Open Images Challenge object detection evaluation
The challenge uses a variant of the standard PASCAL VOC 2010 mean Average Precision (mAP) at IoU > 0.5. There are three key features of Open Images annotations, which are addressed by the new metric:
- Due to the Open Images annotation process, image-level labeling is not exhaustive.
- The object classes are organized in a semantic hierarchy, meaning that some categories are more general than others (e.g. 'Animal' is more general than 'Cat', as 'Cat' is a subclass of 'Animal').
- Some of the ground-truth bounding-boxes capture a group of objects, rather than a single object.
These differences affect the way True Positives and False Positives are accounted. In this document we say 'ground-truth box' to indicate an object bounding-box annotated in the ground-truth, and 'detection' to indicate a box output by the model to be evaluated.
Handling non-exhaustive image-level labeling
The images are annotated with positive image-level labels, indicating certain object classes are present, and with negative image-level labels, indicating certain classes are absent. All other classes are unannotated. For each positive image-level label in an image, every instance of that object class in that image is annotated with a ground-truth box.
For fair evaluation, all unannotated classes are excluded from evaluation in that image. If a detection has a class label unannotated on that image, it is ignored. Otherwise, it is evaluated as in the PASCAL VOC 2010 protocol. All detections with negative image labels are counted as false positives. Ground-truth boxes which capture a group of objects are evaluated slightly differently, as described below.
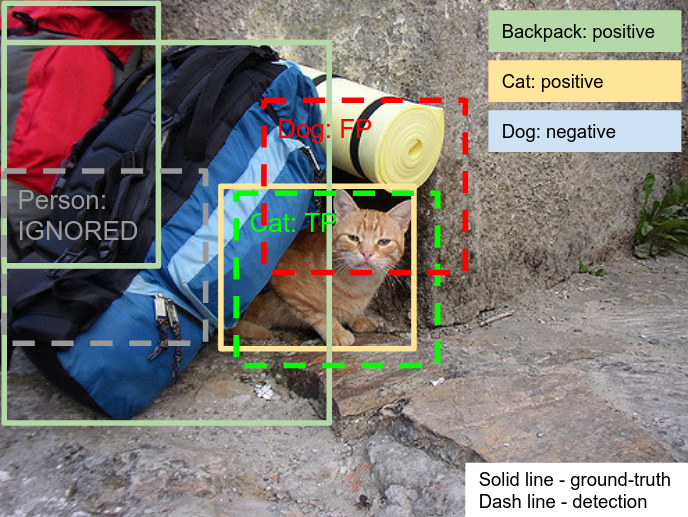
Labels hierarchy handling
AP (Average Precision) score is evaluated for each of the 500 classes of the Challenge. For a leaf class in the hierarchy, AP is computed as normally in PASCAL VOC 2010 (e.g. 'Football Helmet'). However, in order to be consistent with the meaning of a non-leaf class, its AP is computed involving all its ground-truth object instances and all instances of its subclasses.
For example, the class 'Helmet' has two subclasses ('Football Helmet' and 'Bicycle Helmet'). These subclasses in fact also belong to 'Helmet'. Hence, AP(Helmet) is computed by considering that the total set of positive 'Helmet' instances are the union of all objects annotated as 'Helmet', 'Football Helmet' and 'Bicycle Helmet' in the ground-truth. As a consequence, the participants are expected to produce a detection for each of the relevant classes, even if each detection corresponds to the same object instance. For example, if there is an instance of 'Football Helmet' in an image, the participants need to output detections for both 'Football Helmet' and for 'Helmet' in order to reach 100% recall (see semantic hierarchy visualization). If only a detection with 'Football Helmet' is produced, one True Positive is scored for 'Football Helmet' but the 'Helmet' instance will not be detected (False Negative). Note: the root 'Entity' class is not part of the challenge and thus is not evaluated.
The ground-truth files contain only leaf-most image-level labels and boxes. To produce ground-truth suitable for evaluating this metric correctly using the Tensorflow Object Detection API, please run the script on both image-level labels csv file and boxes csv file. Using FiftyOne (see below), the expansion is done automatically when computing the metric.
Handling group-of boxes
A group-of box is a single box containing several object instances in a group (i.e. more than 5 instances which are occluding each other and are physically touching). The exact location of a single object inside the group is unknown.
