{
"cells": [
{
"cell_type": "markdown",
"metadata": {
"id": "toCy3v03Dwx7"
},
"source": [
"##### Copyright 2021 The TensorFlow Hub Authors.\n",
"\n",
"Licensed under the Apache License, Version 2.0 (the \"License\");"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:24:58.790209Z",
"iopub.status.busy": "2024-03-09T13:24:58.789673Z",
"iopub.status.idle": "2024-03-09T13:24:58.793856Z",
"shell.execute_reply": "2024-03-09T13:24:58.793175Z"
},
"id": "QKe-ubNcDvgv"
},
"outputs": [],
"source": [
"# Copyright 2021 The TensorFlow Hub Authors. All Rights Reserved.\n",
"#\n",
"# Licensed under the Apache License, Version 2.0 (the \"License\");\n",
"# you may not use this file except in compliance with the License.\n",
"# You may obtain a copy of the License at\n",
"#\n",
"# http://www.apache.org/licenses/LICENSE-2.0\n",
"#\n",
"# Unless required by applicable law or agreed to in writing, software\n",
"# distributed under the License is distributed on an \"AS IS\" BASIS,\n",
"# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n",
"# See the License for the specific language governing permissions and\n",
"# limitations under the License.\n",
"# =============================================================================="
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qFdPvlXBOdUN"
},
"source": [
"# MoViNet for streaming action recognition "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "MfBg1C5NB3X0"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "-vxk2Kbc_KSP"
},
"source": [
"This tutorial demonstrates how to use a pretrained video classification model to classify an activity (such as dancing, swimming, biking etc) in the given video. \n",
"\n",
"The model architecture used in this tutorial is called [MoViNet](https://arxiv.org/pdf/2103.11511.pdf) (Mobile Video Networks). MoVieNets are a family of efficient video classification models trained on huge dataset ([Kinetics 600](https://deepmind.com/research/open-source/kinetics)).\n",
"\n",
"In contrast to the [i3d models](https://tfhub.dev/s?q=i3d-kinetics) available on TF Hub, MoViNets also support frame-by-frame inference on streaming video. \n",
"\n",
"The pretrained models are available from [TF Hub](https://tfhub.dev/google/collections/movinet/1). The TF Hub collection also includes quantized models optimized for [TFLite](https://tensorflow.org/lite).\n",
"\n",
"The source for these models is available in the [TensorFlow Model Garden](https://github.com/tensorflow/models/tree/master/official/projects/movinet). This includes a [longer version of this tutorial](https://colab.sandbox.google.com/github/tensorflow/models/blob/master/official/projects/movinet/movinet_tutorial.ipynb) that also covers building and fine-tuning a MoViNet model. \n",
"\n",
"This MoViNet tutorial is part of a series of TensorFlow video tutorials. Here are the other three tutorials:\n",
"\n",
"- [Load video data](https://www.tensorflow.org/tutorials/load_data/video): This tutorial explains how to load and preprocess video data into a TensorFlow dataset pipeline from scratch.\n",
"- [Build a 3D CNN model for video classification](https://www.tensorflow.org/tutorials/video/video_classification). Note that this tutorial uses a (2+1)D CNN that decomposes the spatial and temporal aspects of 3D data; if you are using volumetric data such as an MRI scan, consider using a 3D CNN instead of a (2+1)D CNN.\n",
"- [Transfer learning for video classification with MoViNet](https://www.tensorflow.org/tutorials/video/transfer_learning_with_movinet): This tutorial explains how to use a pre-trained video classification model trained on a different dataset with the UCF-101 dataset.\n"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "3E96e1UKQ8uR"
},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "8_oLnvJy7kz5"
},
"source": [
"## Setup\n",
"\n",
"For inference on smaller models (A0-A2), CPU is sufficient for this Colab."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:24:58.797816Z",
"iopub.status.busy": "2024-03-09T13:24:58.797275Z",
"iopub.status.idle": "2024-03-09T13:25:01.970836Z",
"shell.execute_reply": "2024-03-09T13:25:01.969661Z"
},
"id": "GUgUMGmY1yq-"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\r",
