels, mask.dtype)\n",
" acc = tf.reduce_sum(match*mask)/tf.reduce_sum(mask)\n",
" return acc"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "zOhjHqgv3F2e"
},
"source": [
"### 回调"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3dyQN9UfJYEd"
},
"source": [
"对于训练设置期间的反馈,使用 `keras.callbacks.Callback` 在每个周期结束时为冲浪者图像生成一些描述。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "IKDwbZOCZ-AP"
},
"outputs": [],
"source": [
"class GenerateText(tf.keras.callbacks.Callback):\n",
" def __init__(self):\n",
" image_url = 'https://tensorflow.org/images/surf.jpg'\n",
" image_path = tf.keras.utils.get_file('surf.jpg', origin=image_url)\n",
" self.image = load_image(image_path)\n",
"\n",
" def on_epoch_end(self, epochs=None, logs=None):\n",
" print()\n",
" print()\n",
" for t in (0.0, 0.5, 1.0):\n",
" result = self.model.simple_gen(self.image, temperature=t)\n",
" print(result)\n",
" print()\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "1yNA3_RAsdl0"
},
"source": [
"像之前的示例一样,它生成三个输出字符串,第一个是“greedy”,在每个步骤中选择 logit 的 argmax。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "IGVLpzo13rcA"
},
"outputs": [],
"source": [
"g = GenerateText()\n",
"g.model = model\n",
"g.on_epoch_end(0)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MAxp4KZRKDk9"
},
"source": [
"当模型开始过拟合时,还可以使用 `callbacks.EarlyStopping` 终止训练。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "MjzrwGZp23xx"
},
"outputs": [],
"source": [
"callbacks = [\n",
" GenerateText(),\n",
" tf.keras.callbacks.EarlyStopping(\n",
" patience=5, restore_best_weights=True)]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ZBaJhQpcG8u0"
},
"source": [
"### 训练"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "WBXG0dCDKO55"
},
"source": [
"配置并执行训练。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "2OR5ZpAII__u"
},
"outputs": [],
"source": [
"model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4),\n",
" loss=masked_loss,\n",
" metrics=[masked_acc])"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "ro955bQ2KR0X"
},
"source": [
"如需更频繁的报告,请使用 `Dataset.repeat()` 方法,并将 `steps_per_epoch` 和 `validation_steps` 参数设置为 `Model.fit`。\n",
"\n",
"在 `Flickr8k` 上使用此设置,数据集上的全通是 900 多个批次,但下面的报告周期为 100 步。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "3aB0baOVMZe9"
},
"outputs": [],
"source": [
"history = model.fit(\n",
" train_ds.repeat(),\n",
" steps_per_epoch=100,\n",
" validation_data=test_ds.repeat(),\n",
" validation_steps=20,\n",
" epochs=100,\n",
" callbacks=callbacks)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "P634LfVgw-eV"
},
"source": [
"绘制训练运行的损失和准确率:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "6Wn8KSkUw916"
},
"outputs": [],
"source": [
"plt.plot(history.history['loss'], label='loss')\n",
"plt.plot(history.history['val_loss'], label='val_loss')\n",
"plt.ylim([0, max(plt.ylim())])\n",
"plt.xlabel('Epoch #')\n",
"plt.ylabel('CE/token')\n",
"plt.legend()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "yZQ78b2Kxw-T"
},
"outputs": [],
"source": [
"plt.plot(history.history['masked_acc'], label='accuracy')\n",
"plt.plot(history.history['val_masked_acc'], label='val_accuracy')\n",
"plt.ylim([0, max(plt.ylim())])\n",
"plt.xlabel('Epoch #')\n",
"plt.ylabel('CE/token')\n",
"plt.legend()"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "SQN1qT7KNqbL"
},
"source": [
"## 注意力图"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "E9XJaC2b2J23"
},
"source": [
"现在,使用经过训练的模型,在图像上运行 `simple_gen` 方法:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "1UQPtNTb2eu3"
},
"outputs": [],
"source": [
"result = model.simple_gen(image, temperature=0.0)\n",
"result"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "7NXbmeLGN1bJ"
},
"source": [
"将输出拆分回词例:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "zHKOpm0w5Xto"
},
"outputs": [],
"source": [
"str_tokens = result.split()\n",
