If you would like to view the description of another version, please select it here:
Overview of Open Images V5
Open Images is a dataset of ~9M images annotated with image-level labels, object bounding boxes, object segmentation masks, and visual relationships. It contains a total of 16M bounding boxes for 600 object classes on 1.9M images, making it the largest existing dataset with object location annotations. The boxes have been largely manually drawn by professional annotators to ensure accuracy and consistency. The images are very diverse and often contain complex scenes with several objects (8.3 per image on average). Open Images also offers visual relationship annotations, indicating pairs of objects in particular relations (e.g. "woman playing guitar", "beer on table"). In total it has 329 relationship triplets with 391,073 samples. In V5 we added segmentation masks for 2.8M object instances in 350 classes. Segmentation masks mark the outline of objects, which characterizes their spatial extent to a much higher level of detail. Finally, the dataset is annotated with 36.5M image-level labels spanning 19,969 classes.
We believe that having a single dataset with unified annotations for image classification, object detection, visual relationship detection, and instance segmentation will enable to study these tasks jointly and stimulate progress towards genuine scene understanding.
Complexity and Diversity

The plots above show the distributions of object centers in normalized image coordinates for various sets of Open Images and other related datasets. The Open Images Train set, which contains most of the data, and Challenge sets show a rich and diverse distribution of a complexity in a similar ballpark to the COCO dataset. This is also confirmed when considering the number of objects per image and their area distribution (plots below). While we have improved the density of annotation in the smaller validation and test sets from V4 to V5, their center distribution is simpler and closer to PASCAL 2012. We recommend users to report results on the Challenge set, which offers the hardest performance test for object detectors. We thank Ross Girshick for suggesting this type of visualizations and for correcting the figure in their LVIS paper, which displayed a plot for the validation set without knowing that it was not representative of the whole dataset, and included an intensity scaling artifact that exaggerated its peakiness.

Number of objects per image (left) and object area (right) for Open Images V5/V4 and other related datasets (training sets in all cases).
Open Images Extended
Open Images Extended is a collection of sets that complement the core Open Images Dataset with additional images and/or annotations. You can read more about this in the Extended section. The rest of this page describes the core Open Images Dataset, without Extensions.
Publications
The following paper describes Open Images V4 in depth: from the data collection and annotation to detailed statistics about the data and evaluation of models trained on it. If you use the Open Images dataset in your work (also V5), please cite this article.

|
A. Kuznetsova, H. Rom, N. Alldrin, J. Uijlings, I. Krasin, J. Pont-Tuset, S. Kamali, S. Popov, M. Malloci, T. Duerig, and V. Ferrari. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv:1811.00982, 2018. [PDF] [BibTeX] |
@article{OpenImages,
author = {Alina Kuznetsova and Hassan Rom and Neil Alldrin and Jasper Uijlings and Ivan Krasin and Jordi Pont-Tuset and Shahab Kamali and Stefan Popov and Matteo Malloci and Tom Duerig and Vittorio Ferrari},
title = {The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale},
year = {2018},
journal = {arXiv:1811.00982}
}
The next paper describes the technique used to annotate instance segmentations in Open Images. If you use the segmentations, please cite this article too.

|
R. Benenson, S. Popov, and V. Ferrari. Large-scale interactive object segmentation with human annotators. CVPR, 2019. [PDF] [BibTeX] |
@inproceedings{OpenImagesSegmentation,
author = {Rodrigo Benenson and Stefan Popov and Vittorio Ferrari},
title = {Large-scale interactive object segmentation with human annotators},
booktitle = {CVPR},
year = {2019}
}
Please also consider citing this general reference to the dataset:
|
Krasin I., Duerig T., Alldrin N., Ferrari V., Abu-El-Haija S., Kuznetsova A., Rom H., Uijlings J., Popov S., Kamali S., Malloci M., Pont-Tuset J., Veit A., Belongie S., Gomes V., Gupta A., Sun C., Chechik G., Cai D., Feng Z., Narayanan D., Murphy K. OpenImages: A public dataset for large-scale multi-label and multi-class image classification, 2017. Available from https://storage.googleapis.com/openimages/web/index.html. [BibTeX] |
@article{OpenImages2,
title={OpenImages: A public dataset for large-scale multi-label and multi-class image classification.},
author={Krasin, Ivan and Duerig, Tom and Alldrin, Neil and Ferrari, Vittorio and Abu-El-Haija, Sami and Kuznetsova, Alina and Rom, Hassan and Uijlings, Jasper and Popov, Stefan and Kamali, Shahab and Malloci, Matteo and Pont-Tuset, Jordi and Veit, Andreas and Belongie, Serge and Gomes, Victor and Gupta, Abhinav and Sun, Chen and Chechik, Gal and Cai, David and Feng, Zheyun and Narayanan, Dhyanesh and Murphy, Kevin},
journal={Dataset available from https://storage.googleapis.com/openimages/web/index.html},
year={2017}
}
Data organization
The dataset is split into a training set (9,011,219 images), a validation set (41,620 images), and a test set (125,436 images). The images are annotated with image-level labels, object bounding boxes, object segmentation masks, and visual relationships as described below.