"Reading package lists... 0%\r",
"\r",
"Reading package lists... 100%\r",
"\r",
"Reading package lists... Done\r",
"\r\n",
"\r",
"Building dependency tree... 0%\r",
"\r",
"Building dependency tree... 0%\r"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\r",
"Building dependency tree... 50%\r",
"\r",
"Building dependency tree... 50%\r"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\r",
"Building dependency tree \r",
"\r\n",
"\r",
"Reading state information... 0%\r",
"\r",
"Reading state information... 0%\r",
"\r",
"Reading state information... Done\r",
"\r\n",
"ffmpeg is already the newest version (7:4.2.7-0ubuntu0.1).\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"The following packages were automatically installed and are no longer required:\r\n",
" libatasmart4 libblockdev-fs2 libblockdev-loop2 libblockdev-part-err2\r\n",
" libblockdev-part2 libblockdev-swap2 libblockdev-utils2 libblockdev2\r\n",
" libparted-fs-resize0 libxmlb2\r\n",
"Use 'sudo apt autoremove' to remove them.\r\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"0 upgraded, 0 newly installed, 0 to remove and 187 not upgraded.\r\n"
]
}
],
"source": [
"!sudo apt install -y ffmpeg\n",
"!pip install -q mediapy"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:25:01.975699Z",
"iopub.status.busy": "2024-03-09T13:25:01.974960Z",
"iopub.status.idle": "2024-03-09T13:25:07.556080Z",
"shell.execute_reply": "2024-03-09T13:25:07.554957Z"
},
"id": "s3khsunT7kWa"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"\u001b[33mWARNING: Skipping opencv-python-headless as it is not installed.\u001b[0m\u001b[33m\r\n",
"\u001b[0m"
]
}
],
"source": [
"!pip uninstall -q -y opencv-python-headless\n",
"!pip install -q \"opencv-python-headless<4.3\""
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:25:07.561073Z",
"iopub.status.busy": "2024-03-09T13:25:07.560342Z",
"iopub.status.idle": "2024-03-09T13:25:10.765770Z",
"shell.execute_reply": "2024-03-09T13:25:10.764883Z"
},
"id": "dI_1csl6Q-gH"
},
"outputs": [],
"source": [
"# Import libraries\n",
"import pathlib\n",
"\n",
"import matplotlib as mpl\n",
"import matplotlib.pyplot as plt\n",
"import mediapy as media\n",
"import numpy as np\n",
"import PIL\n",
"\n",
"import tensorflow as tf\n",
"import tensorflow_hub as hub\n",
"import tqdm\n",
"\n",
"mpl.rcParams.update({\n",
" 'font.size': 10,\n",
"})"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "Pn8K9oWbmREi"
},
"source": [
"Get the kinetics 600 label list, and print the first few labels:"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:25:10.770638Z",
"iopub.status.busy": "2024-03-09T13:25:10.769864Z",
"iopub.status.idle": "2024-03-09T13:25:10.912445Z",
"shell.execute_reply": "2024-03-09T13:25:10.911692Z"
},
"id": "2VJUAcjhkfb3"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Downloading data from https://raw.githubusercontent.com/tensorflow/models/f8af2291cced43fc9f1d9b41ddbf772ae7b0d7d2/official/projects/movinet/files/kinetics_600_labels.txt\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\r",
"\u001b[1m 0/9209\u001b[0m \u001b[37m━━━━━━━━━━━━━━━━━━━━\u001b[0m \u001b[1m0s\u001b[0m 0s/step"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\r",
"\u001b[1m9209/9209\u001b[0m \u001b[32m━━━━━━━━━━━━━━━━━━━━\u001b[0m\u001b[37m\u001b[0m \u001b[1m0s\u001b[0m 0us/step\n"
]
},
{
"data": {
"text/plain": [
"array(['abseiling', 'acting in play', 'adjusting glasses', 'air drumming',\n",
" 'alligator wrestling', 'answering questions', 'applauding',\n",
" 'applying cream', 'archaeological excavation', 'archery',\n",
" 'arguing', 'arm wrestling', 'arranging flowers',\n",
" 'assembling bicycle', 'assembling computer',\n",
" 'attending conference', 'auctioning', 'backflip (human)',\n",
" 'baking cookies', 'bandaging'], dtype='"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"id = tf.argmax(probabilities[-1])\n",
"plt.plot(probabilities[:, id])\n",
"plt.xlabel('Frame #')\n",
"plt.ylabel(f\"p('{KINETICS_600_LABELS[id]}')\");"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "d7MZ_AfRW845"
},
"source": [
"You may notice that the final probability is much more certain than in the previous section where you ran the `base` model. The `base` model returns an average of the predictions over the frames."
