Open Images Challenge 2019 was held in 2019. For the evaluation details and Open Images Challenge as a part of Robust Vision Challenge 2020 please refer to this page!
Overview of the Open Images Challenge 2019
Continuing the series of Open Images Challenges, the 2019 edition will be held at the International Conference on Computer Vision 2019. The challenge is based on the V5 release of the Open Images dataset. The images of the dataset are very varied and often contain complex scenes with several objects (explore the dataset). This year the Challenge will be again hosted by our partners at Kaggle.
The challenge has three tracks. Two tracks were introduced in the Challenge 2018:
- Object Detection: predicting a tight bounding box around all object instances of 500 classes.
- Visual Relationship Detection: detecting pairs of objects in particular relations.
For the 2019 edition we introduce a new instance segmentation track:
- [NEW] Instance Segmentation: predicting the outlines of object instances from 300 classes.
We hope that the very large and diverse training set will stimulate research into more advanced computer vision models that will exceed current state-of-the-art performance. For segmentation in particular, we collected extremely accurate ground-truth (for the validation and challenge sets) which rewards subtle improvements in the output segmentations, and thus might encourage the development of higher-quality models that deliver precise boundaries. Finally, having a single dataset with unified annotations for image classification, object detection, visual relationship detection, and instance segmentation will hopefully promote studying these tasks jointly and stimulate progress towards genuine scene understanding.
For historical reference, the website of the 2018 edition is available here.
Dates
- May 8th 2019: Training and validation sets for all tracks are released.
- June 3d 2019: Challenge set released by Kaggle (100k images). Evaluation server for the object detection and visual relationship detection tracks opens.
- July 12th 2019: Evaluation server for segmentation track opens.
- October 1st 2019: Evaluation servers for all tracks close.
- October 27th 2019: Open Images Workshop at ICCV 2019.
Workshop program
Evaluation servers for all three tracks of the challenge are officially closed. We congratulate the winners!
The workshop will take place on the 27th of October, in Seoul, South Korea.
Winners of the Object Detection track
| Rank | Team | Documents |
|---|---|---|
| 1 | MMFruit | method description presentation |
| 2 | imagesearch | method description |
| 3 | Prisms | method description presentation |
| 4 | PFDet | method description |
| 5 | Omni-Detection | method description poster |
Winners of the Visual Relationship Detection track
| Rank | Team | Documents |
|---|---|---|
| 1 | Layer6 AI | method description presentation poster |
| 2 | tito | method description |
| 3 | Very Random Team | method description presentation |
| 4 | [ods.ai] n01z3 | method description |
| 5 | Ode to the Goose | method description |
Winners of the Instance Segmentation track
| Rank | Team | Documents |
|---|---|---|
| 1 | MMFruit Seg | presentation |
| 2 | [ods.ai] n01z3 | method description presentation |
| 3 | PFDet | method description presentation |
| 4 | tito | method description |
| 5 | ZFTurbo & Weimin | method description |
Workshop schedule
| Time | Section |
|---|---|
| 13:30 - 13:40 | Overview of the Open Images Challenge [slides] |
| 13:40 - 14:00 | Object detection track - settings, metrics, winners, analysis, comparison to the previous year [slides] |
| 14:00 - 14:45 | Presentations by three winners of the Object detection track |
| 14:50 - 15:05 | Instance segmentation track - settings, metrics, winners, analysis NEW [slides] |
| 15:05 - 15:50 | Presentations by three winners of the Instance Segmentation track |
| 15:50 - 16:30 | Break and Poster session |
| 16:30 - 16:50 | Visual Relationship Detection track - settings, metrics, analysis, comparison to the previous year [slides] |
| 16:50 - 17:20 | Presentations by two winners of Visual Relationship Detection track |
| 17:25 - 17:30 | Concluding remarks [slides] |
Prizes
The Challenge has a total prize fund of 75,000 USD, equaly distributed between three tracks.