Image-level labels
Table 1 shows an overview of the image-level labels in all splits of the dataset. All images have machine generated image-level labels automatically generated by a computer vision model similar to Google Cloud Vision API; additionally, the vision model has been upgraded for improved label quality in the V5 dataset release. These automatically generated labels have a substantial false positive rate.
Table 1: Image-level labels.
| Train | Validation | Test | # Classes | # Trainable Classes | |
|---|---|---|---|---|---|
| Images | 9,011,219 | 41,620 | 125,436 | - | - |
| Machine-Generated Labels | 164,819,642 | 681,179 | 2,061,177 | 15,387 | 8,386 |
| Human-Verified Labels | 34,069,338 pos: 15,273,617 neg: 18,795,721 |
595,339 pos: 367,263 neg: 228,076 |
1,799,883 pos: 1,110,124 neg: 689,759 |
19,943 | 8,658 |
Moreover, the validation and test sets, as well as part of the training set have human-verified image-level labels. Most verifications were done with in-house annotators at Google. A smaller part was done by crowd-sourcing from Image Labeler: Crowdsource app, g.co/imagelabeler. This verification process practically eliminates false positives (but not false negatives: some labels might be missing from an image). The resulting labels are largely correct and we recommend to use these for training computer vision models. Multiple computer vision models were used to generate the samples (not just the one used for the machine-generated labels) which is why the vocabulary is significantly expanded (#classes column in Table 1).
As a result of our annotation process, each image is annotated both with verified positive image-level labels, indicating some object classes are present, and with verified negative image-level labels, indicating some classes are absent. All other classes which are not explicitly marked as positive or negative for an image are not annotated. The verified negative labels are reliable and can be used during training and evaluation of image classifiers.
Overall, there are 19,949 distinct classes with image-level labels. Note that this number is slightly higher than the number of human-verified labels in Table 1. The reason is that there are a small number of labels in the machine-generated set that do not appear in the human-verified set. Trainable classes are those with at least 100 positive human-verifications in the V5 training set. Based on this definition, 8,658 classes are considered trainable and machine-generated labels cover 8,386 of these.