]
},
{
"cell_type": "code",
"execution_count": 27,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:26:46.579472Z",
"iopub.status.busy": "2024-03-09T13:26:46.578827Z",
"iopub.status.idle": "2024-03-09T13:26:46.586320Z",
"shell.execute_reply": "2024-03-09T13:26:46.585621Z"
},
"id": "0Wij4tsyW8dR"
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"golf chipping : 0.427\n",
"tackling : 0.134\n",
"lunge : 0.056\n",
"stretching arm : 0.053\n",
"passing american football (not in game): 0.039\n"
]
}
],
"source": [
"for label, p in get_top_k(tf.reduce_mean(probabilities, axis=0)):\n",
" print(f'{label:20s}: {p:.3f}')"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "qLUoC9ejggGo"
},
"source": [
"## Animate the predictions over time\n",
"\n",
"The previous section went into some details about how to use these models. This section builds on top of that to produce some nice inference animations. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "OnFqOXazoWgy"
},
"source": [
"The hidden cell below to defines helper functions used in this section."
]
},
{
"cell_type": "code",
"execution_count": 28,
"metadata": {
"cellView": "form",
"execution": {
"iopub.execute_input": "2024-03-09T13:26:46.590120Z",
"iopub.status.busy": "2024-03-09T13:26:46.589730Z",
"iopub.status.idle": "2024-03-09T13:26:46.610263Z",
"shell.execute_reply": "2024-03-09T13:26:46.609542Z"
},
"id": "dx55NK3ZoZeh"
},
"outputs": [],
"source": [
"#@title\n",
"# Get top_k labels and probabilities predicted using MoViNets streaming model\n",
"def get_top_k_streaming_labels(probs, k=5, label_map=KINETICS_600_LABELS):\n",
" \"\"\"Returns the top-k labels over an entire video sequence.\n",
"\n",
" Args:\n",
" probs: probability tensor of shape (num_frames, num_classes) that represents\n",
" the probability of each class on each frame.\n",
" k: the number of top predictions to select.\n",
" label_map: a list of labels to map logit indices to label strings.\n",
"\n",
" Returns:\n",
" a tuple of the top-k probabilities, labels, and logit indices\n",
" \"\"\"\n",
" top_categories_last = tf.argsort(probs, -1, 'DESCENDING')[-1, :1]\n",
" # Sort predictions to find top_k\n",
" categories = tf.argsort(probs, -1, 'DESCENDING')[:, :k]\n",
" categories = tf.reshape(categories, [-1])\n",
"\n",
" counts = sorted([\n",
" (i.numpy(), tf.reduce_sum(tf.cast(categories == i, tf.int32)).numpy())\n",
" for i in tf.unique(categories)[0]\n",
" ], key=lambda x: x[1], reverse=True)\n",
"\n",
" top_probs_idx = tf.constant([i for i, _ in counts[:k]])\n",
" top_probs_idx = tf.concat([top_categories_last, top_probs_idx], 0)\n",
" # find unique indices of categories\n",
