Open Images Challenge 2018 - object detection track - evaluation metric
The challenge uses a variant of the standard PASCAL VOC 2010 mean Average Precision (mAP) at IoU > 0.5. There are three key features of Open Images annotations, which are addressed by the new metric:
- Due to the Open Images annotation process, image-level labeling is not exhaustive.
- The object classes are organized in a semantic hierarchy, meaning that some categories are more general than others (e.g. 'Animal' is more general than 'Cat', as 'Cat' is a subclass of 'Animal').
- Some of the ground-truth bounding-boxes capture a group of objects, rather than a single object.
These differences affect the way True Positives and False Positives are accounted. In this document we say 'ground-truth box' to indicate an object bounding-box annotated in the ground-truth, and 'detection' to indicate a box output by the model to be evaluated.
Handling non-exhaustive image-level labeling
The images are annotated with positive image-level labels, indicating certain object classes are present, and with negative image-level labels, indicating certain classes are absent. All other classes are unannotated. For each positive image-level label in an image, every instance of that object class in that image is annotated with a ground-truth box.
For fair evaluation, all unannotated classes are excluded from evaluation in that image. If a detection has a class label unannotated on that image, it is ignored. Otherwise, it is evaluated as in the PASCAL VOC 2010 protocol. All detections with negative image labels are counted as false positives. Ground-truth boxes which capture a group of objects are evaluated slightly differently, as described below.
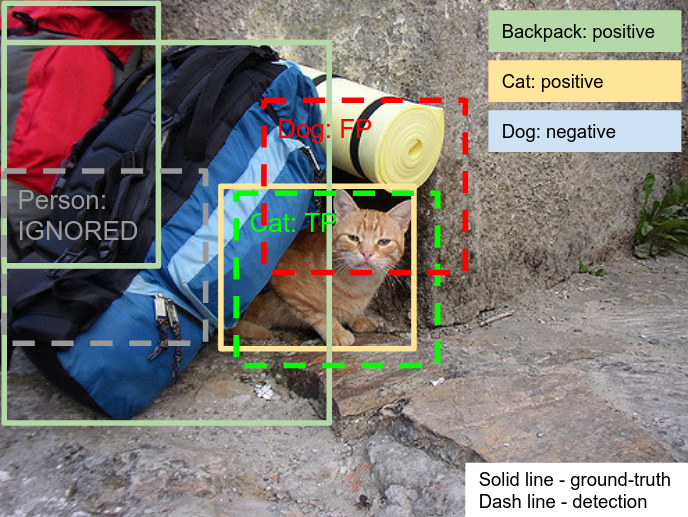
Labels hierarchy handling
AP (Average Precision) score is evaluated for each of the 500 classes of the Challenge. For a leaf class in the hierarchy, AP is computed as normally in PASCAL VOC 2010 (e.g. 'Football Helmet'). However, in order to be consistent with the meaning of a non-leaf class, its AP is computed involving all its ground-truth object instances and all instances of its subclasses.
For example, the class 'Helmet' has two subclasses ('Football Helmet' and 'Bicycle Helmet'). These subclasses in fact also belong to 'Helmet'. Hence, AP(Helmet) is computed by considering that the total set of positive 'Helmet' instances are the union of all objects annotated as 'Helmet', 'Football Helmet' and 'Bicycle Helmet' in the ground-truth. As a consequence, the participants are expected to produce a detection for each of the relevant classes, even if each detection corresponds to the same object instance. For example, if there is an instance of 'Football Helmet' in an image, the participants need to output detections for both 'Football Helmet' and for 'Helmet' in order to reach 100% recall (see semantic hierarchy visualization). If only a detection with 'Football Helmet' is produced, one True Positive is scored for 'Football Helmet' but the 'Helmet' instance will not be detected (False Negative). Note: the root 'Entity' class is not part of the challenge and thus is not evaluated.
The ground-truth files contain only leaf-most image-level labels and boxes. To produce ground-truth suitable for evaluating this metric correctly, please run the script from Tensorflow Object Detection API repository on both image-level labels csv file and boxes csv file.
Handling group-of boxes
A group-of box is a single box containing several object instances in a group (i.e. more than 5 instances which are occluding each other and are physically touching). The exact location of a single object inside the group is unknown.
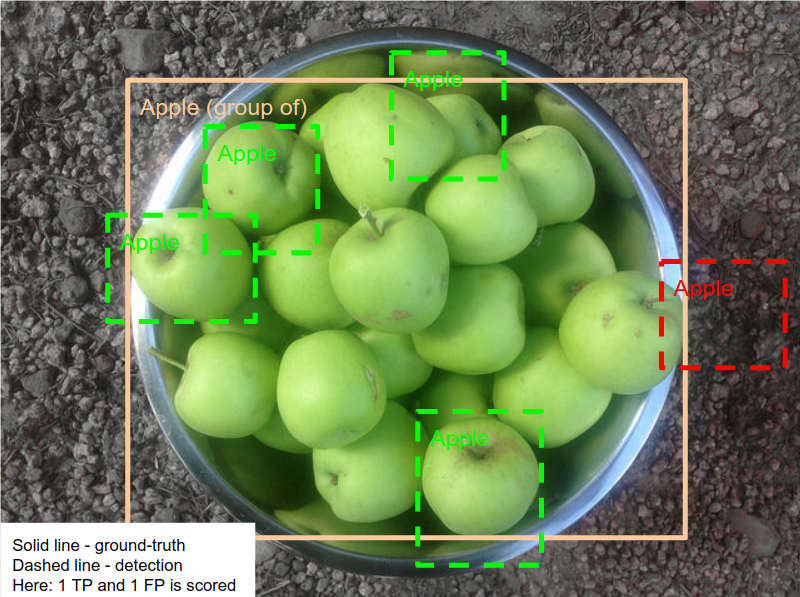
If at least one detection is inside group-of box a single True Positive is scored. Otherwise, the group-of box is counted as a single False Negative. A detection is inside a group-of box if the area of intersection of the detection and the box divided by the area of the detection is greater than 0.5. Multiple correct detections inside the same group-of box is still count as a single True Positive.
Aggregating AP over classes
The final mAP is computed as the average AP over the 500 classes of the challenge. The participants will be ranked on this final metric.
Metric implementation
The implementation this mAP variant is publicly available as part of the Tensorflow Object Detection API under the name 'OID Challenge Object Detection Metric 2018'.
Note: the Open Images V2 metric also included in the Object Detection API has different conventions and does not correspond to the official metric of the challenge.
Currently the metric can only be run as a part of Object Detection API framework this tutorial).
Please see this Tutorial on how to run the metric.
Results submission
The evaluation server is hosted by Kaggle.
Note: you need to be registered at Kaggle website for the competition to be able to submit the results. The registration deadline is August 23 2018.