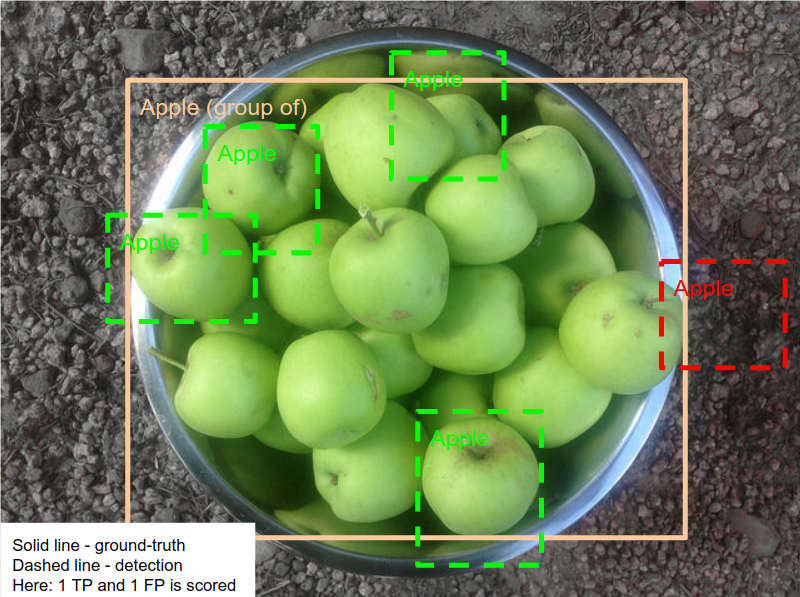
If at least one detection is inside group-of box a single True Positive is scored. Otherwise, the group-of box is counted as a single False Negative. A detection is inside a group-of box if the area of intersection of the detection and the box divided by the area of the detection is greater than 0.5. Multiple correct detections inside the same group-of box is still count as a single True Positive.
Aggregating AP over classes
The final mAP is computed as the average AP over the 500 classes of the challenge. The participants will be ranked on this final metric.
Metric implementation
The implementation of this mAP variant is publicly available through the open-source tool FiftyOne as well as through the Tensorflow Object Detection API under the name 'OID Challenge Object Detection Metric'.
FiftyOne
FiftyOne provides Open Images-style object detection evaluation to not only compute mAP but also easily visualize individual sample- and object-level results, view precision-recall curves, and plot interactive confusion matrices.
Please see this Tutorial on how to run the metric.
Tensorflow Object Detection API
To obtain the evaluation results with the Tensorflow Object Detection API, use oid_od_challenge_evaluation.py util. Please see this Tutorial on how to run the metric.
Note: the Open Images V2 metric also included in the Object Detection API has different conventions and does not correspond to the official metric of the challenge.
Open Images Challenge instance segmentation evaluation
The metric for the instance segmentation part of the challenge is similar in spirit to the Object Detection metric. It is computed as the mean Average Precision (mAP) at mask-to-mask IoU > 0.5 across 300 classes of the challenge.
Like the object detection case, the mean Average Precision relies on the count of True Positives and False Positives, at a given detection score threshold. As before, the metric needs to handle non-exhaustive image-level labeling, and the semantic hierarchy of object classes. Both cases are handled as in the object detection case.
The presence of group-of boxes, however, is handled differently, and this case additionally needs to handle ground-truth object boxes without corresponding instance masks, both detailed below.
Handling non-exhaustive masks labeling and group-of boxes
In this track all detections under evaluation consist of a mask with class-label and detection score. The detection masks can be trivially converted to detection bounding boxes, used match to ground-truth boxes in steps 2 and 3 below. Not all ground-truth object boxes have a corresponding instance mask because an object might be considered too small to annotate, the annotator might have considered its mask was ill-defined, or because the number of instances in the class was capped.
 _Example annotations. Four image-level labels, two positive and two negative.
For "person" class three instances have a mask, and one does not._
_Example annotations. Four image-level labels, two positive and two negative.
For "person" class three instances have a mask, and one does not._
For each image, detections for classes with a negative image-level label, are automatically considered False Positives. Detections for missing image-level labels are ignored (see "Handling non-exhaustive image-level labeling" above). Detections for classes with a positive image-level label are evaluated in more detail to find the True/False Positive/Negatives.