" top_probs_idx = tf.unique(top_probs_idx)[0][:k+1]\n",
" # top_k probabilities of the predictions\n",
" top_probs = tf.gather(probs, top_probs_idx, axis=-1)\n",
" top_probs = tf.transpose(top_probs, perm=(1, 0))\n",
" # collect the labels of top_k predictions\n",
" top_labels = tf.gather(label_map, top_probs_idx, axis=0)\n",
" # decode the top_k labels\n",
" top_labels = [label.decode('utf8') for label in top_labels.numpy()]\n",
"\n",
" return top_probs, top_labels, top_probs_idx\n",
"\n",
"# Plot top_k predictions at a given time step\n",
"def plot_streaming_top_preds_at_step(\n",
" top_probs,\n",
" top_labels,\n",
" step=None,\n",
" image=None,\n",
" legend_loc='lower left',\n",
" duration_seconds=10,\n",
" figure_height=500,\n",
" playhead_scale=0.8,\n",
" grid_alpha=0.3):\n",
" \"\"\"Generates a plot of the top video model predictions at a given time step.\n",
"\n",
" Args:\n",
" top_probs: a tensor of shape (k, num_frames) representing the top-k\n",
" probabilities over all frames.\n",
" top_labels: a list of length k that represents the top-k label strings.\n",
" step: the current time step in the range [0, num_frames].\n",
" image: the image frame to display at the current time step.\n",
" legend_loc: the placement location of the legend.\n",
" duration_seconds: the total duration of the video.\n",
" figure_height: the output figure height.\n",
" playhead_scale: scale value for the playhead.\n",
" grid_alpha: alpha value for the gridlines.\n",
"\n",
" Returns:\n",
" A tuple of the output numpy image, figure, and axes.\n",
" \"\"\"\n",
" # find number of top_k labels and frames in the video\n",
" num_labels, num_frames = top_probs.shape\n",
" if step is None:\n",
" step = num_frames\n",
" # Visualize frames and top_k probabilities of streaming video\n",
" fig = plt.figure(figsize=(6.5, 7), dpi=300)\n",
" gs = mpl.gridspec.GridSpec(8, 1)\n",
" ax2 = plt.subplot(gs[:-3, :])\n",
" ax = plt.subplot(gs[-3:, :])\n",
" # display the frame\n",
" if image is not None:\n",
" ax2.imshow(image, interpolation='nearest')\n",
" ax2.axis('off')\n",
" # x-axis (frame number)\n",
" preview_line_x = tf.linspace(0., duration_seconds, num_frames)\n",
" # y-axis (top_k probabilities)\n",
" preview_line_y = top_probs\n",
"\n",
" line_x = preview_line_x[:step+1]\n",
" line_y = preview_line_y[:, :step+1]\n",
"\n",
" for i in range(num_labels):\n",
" ax.plot(preview_line_x, preview_line_y[i], label=None, linewidth='1.5',\n",
" linestyle=':', color='gray')\n",
" ax.plot(line_x, line_y[i], label=top_labels[i], linewidth='2.0')\n",
"\n",
"\n",
" ax.grid(which='major', linestyle=':', linewidth='1.0', alpha=grid_alpha)\n",
