Open Images Challenge 2018 was held in 2018. For the OI Challenge 2019 please refer to this page!
Overview of the Open Images Challenge 2018
The Open Images Challenge 2018 is a new object detection challenge to be held at the European Conference on Computer Vision 2018. The challenge follows in the tradition of PASCAL VOC, ImageNet and COCO, but at an unprecedented scale. The boxes have been largely manually drawn by professional annotators to ensure accuracy and consistency. The images are very varied and often contain complex scenes with several objects (7 per image on average; explore the dataset). The Open Images Challenge offers a broader range of object classes than previous challenges, including new objects such as "fedora" and "snowman". The Challenge is hosted by Kaggle.
The challenge has two tracks:
- Object Detection: predicting a tight bounding box around all instances of the 500 classes.
- Visual Relationship Detection: detecting pairs of objects in particular relations, e.g. "woman playing guitar".
We hope that the very large training set will stimulate research into more sophisticated detection models that will exceed current state-of-the-art performance. Moreover, having 500 object classes will enable assessing more precisely in which situations different detectors work best. Finally, having a large set of images with many objects annotated enables to explore Visual Relationship Detection, which is a hot emerging topic with a growing sub-community.
Dates
- April 30th 2018: training set for object detection track released (with bounding box annotations).
- May 10 2018: visual relationship detection annotations on the training set is released.
- May 31 2018: evaluation metric protocols and implementation is released (as a part of the TF Object Detection API).
- July 3st 2018: a test set released by Kaggle and Kaggle Object Detection Track evaluation server is up.
- July 11th 2018: Kaggle Visual Relationship Detection Track evaluation server is up.
- August 23 2018: registration for the competition on Kaggle website deadline.
- August 30 2018: evaluation servers close.
- September 8 2018: Open Images Challenge Workshop held in conjunction with ECCV 2018.
Workshop program
We congratulate the winners!
Winners of the Object Detection track
| Rank | Team | Documents |
|---|---|---|
| 1 | kivajok, Baidu | [method description] |
| 2 | PFDet, Preferred Networks | [slides][poster][method description] |
| 3 | Avengers, Baidu | [slides][method description] |
Winners of the Visual Relationship Detection track
| Rank | Team | Documents |
|---|---|---|
| 1 | Seiji, Rutgers University, NVidia | [slides][method description] |
| 2 | tito, no affiliation | [method description] |
| 3 | Kyle, no affiliation | undisclosed |
| 4 | toshif, no affiliation | [method description] |
Posters
6 teams presented a poster at the Open Images Challenge Workshop at ECCV 2018:
| Track | Team | Poster |
|---|---|---|
| OD | StyriaAI, Styria | link |
| OD | PFDet, Preferred Networks | link |
| OD | ICantFeelMyFace, undisclosed | link |
| VRD | VRD_NN, Amazon | link |
| VRD | mission_pipeline, Huazhong University of Science and Technology, Jiangsu University, Alibaba Group | link |
| VRD | MIL, The University of Tokyo, IIT Hyderabad, RIKEN | link |
Presented posters for both tracks can be also downloaded here.
Invited speaker:

Workshop schedule
| Time | Section |
|---|---|
| 13:30 - 13:50 | Overview of Open Images and the challenge [slides] |
| 13:50 - 14:10 | Object Detection track - settings, metrics, winners, analysis [slides] |
| 14:10 - 15:00 | Presentations by three selected Object Detection track participants |
| 15:00 - 15:40 | Keynote: Devi Parikh Title: "A-STAR: Towards Agents that See, Talk, Act, and Reason" |
| 15:40 - 16:20 | Break and Poster session |
| 16:20 - 16:40 | Visual Relationship Detection track - settings metrics, winners, analysis [slides] |
| 16:40 - 17:10 | Presentations by two selected Visual Relationship Detection track participants |
| 17:10 - 17:20 | Concluding remarks and plans for future of Open Images [slides] |
Results submission
The test set (100k images) and the evaluation servers are hosted by Kaggle.
Explore the training set
You can browse the training set with bounding box annotations and visual relationships annotations overlaid in this visualizer.
Object Detection Track


The Challenge is based on Open Images V4. The Object Detection track covers 500 classes out of the 600 annotated with bounding boxes in Open Images V4. We removed some very broad classes (e.g. "clothing") and some infrequent ones (e.g. "paper cutter").
The evaluation metric is mean Average Precision (mAP) over the 500 classes. The images are annotated with positive image-level labels, indicating certain object classes are present, and with negative image-level labels, indicating certain classes are absent. All other unannotated classes are excluded from evaluation in that image. Thus participants are not penalized for producing false-positives on unannotated classes. For each positive image-level label in an image, we have exhaustively annotated every instance of that object class in the image. This enables to accurately measure recall. Please read the V4 description for more details on the data.