For each image:
- First, all detection masks are matched to all existing ground-truth masks. Two masks are considered as a potential match if mask-to-mask IoU > 0.5. Matched detections are considered True Positives.
- The remaining unmatched detections are now matched with ground-truth boxes that do not have a corresponding mask and that are not marked as group-of. Two such boxes are considered a potential match if box-to-box IoU > 0.5. Matched detections are ignored. These are probably true detections, but no ground-truth mask is available to evaluate in detail.
- The remaining unmatched detections are finally matched to ground-truth group-of boxes. Two such boxes are considered a potential match if box-to-box intersection over area > 0.5 (like in the object detection case, multiple detections can match the same group-of box). Matched detections are ignored. The remaining non-matched detections do not match any mask nor box, and are thus considered False Positives.
After this three-stage matching all detections have been tagged as True Positive, False Positive or to be ignored, and precision/recall values can be computed to generate per-class AP values.
Aggregating AP over classes
The overall mAP is computed as the average AP over the 300 classes of the challenge. The participants will be ranked on this final metric.
Metric implementation
The implementation of this mAP variant will be publicly available as part of the Tensorflow Object Detection API under the name 'OID Challenge Instance Segmentation Metric'. To obtain the evaluation results, use oid_challenge_evaluation.py util. Please see this Tutorial on how to run the metric. All utils will be available on the 1st of July.
Open Images Challenge Visual Relationships Detection evaluation
For the Visual Relationships Detection track, we use two tasks: relationship detection and phrase detection. In the relationship detection task, the expected output is two object detections with their correct class labels, and the label of the relationship that connects them (for the object-is-attribute case, the two boxes are identical). In the phrase detection task, the expected output is a single detection enclosing both objects, two object labels and one relationship label. Let Intersection-over-Union (IoU) threshold = 0.5. The participants will be evaluated on the weighted sum of the following metrics:
- Mean Average Precision of relationships detection at IoU > threshold (mAPrel).
- Recall@N of relationships detection at IoU > threshold (Recall@Nrel).
- Mean Average Precision of phrase detection at IoU > threshold (mAPphrase).
All three metrics were used for the evaluation of Visual Relationships Detection in previous works. However, the performance of the state-of-the-art algorithms in relationships detection rask is still very low (due to the difficulty of the task), so we decided to introduce additional retrieval metric of Recall@N for the relationships detection. Note that phrase detection is more tractable, so using mAP is sufficient. Note that group-of boxes and hierarchy effects are not taken into account during evaluation.
mAPrel in relationships detection
For each relationship type (e.g. 'at', 'on') Average Precision (AP) is computed by extending the PASCAL VOC 2010 definition to relationship triplets. The main modification is that a matching criteria must apply on the two object boxes and three class labels (two object labels and a relationship label). We consider a detected triplet to be a True Positive (TP) if and only if both object boxes have IoU > threshold with a previously undetected ground-truth annotation, and all three labels match their corresponding ground-truth labels. Any other detection is considered a False Positive (FP) in the two cases (1) both class labels of the objects are annotated in that image (regardless of positive or negative); or (2) one or both labels are annotated as negative. Finally, if either of the labels is unannotated, the detection is not evaluated (ignored). mAPrel is computed as the average of per-relationship APs.
Recall@Nrel in relationships detection
The triplet detections are sorted by score and then the top N predictions are evaluated as TP, FP or ignored (see above). A recall point is scored if there is at least one True Positive is found among these top N detections.
mAPphrase in phrase detection
Each relationship detection triplet is transformed so that a single enclosing bounding box is formed from the two object detections. This bounding box has three labels attached (two object labels and one relationship label). The enclosing box is considered to be a TP if IoU > threshold with a previously undetected ground-truth annotation and all three labels match their corresponding ground-truth labels. The AP for each relationship type is computed according to the PASCAL VOC 2010 definition. mAPphrase is computed as the average of per-relationship APs.
Metric implementation
The implementation of these metrics is publicly available as part of the Tensorflow Object Detection API under the name 'OID Challenge Visual Relationship Detection Metric'. The software provides several diagnostic metrics (as per-class AP), however those metrics will not be used for the final ranking.
To obtain the evaluation results, use oid_vrd_challenge_evaluation.py util.
Please see this Tutorial on how to run the metric.