" ax.grid(which='minor', linestyle=':', linewidth='0.5', alpha=grid_alpha)\n",
"\n",
" min_height = tf.reduce_min(top_probs) * playhead_scale\n",
" max_height = tf.reduce_max(top_probs)\n",
" ax.vlines(preview_line_x[step], min_height, max_height, colors='red')\n",
" ax.scatter(preview_line_x[step], max_height, color='red')\n",
"\n",
" ax.legend(loc=legend_loc)\n",
"\n",
" plt.xlim(0, duration_seconds)\n",
" plt.ylabel('Probability')\n",
" plt.xlabel('Time (s)')\n",
" plt.yscale('log')\n",
"\n",
" fig.tight_layout()\n",
" fig.canvas.draw()\n",
"\n",
" data = np.frombuffer(fig.canvas.tostring_rgb(), dtype=np.uint8)\n",
" data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))\n",
" plt.close()\n",
"\n",
" figure_width = int(figure_height * data.shape[1] / data.shape[0])\n",
" image = PIL.Image.fromarray(data).resize([figure_width, figure_height])\n",
" image = np.array(image)\n",
"\n",
" return image\n",
"\n",
"# Plotting top_k predictions from MoViNets streaming model\n",
"def plot_streaming_top_preds(\n",
" probs,\n",
" video,\n",
" top_k=5,\n",
" video_fps=25.,\n",
" figure_height=500,\n",
" use_progbar=True):\n",
" \"\"\"Generates a video plot of the top video model predictions.\n",
"\n",
" Args:\n",
" probs: probability tensor of shape (num_frames, num_classes) that represents\n",
" the probability of each class on each frame.\n",
" video: the video to display in the plot.\n",
" top_k: the number of top predictions to select.\n",
" video_fps: the input video fps.\n",
" figure_fps: the output video fps.\n",
" figure_height: the height of the output video.\n",
" use_progbar: display a progress bar.\n",
"\n",
" Returns:\n",
" A numpy array representing the output video.\n",
" \"\"\"\n",
" # select number of frames per second\n",
" video_fps = 8.\n",
" # select height of the image\n",
" figure_height = 500\n",
" # number of time steps of the given video\n",
" steps = video.shape[0]\n",
" # estimate duration of the video (in seconds)\n",
" duration = steps / video_fps\n",
" # estimate top_k probabilities and corresponding labels\n",
" top_probs, top_labels, _ = get_top_k_streaming_labels(probs, k=top_k)\n",
"\n",
" images = []\n",
" step_generator = tqdm.trange(steps) if use_progbar else range(steps)\n",
" for i in step_generator:\n",
" image = plot_streaming_top_preds_at_step(\n",
" top_probs=top_probs,\n",
" top_labels=top_labels,\n",
" step=i,\n",
" image=video[i],\n",
" duration_seconds=duration,\n",
" figure_height=figure_height,\n",
" )\n",
" images.append(image)\n",
"\n",
" return np.array(images)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "eLgFBslcZOQO"
},
"source": [