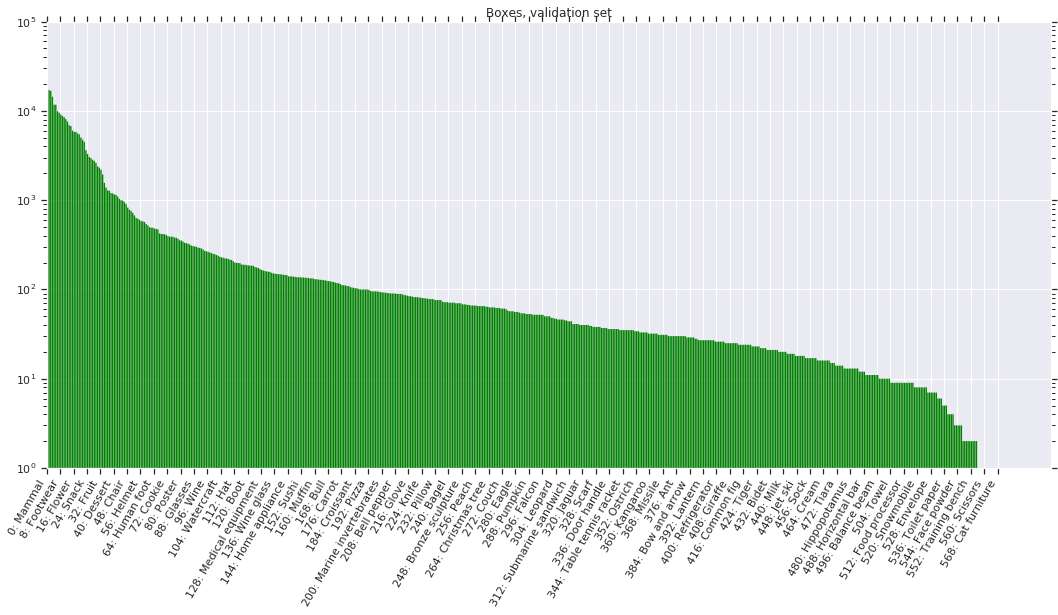
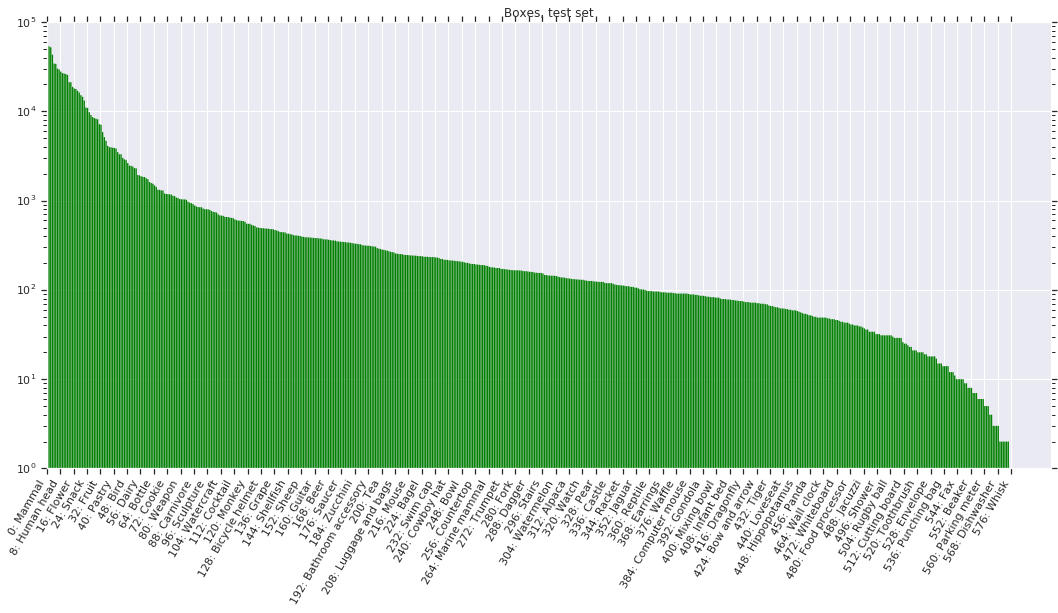
Bounding boxes
Table 2 shows an overview of the bounding box annotations in all splits of the dataset, which span 600 object classes. These offer a broader range than those in the ILSVRC and COCO detection challenges, including new objects such as "fedora" and "snowman".
Table 2: Boxes.
| Train | Validation | Test | # Classes | |
|---|---|---|---|---|
| Images | 1,743,042 | 41,620 | 125,436 | - |
| Boxes | 14,610,229 | 303,980 | 937,327 | 600 |
For the training set, we annotated boxes in 1.74M images, for the available positive human-verified image-level labels. We focused on the most specific labels. For example, if an image has labels {car, limousine, screwdriver}, we annotated boxes for limousine and screwdriver. For each positive label in an image, we exhaustively annotated every instance of that object class in the image (but see below for group cases). We provide 14.6M bounding boxes. On average there are 8.4 boxed objects per image. 90% of the boxes were manually drawn by professional annotators at Google using the efficient extreme clicking interface [1]. We produced the remaining 10% semi-automatically using an enhanced version of the method in [2]. These boxes have been human verified to have IoU>0.7 with a perfect box on the object, and in practice they are accurate (mean IoU ~0.77, see Sect. 4.2 of [3]). We have drawn bounding boxes for human body parts and the class "Mammal" only for 95,335 images, due to the overwhelming number of instances (1,327,596 on the 95,335 images). This list of images enables using the data correctly during training of object detectors (as there might be a positive image label for a human body part, and yet no boxes). Finally, we drew a single box around groups of objects (e.g., a bed of flowers or a crowd of people) if they had more than 5 instances which were heavily occluding each other and were physically touching (we marked these boxes with the attribute "group-of").