The classes are organized in a semantic hierarchy (visualization). The evaluation metric properly takes this into account, by integrating object instances upwards along the hierarchy. Detailed object detection metric protocol is explained here.
The Kaggle evaluation server for the Object Detection Track is available here.
Table 1: Object Detection track annotations on training set.
| Classes | Images | Image-Level Labels | Bounding boxes | |
|---|---|---|---|---|
| Train | 500 | 1,743,042 | 5,743,460 pos: 3,830,005 neg: 1,913,455 |
12,195,144 |
Visual Relationship Detection Track

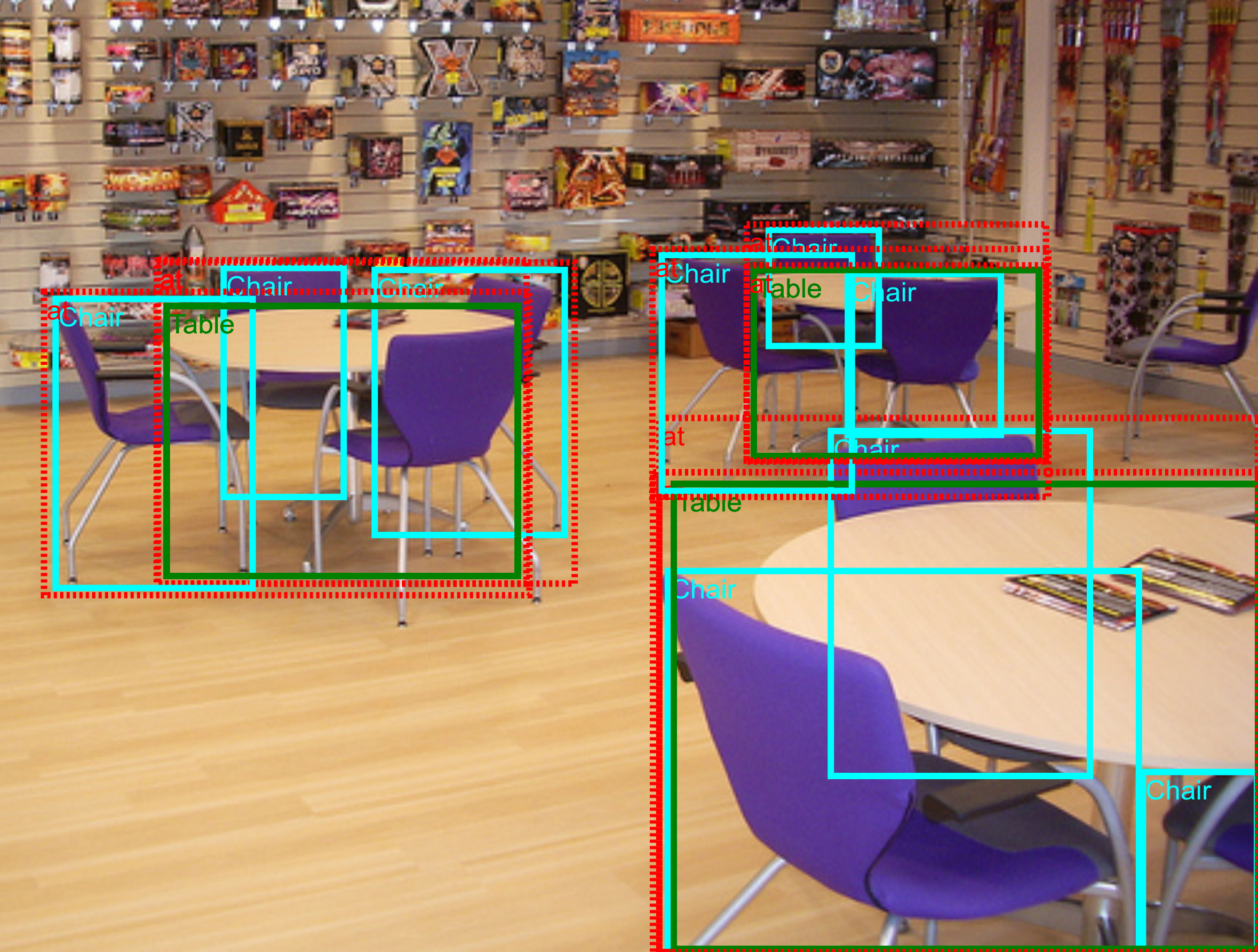
In our notation, a pair of objects connected by a relationship forms a triplet (e.g. "beer on table"). Visual attributes are in fact also triplets, where an object in connected with an attribute using the relationship is (e.g. "table is wooden"). The annotations are based on the image-level labels and bounding box annotations of Open Images V4. We initially selected 467 possible triplets and annotated them on the training set of Open Images V4. The 329 of them that have at least one instance in the training set form the final set of triplets for the Visual Relationships Detection track. Those involve 57 different object classes and 5 attributes.