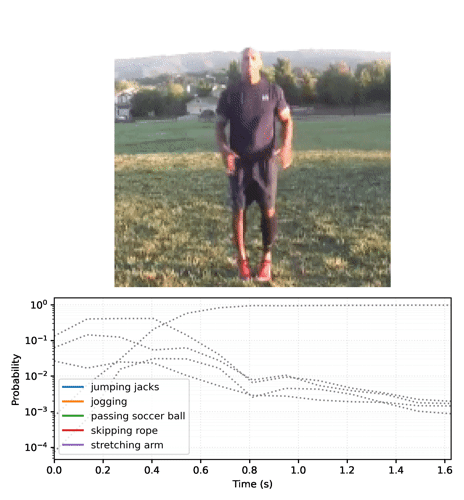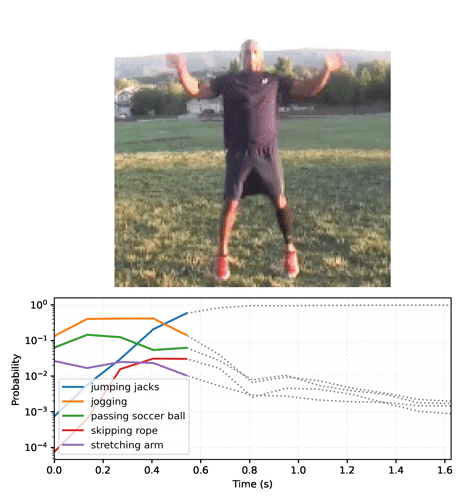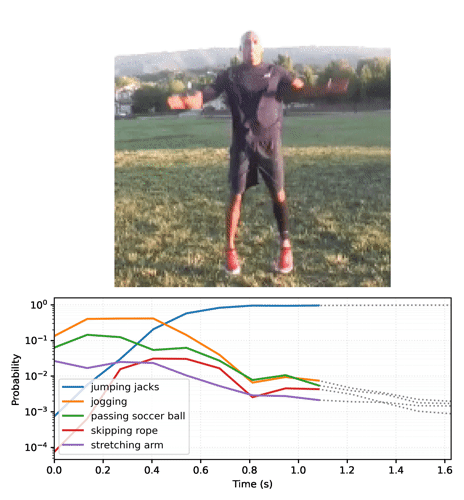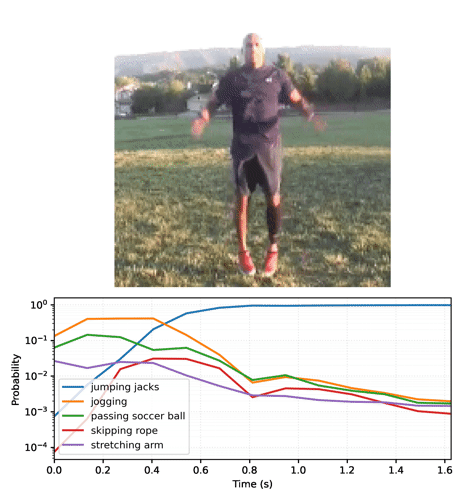
"Start by running the streaming model across the frames of the video, and collecting the logits:"
]
},
{
"cell_type": "code",
"execution_count": 29,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:26:46.613693Z",
"iopub.status.busy": "2024-03-09T13:26:46.613144Z",
"iopub.status.idle": "2024-03-09T13:26:46.871014Z",
"shell.execute_reply": "2024-03-09T13:26:46.869969Z"
},
"id": "tXWR13wthnK5"
},
"outputs": [],
"source": [
"init_states = model.init_states(jumpingjack[tf.newaxis].shape)"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {
"execution": {
"iopub.execute_input": "2024-03-09T13:26:46.875370Z",
"iopub.status.busy": "2024-03-09T13:26:46.874878Z",
"iopub.status.idle": "2024-03-09T13:26:47.577099Z",
"shell.execute_reply": "2024-03-09T13:26:47.576309Z"
},
"id": "YqSkt7l8ltwt"
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"\r",
" 0%| | 0/13 [00:00 |
"
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"# For gif format, set codec='gif'\n",
"media.show_video(plot_video, fps=3)"
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "LCImgZ3OdJw7"
},
"source": [
"## Resources\n",
"\n",
"The pretrained models are available from [TF Hub](https://tfhub.dev/google/collections/movinet/1). The TF Hub collection also includes quantized models optimized for [TFLite](https://tensorflow.org/lite).\n",
"\n",
"The source for these models is available in the [TensorFlow Model Garden](https://github.com/tensorflow/models/tree/master/official/projects/movinet). This includes a [longer version of this tutorial](https://colab.sandbox.google.com/github/tensorflow/models/blob/master/official/projects/movinet/movinet_tutorial.ipynb) that also covers building and fine-tuning a MoViNet model. "
]
},
{
"cell_type": "markdown",
"metadata": {
"id": "gh5lLAo-HpVF"
},
"source": [
"## Next Steps\n",
"\n",
"To learn more about working with video data in TensorFlow, check out the following tutorials:\n",
"\n",
"* [Load video data](https://www.tensorflow.org/tutorials/load_data/video)\n",
"* [Build a 3D CNN model for video classification](https://www.tensorflow.org/tutorials/video/video_classification)\n",
"* [Transfer learning for video classification with MoViNet](https://www.tensorflow.org/tutorials/video/transfer_learning_with_movinet)"
]
}
],
"metadata": {
"colab": {
"name": "movinet.ipynb",
"toc_visible": true
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.9.18"
}
},
"nbformat": 4,
"nbformat_minor": 0
}
 View on GitHub\n",
"
View on GitHub\n",
"