Evaluation servers
Evaluation servers for each track are hosted by Kaggle:
- Object Detection track Kaggle page.
- Visual Relationships Detection track Kaggle page.
- Instance Segmentation track Kaggle page.
Data and task description
The annotated data available for the participants is part of the Open Images V5 train and validation sets (reduced to the subset of classes covered in the Challenge, see below). The participants are recommended to use the training set provided on this page for traning models, and the validation set for validation. The Challenge set (100k images) with hidden annotations, on which participants are evaluated, is hosted by Kaggle. All tracks have the same Challenge set.
Note: the public leaderboard on the Kaggle website is the most reliable indicator of your performance, as it is based on images and annotations distributed identically to the hidden test set on which participants will be ranked for final evaluation. The validation set is also indicative of performance on the Challenge set, but is not exactly identically distributed. The best reference is the public leaderboard.
WARNING 1: Open Images V5 has a test set (with public annotations). This is NOT the same as the Challenge set (which has hidden annotations).
The statistics for each track are provided below. You can download all annotations, already reduced to the object classes covered in the Challenge, from this page. The python implementation of object detection and visual relationship detection evaluation protocols is released as a part of the Tensorflow Object Detection API.
We have annotated bounding boxes for human body parts only for 95,335 images in the training set, due to the overwhelming number of instances (see also the full description). You can use this list of images to make sure you use the data correctly during training (as there might be a positive image label for a human body part, and yet no boxes). Instead, on the validation and Challenge sets, we annotated human body parts on all images for which we have a positive label.
Object detection track


The Object Detection track is very similar to the 2018 edition of the Challenge. It covers 500 classes out of the 600 annotated with bounding boxes in Open Images V5. We removed some very broad classes (e.g. "clothing") and some infrequent ones (e.g. "paper cutter"). For the Challenge 2019 we recommend using the official validation set to set model hyper-parameters, as the version from Open Images V5 is now annotated the same density level as the training set.
The evaluation metric is mean Average Precision (mAP) over the 500 classes. The images are annotated with positive image-level labels, indicating certain object classes are present, and with negative image-level labels, indicating certain classes are absent. All other unannotated classes are excluded from evaluation in that image. Thus participants are not penalized for producing false-positives on unannotated classes. For each positive image-level label in an image, we have exhaustively annotated every instance of that object class in the image. This enables to accurately measure recall. Please read the V5 description for more details on the data. Note, that these negative labels are all reliable and can be used during training, e.g. for hard-negative mining which is important when training object detectors.
The classes are organized in a semantic hierarchy. The evaluation metric properly takes this into account, by integrating object instances upwards along the hierarchy. The detailed object detection metric protocol is explained here.
Table 1: Object Detection track annotations on training set.
| Image-Level Labels | Bounding boxes | |
|---|---|---|
| Train | 5,743,460 | 12,195,144 |
| Validation | 193,300 | 226,811 |
Instance segmentation track


The instance segmentation track is new for the 2019 edition of the Challenge. This track covers 300 classes out of the 350 annotated with segmentation masks in Open Images V5. We selected these 300 classes based on their frequency in the various splits of the dataset (see Table 2 for details).
The training set of Open Images V5 contains 2.1Mio segmentation masks for these 300 classes. These have been produced by an interactive segmentation process and are accurate (mIoU 84%). Additionally, Open Images V5 also has a validation set with 23K masks for these 300 classes. These have been annotated purely manually with a strong focus on quality. They are near-perfect and capture even fine details of complex object boundaries, and hence are well suited for evaluating segmentation models. Please read the V5 description for more details on the data.
Table 2: Instance segmentation track annotations on training set.
| Image-Level Labels | Bounding boxes | Masks | |
|---|---|---|---|
| Train | 2,987,501 | 5,984,294 | 2,125,530 |
| Validation | 84,348 | 101,943 | 23,366 |
Participants will be evaluated on the Challenge set (same for all tracks, see above).The evaluation set has been annotated with high-quality masks of the same kind as available on the validation set (up to 1000 per class). During evaluation, the box annotations are also used to ignore masks over instances without a corresponding mask annotation.