The statistics on the number of relationships, classes and attributes are given in Table 2.
Table 2: Visual Relationships Detection metadata information.
| Classes | Relationships | Visual attributes | Distinct relationship triplets | |
|---|---|---|---|---|
| Relationships connecting two objects | 57 | 9 | - | 287 |
| Relationship "is" (visual attributes) | 23 | 1 | 5 | 42 |
| Total | 57 | 10 | 5 | 329 |
For each image that can potentially contain a relationship triplet (i.e. contains the objects involved in that triplet), we provide annotations exhaustively listing all positive triplets instances in that image. For example, for "woman playing guitar" in an image, we list all pairs of ("woman","guitar") that are in the relationship "playing" in that image. All other pairs of (woman,guitar) in that image are negative examples for the "playing" relationship. We also separatelly provide all bounding boxes for the 57 object classes involved in this track. This enables participants to construct negative sample triplets. Detailed statistics of the annotations are given in Table 3.
Table 3: Visual Relationships Detection track annotations on training set.
| Positive relationship triplets | Bounding boxes | Image-level Labels | |
|---|---|---|---|
| Train | 374,768 | 3,290,070 | 2,077,154 |
For evaluation mean Average Precision (mAP) and retrieval metrics on phrase detection and relationship detection tasks is used. The winner will be determined by ranking the participants based on their performance on each metric. Detailed evaluation protocol is explained here.
The Kaggle evaluation server for the Visual Relationship Detection Track is available here.
The python implementation of both evaluation protocols is released as a part of Tensorflow Object Detection API.
Prize money
The Challenge has a total prize fund of USD 50,000, sponsored by Google.
Downloads
Object Detection track
All images and annotations are a subset of Open Images V4 training set, restricted to the 500 object classes of the challenge. We provide bounding box annotations and image-level annotations (both positive and negative).
Trouble downloading the pixels? Let us know.
We recommend participants to use the provided subset of the training set as a validation set. This is preferable over using the V4 val/test sets, as the training set is more densely annotated.
Note: By design, the recommended validation subset contains images negatively annotated, which don't have a corresponding entry in the annotations file.
Please read the V4 download page for a description of file formats.
Visual Relationships Detection track
See above for a description.
Participants should use the provided subset of the training set as the validation set. The Open Images V4 validation and test sets do not contain relationship annotations.
The description of visual relationships annotations format is provided below. Please read the V4 download page for a description of other file formats.
Visual relationship triplets annotations format
Each row in the file corresponds to a single annotation.
ImageID,LabelName1,LabelName2,XMin1,XMax1,YMin1,YMax1,XMin2,XMax2,YMin2,YMax2,RelationLabel
0009fde62ded08a6,/m/0342h,/m/01d380,0.2682927,0.78549093,0.4977778,0.8288889,0.2682927,0.78549093,0.4977778,0.8288889,is
00198353ef684011,/m/01mzpv,/m/04bcr3,0.23779725,0.30162704,0.6500938,0.7335835,0,0.5819775,0.6482176,0.99906194,at
001e341dd7456c72,/m/04yx4,/m/01mzpv,0.07009346,0.2859813,0.2332708,0.5203252,0.14018692,0.31588784,0.32082552,0.48405254,on
001e341dd7456c72,/m/04yx4,/m/01mzpv,0,0.28317758,0.26454034,0.5540963,0.2224299,0.3411215,0.3908693,0.4859287,on
001e341dd7456c72,/m/01599,/m/04bcr3,0.5551402,0.6084112,0.50343966,0.5490932,0.5411215,0.95981306,0.5090682,0.78361475,on
001e341dd7456c72,/m/04bcr3,/m/01d380,0.7392523,0.9990654,0.3889931,0.518449,0.7392523,0.9990654,0.3889931,0.518449,is
...
ImageID: the image this relationship instance lives in.
LabelName1: the label of the first object in the relationship triplet.
XMin1,XMax1,YMin1,YMax1: normalized bounding box coordinates of the bounding box of the first object.
LabelName2: the label of the second object in the relationship triplet, or an attribute.
XMin2,XMax2,YMin2,YMax2: If the relationship is between a pair of objects: normalized bounding box coordinates of the bounding box of the second object. For an object-attribute relationship (RelationLabel="is"): normalized bounding box of the first object (repeated). In this case, LabelName2 is an attribute.
RelationLabel: the label of the relationship ("is" in case of attributes).
Contacts
For challenge-related questions please contact oid-challenge2018-contact. To receive news about the challenge and the Open Images dataset, subscribe to Open Images newsletter here.
Organizers
- Vittorio Ferrari, Google AI.
- Alina Kuznetsova, Google AI.
- Jordi Pont-Tuset, Google AI.
- Matteo Malloci, Google AI.
- Jasper Uijlings, Google AI.
- Jake Walker, Google AI.
- Rodrigo Benenson, Google AI.