"str_tokens.append('[END]')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fE-AjuAV55Qo"
},
"source": [
"每个 `DecoderLayers` 都为其 `CrossAttention` 层缓存注意力分数。每个注意力图的形状为 `(batch=1, heads, sequence, image)`:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "XZpyuQvq2q-B"
},
"outputs": [],
"source": [
"attn_maps = [layer.last_attention_scores for layer in model.decoder_layers]\n",
"[map.shape for map in attn_maps]"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "T42ImsWv6oHG"
},
"source": [
"因此,沿 `batch` 轴堆叠映射,然后在 `(batch, heads)` 轴上计算平均值,同时将 `image` 轴拆分回 `height, width`:\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ojwtvnkh6mS-"
},
"outputs": [],
"source": [
"attention_maps = tf.concat(attn_maps, axis=0)\n",
"attention_maps = einops.reduce(\n",
" attention_maps,\n",
" 'batch heads sequence (height width) -> sequence height width',\n",
" height=7, width=7,\n",
" reduction='mean')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "4TM7rA3zGpJW"
},
"source": [
"现在,对于每个序列预测,您都有一个注意力图。每个映射中的值总和应为 `1`。"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "ASWmWerGCZp3"
},
"outputs": [],
"source": [
"einops.reduce(attention_maps, 'sequence height width -> sequence', reduction='sum')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "fv7XYGFUd-U7"
},
"source": [
"下面是模型在生成输出的每个词例时集中注意力的地方:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "fD_y7PD6RPGt"
},
"outputs": [],
"source": [
"def plot_attention_maps(image, str_tokens, attention_map):\n",
" fig = plt.figure(figsize=(16, 9))\n",
"\n",
" len_result = len(str_tokens)\n",
" \n",
" titles = []\n",
" for i in range(len_result):\n",
" map = attention_map[i]\n",
" grid_size = max(int(np.ceil(len_result/2)), 2)\n",
" ax = fig.add_subplot(3, grid_size, i+1)\n",
" titles.append(ax.set_title(str_tokens[i]))\n",
" img = ax.imshow(image)\n",
" ax.imshow(map, cmap='gray', alpha=0.6, extent=img.get_extent(),\n",
" clim=[0.0, np.max(map)])\n",
"\n",
" plt.tight_layout()"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "PI4NAAws9rvY"
},
"outputs": [],
"source": [
"plot_attention_maps(image/255, str_tokens, attention_maps)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "riTz0abQKMkV"
},
"source": [
"现在,将它们组合成一个更有用的函数:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "mktpfW-SKQIJ"
},
"outputs": [],
"source": [
"@Captioner.add_method\n",
"def run_and_show_attention(self, image, temperature=0.0):\n",
" result_txt = self.simple_gen(image, temperature)\n",
" str_tokens = result_txt.split()\n",
" str_tokens.append('[END]')\n",
"\n",
" attention_maps = [layer.last_attention_scores for layer in self.decoder_layers]\n",
" attention_maps = tf.concat(attention_maps, axis=0)\n",
" attention_maps = einops.reduce(\n",
" attention_maps,\n",
" 'batch heads sequence (height width) -> sequence height width',\n",
" height=7, width=7,\n",
" reduction='mean')\n",
" \n",
" plot_attention_maps(image/255, str_tokens, attention_maps)\n",
" t = plt.suptitle(result_txt)\n",
" t.set_y(1.05)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "FntRkY11OiMw"
},
"outputs": [],
"source": [
"run_and_show_attention(model, image)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Rprk3HEvZuxb"
},
"source": [
"## 在自己的图像上进行尝试\n",
"\n",
"为了增加趣味性,下面会提供一个方法,让您可以通过刚才训练的模型为您自己的图像生成描述。请记住,这个模型是使用较少数据训练的,而您的图像可能与训练数据不同(因此,请做好心理准备,您可能会得到奇怪的结果!)\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"id": "9Psd1quzaAWg"
},
"outputs": [],
"source": [
"image_url = 'https://tensorflow.org/images/bedroom_hrnet_tutorial.jpg'\n",
"image_path = tf.keras.utils.get_file(origin=image_url)\n",
"image = load_image(image_path)\n",
"\n",
"run_and_show_attention(model, image)"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"collapsed_sections": [],
"name": "image_captioning.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
 在 GitHub 上查看源代码
在 GitHub 上查看源代码{kind=link}