The evaluation metric computes mean AP (mAP) using mask-to-mask matching over the 300 classes (also organized into a semantic hierarchy). The evaluation metric is described in detail here.
We emphasize that the images are annotated both human-verified positive and negative labels. The negative image-level labels can be used during training of segmentation models, e.g. for hard-negative mining. Moreover, we use them during evaluation to measure performance fairly.
Visual relationship detection track

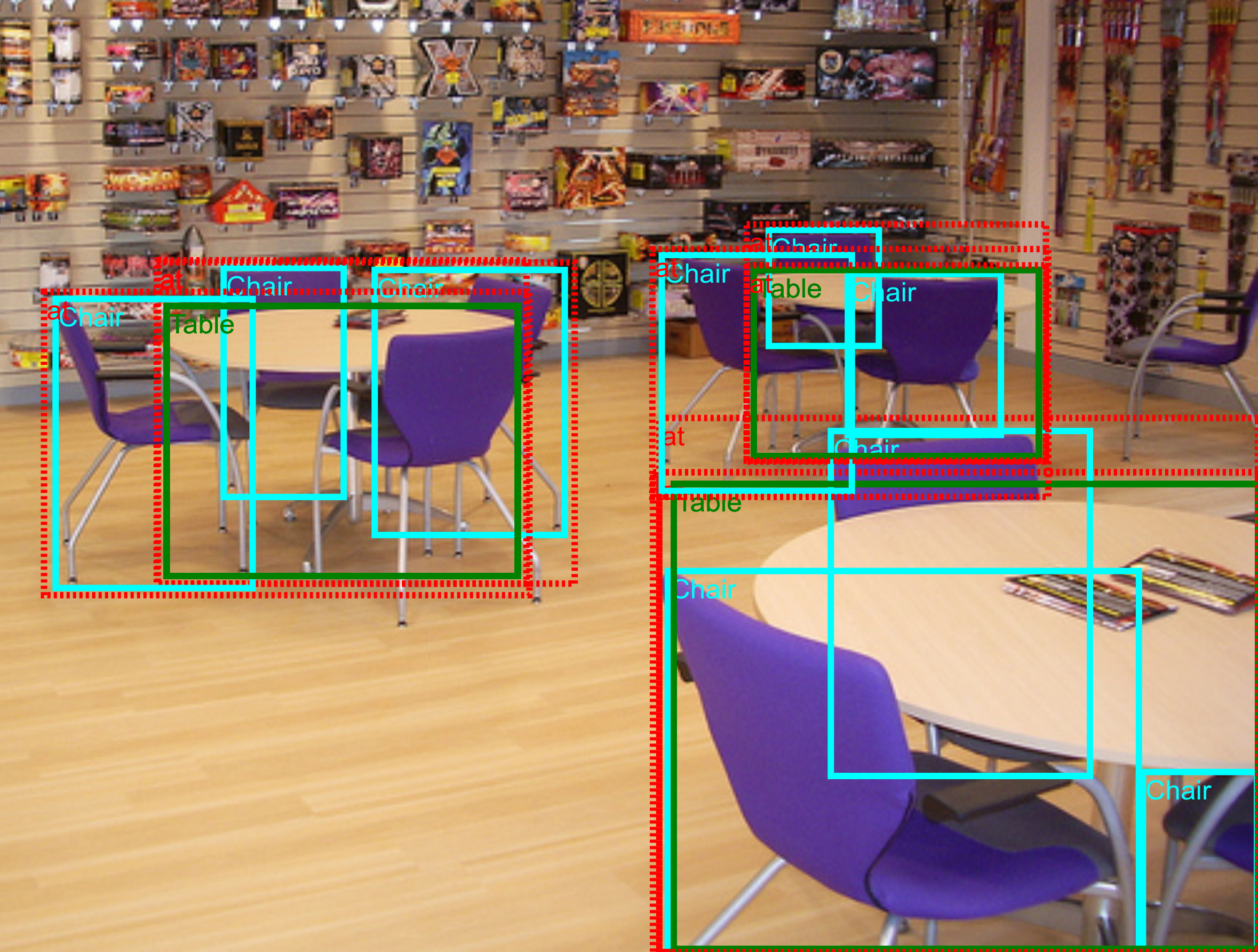
The Visual Relationships Detection track is very similar to the 2018 edition of the Challenge. It requires detecting relationships connecting two objects. These include both human-object relationships (e.g. "woman playing guitar", "man holding microphone") and object-object relationships (e.g. "beer on table", "dog inside car"). Each relationship connects different pairs of objects, e.g. "woman playing guitar","man playing drum". Finally, this track also consider object-attribute relationships (e.g."handbag is made of leather" and "bench is wooden").