For the validation and test sets, we provide exhaustive box annotation for all object instances, for all available positive image-level labels (again, except for "groups-of"). All boxes were manually drawn. We deliberately tried to annotate boxes at the most specific level in our semantic hierarchy as possible. On average, there are 7.4 boxes per image in the validation and test sets. For Open Images V5, we improved the annotation density, which now comes close to the density in the training set. This ensures more precise evaluation of object detection models. In contrast to the training set, on the validation and test sets we annotated human body parts on all images for which we have a positive label.
We emphasize that the images are annotated both human-verified positive and negative labels (see section above). Importantly, the negative image-level labels can be used during training of object detectors, e.g. for hard-negative mining. Moreover, they can also be used during evaluation, as detections of a class annotated as negative (absent) in the ground-truth can be reliably counted as false-positives. In our Open Images Challenge website we present an evaluation metric that fully uses the image-level labels to fairly evaluate detection models.
In all splits (train, val, test), annotators also marked a set of attributes for each box, e.g. indicating whether that object is occluded (see the full description in the download section).
Object segmentations
Table 3 shows an overview of the object segmentation annotations in all splits of the dataset. These annotations cover a subset of 350 classes from the 600 boxed classes. These offer a broader range of categories than Cityscapes or COCO, and cover more images and instances than ADE20k. The segmentations spread over a subset of the images with bounding boxes (Table 2).
Table 3: Instance segmentation masks.
| Train | Validation | Test | # Classes | |
|---|---|---|---|---|
| Images | 944,037 | 13,524 | 40,386 | - |
| Instance masks | 2,686,666 | 24,730 | 74,102 | 350 |
For the training set we annotated 2.7M instance masks, starting from the available bounding boxes. The masks cover 350 classes and are spread over 944k images. On average there are 2.8 segmented instances per image. The segmentation masks on the training set have been produced by a state-of-the-art interactive segmentation process [4], where professional human annotators iteratively correct the output of a segmentation neural network. This is more efficient than manual drawing alone, while at the same time delivering accurate masks (mIoU 84% [4]).
We selected the 350 classes to annotate with segmentation masks based on the following criteria: (1) whether the class exhibits one coherent appearance over which a policy could be defined (e.g. "hiking equipment" is rather ill-defined); (2) whether a clear annotation policy can be defined (e.g. which pixels belong to a nose?); and (3) whether we expect current segmentation neural networks to be able to capture the shape of the class adequately (e.g. jellyfish contains thin structures that are hard for state-of-the-art models). We have put particular effort into ensuring consistent annotations across different objects (e.g., all cat masks include their tail; bags carried by camels or persons, are included in their mask).
We annotated all boxed instances of these 350 classes on the training split that fulfill the following criteria: (1) the object size is larger than 40x80 or 80x40 pixels; (2) the object boundaries can be confidently determined by the annotator (e.g. blurry or very dark instances are skipped); (3) the bounding-box contains a single real object (i.e. does not have any of the IsGroupOf, IsDepiction, IsInside attributes). A few of the 350 classes have a disproportionately large number of instances. To better spread the annotation effort we capped four categories: "clothing" to 441k instances, "person" to 149k, "woman" to 117k, "man" to 114k. In total we annotated segmentation masks for 769k instances of "person"+"man"+"woman"+"boy"+"girl"+"human body". All other classes are annotated without caps, using only the two criteria above.
For the validation and test splits we created 99k masks spread over 54k images. These have been annotated with a purely manual free-painting tool and with a strong focus on quality. They are near-perfect (self-consistency 90% mIoU [4]) and capture even fine details of complex object boundaries (e.g. spiky flowers and thin structures in man-made objects). For the validation and test splits we limited these annotation to a maximum of 600 instances per class (per split), and applied the same instance selection criteria as in the training split (minimal size, unambiguous boundary, single real object). On average over all instances, both our training and validation+test annotations offer more accurate object boundaries than the polygon annotations provided by most existing datasets [4].