In our notation, a pair of objects connected by a relationship forms a triplet (e.g. "beer on table"). Visual attributes are in fact also triplets, where an object in connected with an attribute using the relationship is (e.g. "table is wooden"). The annotations are based on the image-level labels and bounding box annotations of Open Images V5. We initially selected 467 possible triplets and annotated them on the training set of Open Images V5. The 329 of them that have at least one instance in the training set form the final set of triplets for the Visual Relationships Detection track. Those involve 57 different object classes and 5 attributes.
The statistics on the number of relationships, classes and attributes are given in Table 3.
Table 3: Visual Relationships Detection metadata information.
| Classes | Relationships | Visual attributes | Distinct relationship triplets | |
|---|---|---|---|---|
| Relationships connecting two objects | 57 | 9 | - | 287 |
| Relationship "is" (visual attributes) | 23 | 1 | 5 | 42 |
| Total | 57 | 10 | 5 | 329 |
For each image that can potentially contain a relationship triplet (i.e. contains the objects involved in that triplet), we provide annotations exhaustively listing all positive triplets instances in that image. For example, for "woman playing guitar" in an image, we list all pairs of ("woman","guitar") that are in the relationship "playing" in that image. All other pairs of (woman,guitar) in that image are negative examples for the "playing" relationship. We also separatelly provide all bounding boxes for the 57 object classes involved in this track. This enables participants to construct negative sample triplets. Detailed statistics of the annotations are given in Table 4.
Table 4: Visual Relationships Detection track annotations on training and validation sets.
| Bounding boxes | Image-level Labels | Positive relationship triplets | |
|---|---|---|---|
| Train | 3,290,070 | 1,803,311 | 374,768 |
| Validation | 36,982 | 31,554 | 3,991 |
We emphasize that the images are annotated both human-verified positive and negative labels. Importantly, the negative image-level labels can be used during training of visual relationship detectors: if any of the two object classes in a relationship triplet is marked as a negative label in our ground-truth, then all detections of that triplet are false-positives.
For the Challenge 2019 we have added relationship annotations on the validation set of Open Images, generated in the same manner as for the training split. Participants can use this validation set to tune model hyper-parameters.
For evaluation on the Challenge set, we will use mean Average Precision (mAP) and retrieval metrics on phrase detection and relationship detection tasks. The winner will be determined by ranking the participants based on their performance on each metric. The detailed evaluation protocol is explained here.
The python implementation of all evaluation protocols is released as a part of Tensorflow Object Detection API.
Contacts
For challenge-related questions please contact oid-challenge-contact. To receive news about the challenge and the Open Images dataset, subscribe to Open Images newsletter here.
Organizers
- Vittorio Ferrari, Google AI.
- Alina Kuznetsova, Google AI.
- Rodrigo Benenson, Google AI.
- Victor Gomes, Google AI.
- Matteo Malloci, Google AI.