Please note that instances without a mask remain covered by their corresponding bounding boxes, and thus can be appropriately handled during training and evaluation of segmentation models.
We emphasize that the images are annotated both human-verified positive and negative labels. The negative image-level labels can be used during training of segmentation models, e.g. for hard-negative mining. Moreover, they can also be used during evaluation, as we do for the Open Images Challenge.
Visual relationships
Table 4 shows an overview of the visual relationship annotations in the train split of the dataset.
Table 4: Relationships.
| Train | Validation | Test | # Distinct relationship triplets | # Classes | # Attributes | |
|---|---|---|---|---|---|---|
| Relationship triplets | 374,768 | 3,991 | 12,314 | 329 obj-obj: 287 attr: 42 |
57 | 5 |
For the training set, we annotated all images already containing bounding box annotations with visual relationships between objects and for some objects we annotated visual attributes (encoded as "is" relationship).
In our notation, a pair of objects connected by a relationship forms a triplet (e.g. "beer on table"). Visual attributes are also represented as triplets, where an object in connected with an attribute using the relationship is (e.g. "table is wooden", "handbag is made of leather" or "bench is wooden"). We initially selected 467 possible triplets based on existing bounding box annotations. The 329 of them that have at least one instance in the training split form the final set of visual relationships/attributes triplets. In total, we annotated 375K instances of these triplets on the training split, involving 57 different object classes and 5 attributes. These include both human-object relationships (e.g. "woman playing guitar", "man holding microphone") and object-object relationships (e.g. "beer on table", "dog inside car").
Annotations are exhaustive, meaning that for each image that can potentially contain a relationship triplet (i.e. contains the objects involved in that triplet), we provide annotations exhaustively listing all positive triplets instances in that image. For example, for "woman playing guitar" in an image, we list all pairs of ("woman","guitar") that are in the relationship "playing" in that image. All other pairs of (woman,guitar) in that image are reliable negative examples for the "playing" relationship.
For Open Images V5, we added relationship annotations on the validation and test spits, generated in the same manner as for the training split. These cover the same 329 relationship triplets, with 3,991 instances on the validation split and 12,314 on the test split. In total over all splits, for the 57 object classes with 391k relationship annotations.
We emphasize that the images are annotated both human-verified positive and negative labels (see section above). Importantly, the negative image-level labels can be used during training of visual relationship detectors: if any of the two object classes in a relationship triplet is marked as a negative label in our ground-truth, then all detections of that triplet are false-positives. The same can be done during evaluation, as we did for our official Open Images Challenge metric.
Class definitions
Classes are identified by MIDs (Machine-generated Ids) as can be found in Freebase or Google Knowledge Graph API. A short description of each class is available in class-descriptions.csv.
Statistics and data analysis
Hierarchy for the 600 boxable classes
View the set of boxable classes as a hierarchy here or download it as a JSON file:

Label distributions
The following figures show the distribution of annotations across the dataset. Notice that the label distribution is heavily skewed (note: the y-axis is on a log-scale). Classes are ordered by number of positive samples. Green indicates positive samples while red indicates negatives.
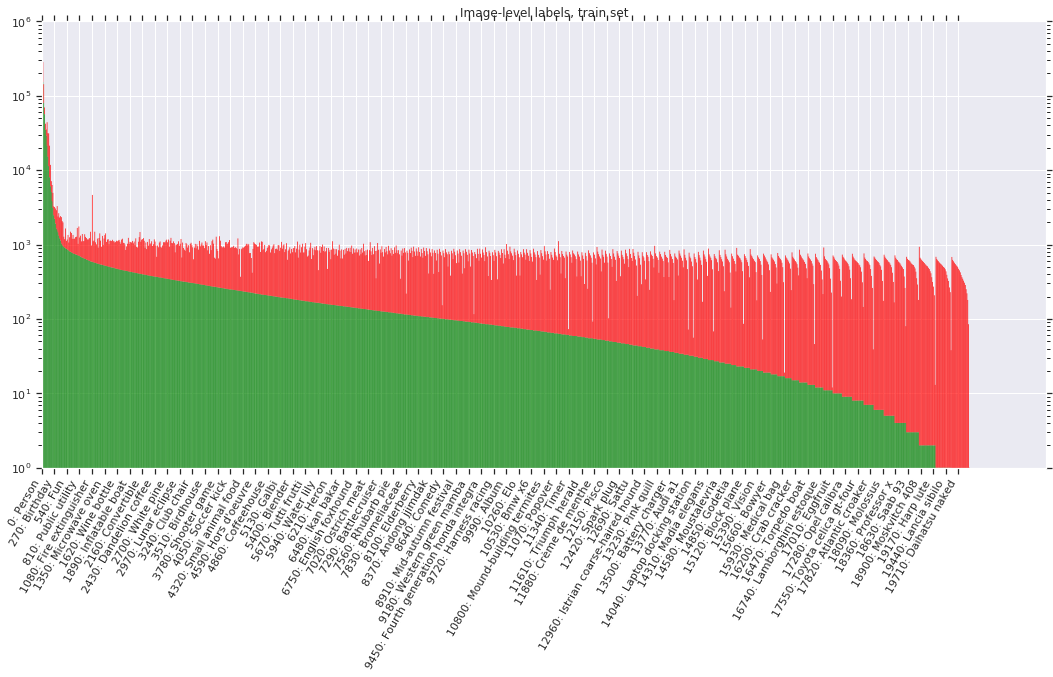
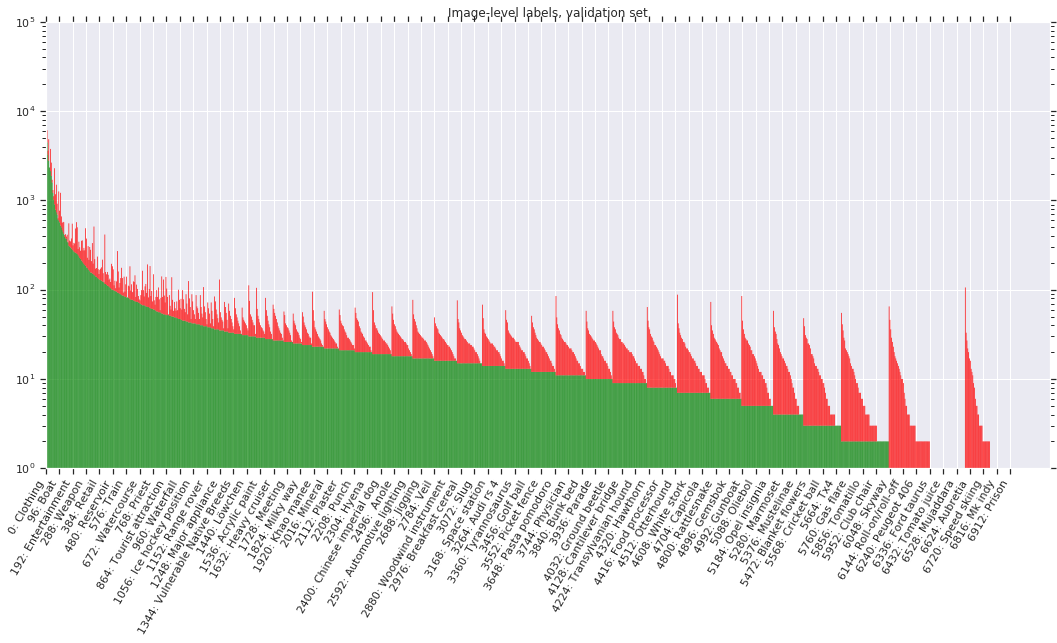
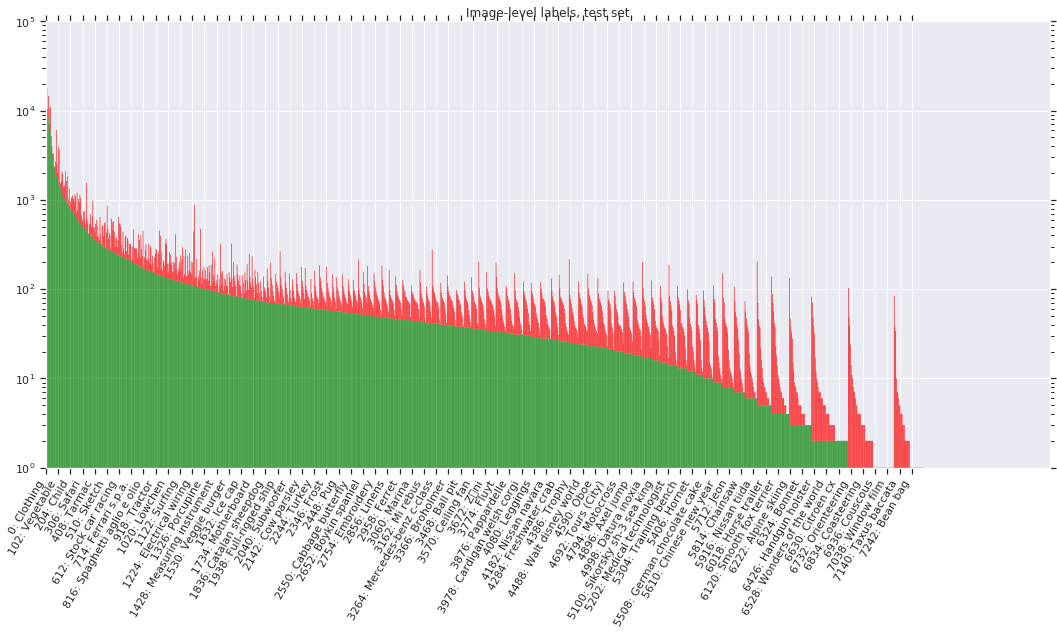
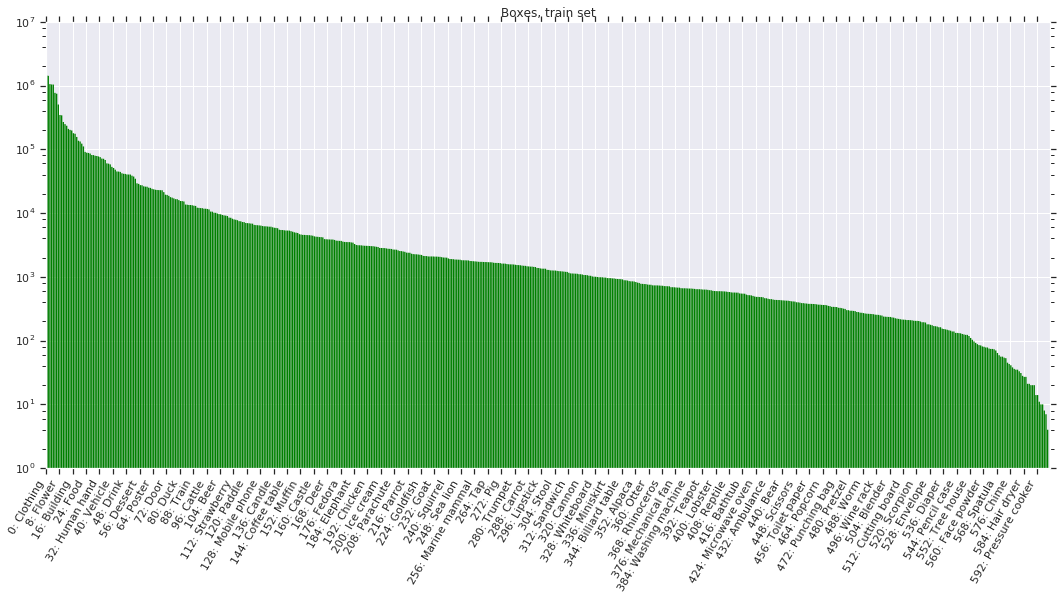
Licenses
The annotations are licensed by Google LLC under CC BY 4.0 license. The images are listed as having a CC BY 2.0 license. Note: while we tried to identify images that are licensed under a Creative Commons Attribution license, we make no representations or warranties regarding the license status of each image and you should verify the license for each image yourself.
References
-
"Extreme clicking for efficient object annotation", Papadopolous et al., ICCV 2017.
-
"We don't need no bounding-boxes: Training object class detectors using only human verification", Papadopolous et al., CVPR 2016.
-
"The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale", Kuznetsova et al., arXiv:1811.00982 2018.
-
"Large-scale interactive object segmentation with human annotators", Benenson et al., CVPR 2019.